해당 글은 http://www.laurentluce.com/posts/python-string-objects-implementation/ 의 글을 번역한 것입니다.
해당 글의 소스는 python2를 기준으로 작성되었으며 python버전에 따라 다를 수 있습니다.
PyStringObject 구조
파이썬의 string object는 PyStringObject 구조로 표현됩니다. “ob_shash”는 해쉬로 계산된 값입니다. “ob_sval"는 String의 사이즈인 “ob_size”를 포함 합니다. 문자열은 null로 종료됩니다. ob_sval의 초기 사이즈는 1byte이며, ob_sval[0] = 0이 됩니다.
python3의 경우 PyUnicodeObject 구조로 표현됩니다.
# python2
typedef struct {
PyObject_VAR_HEAD
long ob_shash;
int ob_sstate;
char ob_sval[1];
} PyStringObject;
# python3
typedef struct {
PyCompactUnicodeObject _base;
union {
void *any;
Py_UCS1 *latin1;
Py_UCS2 *ucs2;
Py_UCS4 *ucs4;
} data;
} PyUnicodeObject;
새로운 문자열 객체
만일 이와 같은 변수로 새로운 문자열을 할당하면 어떻게 될까요?
>>> s1 = 'abc'
내부 C 함수 "PyString_FromString"이 호출되고 의사 코드는 다음과 같습니다.
arguments: string object: 'abc'
returns: Python string object with ob_sval = 'abc'
PyString_FromString(string):
size = length of string
allocate string object + size for 'abc'. ob_sval will be of size: size + 1
copy string to ob_sval
return object새로운 문자열이 사용될 때마다 새로운 문자열 객체가 할당됩니다.
문자열 객체 공유
작은 문자열이 변수간에 공유되는 기능으로 메모리 사용을 감소시킵니다. 작은 문자열은 크기가 0 또는 1 바이트 인 문자열입니다. 전역 변수 "interned"는 작은 문자열을 참조하는 사전입니다. "문자"배열은 길이가 1 바이트 인 문자열, 즉 단일 문자를 참조하는 데에도 사용됩니다.
static PyStringObject *characters[UCHAR_MAX + 1];
static PyObject *interned;변수에 새 작은 문자열이 할당되면 어떻게되는지 봅시다.
>>> s2 = 'a'
'a'를 포함하는 문자열 객체는“interned”사전에 추가됩니다. 키는 문자열 객체에 대한 포인터이며 값은 동일한 포인터입니다. ASCII에서 'a'의 값이 97이므로 새 문자열 객체는 오프셋 97의 배열 문자에서도 참조됩니다. 변수 "s2”가 이 문자열 객체를 가리키고 있습니다.

