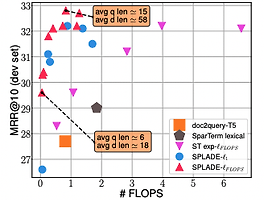
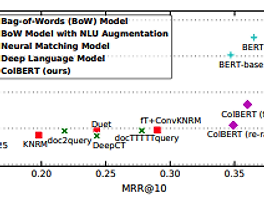
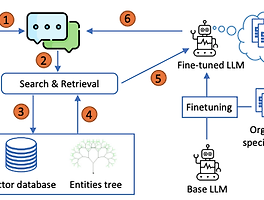
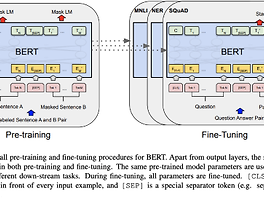
세계정복의주인장 (1145) 썸네일형 리스트형 [논문 리뷰] SPLADE: Sparse Lexical and Expansion Modelfor First Stage Ranking 3줄 요약 SPLADE를 사용하면 fine-tuning 필요 없이 더 빠르고 정확한 검색이 가능합니다. 하지만 기존 성능에 비해 크게 향상은 되지 않고 잘못된 semantic 검색도 야기됩니다. Abstract 문서와 쿼리에 대한 희소 표현을 학습하는 것에 대한 관심이 높아지고 있다. 명시적 희소성 정규화와 용어 가중치에 대한 새로운 랭커를 제시하여 고도로 희소한 표현과 비교하여 경쟁력 있는 결과를 이끌어낼수 있다. introduction SPLADE는 효율적인 문서 확장을 수행하며, 고밀도 모델을 위한 복잡한 훈련 파이프라인에 대해 경쟁력 있는 결과를 보여준다. 희소 정규화를 제어하여 효율성(부동 소수점 연산 횟수)과 효과 사이의 균형에 영향을 줄 수 있는 방법을 보여줍니다. RELATED WORKS .. [논문 리뷰]ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT 요약 re-ranking은 colbert를 사용하자. ABSTRACT 정보검색(IR)에서 문서 랭킹을 위한 언어 모델(LM)은 fine-tuning을 통해 빠르게 성장하고 있다. 더욱 효율적인 검색을 위해 LM(특히, BERT)을 적용하는 새로운 랭킹 모델인 ColBERT를 소개한다. introduction ELMo 및 BERT는 사전 학습된 심층 언어 모델(LM)을 미세 조정하여 관련성을 추정하는 접근 방식이 최근에 등장했다. 하지만 BERT 기반 모델은 이전 모델보다 100-1000배 더 계산 비용이 많이 들며, 일부 모델 또한 저렴하지도 않다 BERT는 검색 정밀도를 크게 개선했지만, GPU를 사용하더라도 지연 시간을 최대 수만 밀리초까지 증가시킨다. 쿼리 응답 시간이 100밀리초만 증가해도 사용자.. [논문 리뷰] T-RAG: LESSONS FROM THE LLM TRENCHES https://arxiv.org/pdf/2402.07483.pdf 요약 해당 문서에는 전반적인 RAG설명과 함께 Tree를 이용한 계층적 엔티티를 사용하면 기존 RAG보자 성능을 향상 시킬수 있습니다. 단 기존 RAG와 마찬가지로 리트리버 쿼리의 질문이 중요하며, Tree 구조를 쓸 수 있을때에만 효과를 발휘할수 있습니다. ( 엔티티의 데이터가 필요 없는 질문에 사용하면 오히려 데이터의 정답율이 하락합니다) Abstract 대규모 언어 모델(LLM)은 놀라운 언어 기능을 보여주며 다양한 영역의 애플리케이션에 통합하려 시도하고 있습니다. 검색 증강 세대(RAG)는 LLM 기반 애플리케이션을 구축하기 접합한 프레임워크로 부상했습니다. RAG를 구축하는 것은 비교적 간단하지만, 견고하고 안정적인 애플리케이션을.. [사내 해커톤] ocr + gpt를 이용한 식품 성분 분석 및 추천 * 상품 점보를 사진을 업로드 하면 자동으로 텍스트로 변환하여 상품에 대한 정보 요약 * 제품명 / 제조회사 / 제품유형 / 맛 / 용량 / 원료 / 칼로리 / 영양정보 로 추려서 보여줌 * 사용자의 상태를 선택하여 입력하면 섭취 권장 여부 및 이유를 고객에게 요약 후 보여줌 팀으로 이뤄서 한 해커톤 결과물 - 역시 프롬프트는 영어로 하니까 잘된다. - OCR은 네이버 클로바를 썼다. 정말 잘된다!! (하지만 하루 100건 무료를 넘어서면 엄청난 과금이 기다리고 있다) - streamlit은 이번에 처음 써봤는데, 다시는 쓰기 싫을 정도로 너무 제한적이다. (공식 문서도 부족하고, 버전마다 기능이 너무 다르다. html이 쉽고 좋다) 향후 발전해야 할 부분들 - 상황에 맞는 프롬프트가 많이 있어야 한다... [논문리뷰] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding https://arxiv.org/abs/1810.04805 요약 : bert는 성능도 우수합니다! - 충분한 데이터만 있다면요 Abstract - 양방향 인코더 - 트랜스포머와 달리 BERT는 레이블이 없는 텍스트의 양방향 표현을 사전 학습하도록 설계되었습니다 - 레이블이 없는 텍스트에 대해 컨디셔닝하여 모든 레이어에서 왼쪽과 오른쪽 컨텍스트를 학습한다. 그 결과, pre-trained BERT 모델은 단 하나의 추가 출력 레이어만으로 미세 조정할 수 있습니다. 1. Introduction - pre-training 언어모델은 많은 자연어 처리 task의 향상에 좋은 성능을 발휘하고 있습니다. - downstream task를 위해 pre-trainedfmf 학습하는 방식에는 두가지 방법이 있다 1. f.. MS와 인터뷰 내용 https://customers.microsoft.com/en-us/story/614ec39d-e04a-4b49-ac53-c3186b6895cf?preview=1 Microsoft Customer Stories customers.microsoft.com 얼마전에 MS측과 대략 2시간정도 인터뷰를 했었다. MS측에서는 우리 회사에서 사용한 MS 관련 제품들 소개를 위한 인터뷰였지만, 나의 경우는 최대한 내가 개발한 프로젝트에 대한 홍보 및 MLops에 대한 소개를 중심으로 인터뷰를 했다. MLops단에서는 MS제품을 사용을 안해서 그런지 내용 대부분이 짤렸다. CI/CD 부분만 기사에 실렸다. 개발도 중요하지만, 홍보도 도움이 된다고 생각한다. 그동안 개발 했던 내용 정리와 함께 다른 사람에게 우리 서비스.. [system design] 이벤트 추천 시스템 1. 목표 - 사용자에게 개인화된 이벤트 목록을 표시하는 이벤트 추천 시스템을 설계 - 이벤트 : 이벤트 설명 / 가격 / 위치 / 날짜 / 시작과 종료가 있는 기간 으로 구성됨 - 다른 사용자를 이벤트에 초대하고 친구 관계를 형성 할 수 있다. - 주요 목표는 사용자에게 개인화된 이벤트 목록을 표시하는 이벤트 추천 시스템을 설계해야 한다. 이벤트의 정의는 일반 사이트의 특정 상품 / 특정 회사 제품에 대한 이벤트 일수도 / 게임 상점에서의 아이템 판매에 대한 이벤트등 다양한 계열을 볼수 있다. 일반적으로 표현하자면 특정한 기간안에 특정한 상품을 판매하는 행위로 정의할수 있다. 2. 랭킹 모델 LTR(Learning to Rank)는 지도 학습을 적용하여 순위 문제를 해결하는 알고리즘 기법의 하나로, '.. [system design] 이미지 검색 서비스 1. 요구사항 - 플랫폼에 1000억개의 이미지가 있다. 사용자가 이미지를 업로드하면 가장 유사한 이미지들을 검색해야 한다. - 이미지에는 메타데이터가 없으며, 오직 픽셀 데이터만 사용해야 한다. 2. 문제 구조화 먼저 쿼리에 해당하는 입력값은 이미지다. 사용자는 이미지를 입력하면 출력으로 이미지 리스트가 나와야 한다. 출력되는 이미지들은 쿼리 이미지와 유사한 이미지 세트를 출력한다. 먼저 해당 이미지들에 대한 분류(classification)가 되어야 한다. 특정 사물에 대한 분류를 통한 출력 세트를 만들수 있다. 혹은 특정 유사도를 통해서도 분류를 할 수 있다. 개와 고양이의 분류가 물체에 대한 인식이라면, 유사도는 비슷한 모든것을 지칭할수 있다. 표현학습은 이미지와 같은 입력 데이터를 임베딩이라는 .. 이전 1 2 3 4 ··· 144 다음