다른 변수가 동일한 문자열 'a'에 할당되면 어떻게 될까요?
>>> s3 = 'a'이전에 생성된 동일한 문자열 객체가 반환되므로 두 변수가 모두 동일한 문자열 객체를 가리킵니다. “문자" 배열은 해당 프로세스 중에 문자열이 이미 있는지 확인하고 문자열 객체에 대한 포인터를 반환합니다.
if (size == 1 && (op = characters[*str & UCHAR_MAX]) != NULL)
{
...
return (PyObject *)op;
}
문자 ‘c’로 새로운 문자열을 만들어 봅시다.
>>> s4 = 'c'
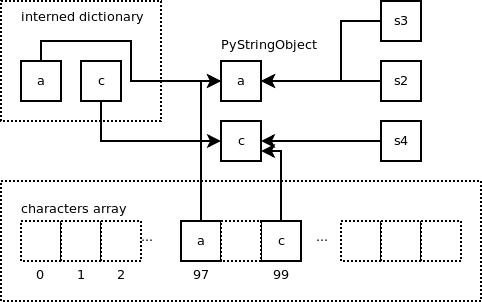
다음과 같이 문자열 항목이 요청 될 때 사용 중인 "문자"배열을 찾습니다.
>>> s5 = 'abc'
>>> s5[0]
'a''a'를 포함하는 새 문자열을 만드는 대신 "문자"배열의 오프셋 97에 있는 포인터가 반환됩니다. 다음은 문자열에서 문자를 요청할 때 호출되는 “string_item”함수의 코드입니다. "a"인수는 'abc'를 포함하는 문자열 객체이고 “i" 파라미터는 요청 된 인덱스입니다. 이 경우 인덱스는 0입니다. 문자열 객체에 대한 포인터가 반환됩니다.
static PyObject *
string_item(PyStringObject *a, register Py_ssize_t i)
{
char pchar;
PyObject *v;
...
pchar = a->ob_sval[i];
v = (PyObject *)characters[pchar & UCHAR_MAX];
if (v == NULL)
// allocate string
else {
...
Py_INCREF(v);
}
return v;
}
"문자"배열은 길이가 1 인 함수 이름에도 사용됩니다.
>>> def a(): pass
문자열 검색
문자열 검색을 수행 할 때 어떤 일이 발생하는지 살펴보겠습니다.
>>> s = 'adcabcdbdabcabd'
>>> s.find('abcab')
>>> 11
"find"함수는 문자열 "s"에서 문자열 ‘abcd’가 위치한 인덱스를 반환합니다. 문자열을 찾지 못하면 -1을 반환합니다.
내부적으로 fastsearch가 호출됩니다. Boyer-Moore와 Horspool 알고리즘과 몇 가지 깔끔한 트릭이 혼합되어 있습니다.
원본 문자열을 "s”라 하고 검색할 문자열을 "p”라고 합시다. (S 문자열에서 p 문자열을 검색)
s = ‘adcabcdbdabcabd’ , p = 'abcab'입니다.
"n"은 "s"의 길이이고 "m"은 "p"의 길이입니다. n = 18 및 m = 5
먼저 m> n이면 다음 코드에서 볼 수 있듯이 인덱스를 찾을 수 없으므로 함수가 -1을 즉시 반환합니다.
w = n - m;
if (w < 0)
return -1;m = 1 인 경우 코드는 한 번에 한 문자 씩 "s"를 통과하고 일치하는 경우 인덱스를 반환합니다. mode = FAST_SEARCH에서 문자열이 처음 발견되는 색인을 찾고 문자열이 발견된 횟수가 아닌 색인을 찾습니다.
if (m <= 1) {
...
if (mode == FAST_COUNT) {
...
} else {
for (i = 0; i < n; i++)
if (s[i] == p[0])
return i;
}
return -1;
}
다른 경우인 m> 1입니다.
첫 번째 단계는 압축된 boyer-moore delta 1 테이블을 작성하는 것입니다. 이 단계에서 "mask"및 “skip"라는 두 가지 변수가 할당됩니다.
"mask"는 32 비트의 비트 마스크이며, 문자의 최하위 5 비트를 키로 사용합니다. 여기에서는 문자열 “p”를 검색하여 생성됩니다. 이 문자열에 문자가 있는지 bloom filter로 확인합니다. 정말 빠르지만 오 탐지가 있습니다. 블룸 필터에 대한 자세한 내용은 여기를 참조하십시오. 아래는 비트 마스크가 생성되는 방식입니다.
mlast = m - 1
/* process pattern[:-1] */
for (mask = i = 0; i < mlast; i++) {
mask |= (1 << (p[i] & 0x1F));
}
/* process pattern[-1] outside the loop */
mask |= (1 << (p[mlast] & 0x1F));s = ‘adcabcdbdabcabd’ , p = 'abcab'
"p"의 첫 문자는 'a'입니다. 'a'의 값은 이진 형식의 97 = 1100001입니다. 5개의 최하위 비트를 사용하면 00001을 얻게 되므로 "mask"는 00001 << 1 = 10으로 설정됩니다. 문자열 “p”의 첫 번째 ‘a' 처리되면 mask = 1110입니다. (1100001에서 하위 5개 비트가 10이 되므로 1110이 됩니다.)
아래의 코드에서 c는 현재 가리키는 문자, ‘a’가 됩니다.
if ((mask & (1 << (c & 0x1F))))
"p"에서 'a'가 p = 'abcab'에 있을까요? 1110 & (1 << ( 'a' & 0X1F)) 가 되어 결국 1110 & (1 << ( 'a'& 0X1F)) = 1110 & 10 = 10.
따라서 'a'는 'abcab'에 있습니다. 'd'로 테스트하면 false가 되고 'e'에서 'z'까지의 문자로 이 필터는 아주 잘 작동합니다. "건너뛰기" 검색할 문자열의 마지막 문자와 동일한 값을 가진 문자의 색인으로 설정됩니다. 마지막 문자를 찾을 수 없으면 "skip"은 "p"-1의 길이로 설정됩니다. 검색 할 문자열의 마지막 문자는 'b'입니다. 이는 "skip"이 2로 설정됨을 의미합니다. 이 문자는 2자를 넘어서서도 찾을 수 있기 때문입니다. 이 변수는 잘못된 문자 건너뛰기 방법이라는 건너 뛰기 방법에 사용됩니다. 다음 예에서 p = 'abcab'및 s = 'adcabcaba'. 검색은 "s"의 인덱스 4에서 시작하여 문자열 일치가 있는지 역방향으로 검사합니다. 이 첫 번째 테스트는 인덱스 = 1에서 실패합니다. 여기서 'b'는 'd'와 다릅니다. "p"의 문자 'b'는 끝에서부터 3 문자 아래로 발견된다는 것을 알고 있습니다. 'c'때문에 "p"의 일부인 경우 다음 'b'로 건너뜁니다. 이것은 잘못된 문자 건너뛰기입니다

다음은 검색 루프 자체입니다 (실제 코드는 Python 대신 C입니다).
for i = 0 to n - m = 13:
if s[i+m-1] == p[m-1]:
if s[i:i+mlast] == p[0:mlast]:
return i
if s[i+m] not in p:
i += m
else:
i += skip
else:
if s[i+m] not in p:
i += m
return -1비트 마스크를 사용하여 “s [i + m] not p”테스트가 수행됩니다. “i + = skip”은 잘못된 문자 건너뛰기입니다. "p"에서 다음 문자를 찾을 수 없으면 "i + = m"이 수행됩니다.
이 검색 알고리즘이 문자열 "p"및 "s"와 어떻게 작동하는지 봅시다. 처음 3 단계는 익숙합니다. 그 후, 문자 'd'는 문자열“p”에 있지 않으므로 “p”의 길이를 건너뛰고 그 이후에 빠르게 일치하는 것을 찾습니다.

http://svn.python.org/projects/python/trunk/Objects/stringobject.c 에서 문자열 객체의 코드를 살펴볼 수 있습니다.
'app > python' 카테고리의 다른 글
| Python dictionary implementation (1) | 2020.03.21 |
|---|---|
| python list implementation (0) | 2020.03.20 |
| Python integer objects implementation (0) | 2020.03.18 |
| python hash && cache (0) | 2020.03.11 |
| python에서 pow(n, n) 와 n**n 중 어느게 빠를까? (1) | 2020.03.07 |



