해당 글은 http://guilload.com/python-string-interning/ 를 번역한 글입니다.
해당 글은 Python 2.7.7 버전에서의 인 터닝에 대한 글입니다. 파이썬 버전에 따라 차이가 있을 수 있습니다.
파이썬 최신 버전에 대한 이야기는 https://nephtyws.github.io/python/interning/ 를 보시면 됩니다.
며칠 전 동료에게 내장 함수 intern의 기능을 설명해야 했습니다.
>>> s1 = 'foo!'
>>> s2 = 'foo!'
>>> s1 is s2
False
>>> s1 = intern('foo!')
>>> s1
'foo!'
>>> s2 = intern('foo!')
>>> s1 is s2
True이것은 내부적으로 어떻게 동작할까요?
PyStringObject 구조
cpython의 stringobject.h에 PyStringObject의 선언이 있습니다. ( https://hg.python.org/releasing/2.7.9/file/753a8f457ddc/Include/stringobject.h#l35 )
typedef struct {
PyObject_VAR_HEAD
long ob_shash;
int ob_sstate;
char ob_sval[1];
/* Invariants:
* ob_sval contains space for 'ob_size+1' elements.
* ob_sval[ob_size] == 0.
* ob_shash is the hash of the string or -1 if not computed yet.
* ob_sstate != 0 iff the string object is in stringobject.c's
* 'interned' dictionary; in this case the two references
* from 'interned' to this object are *not counted* in ob_refcnt.
*/
} PyStringObject;
주석에 따르면 ob_sstate는 문자열이 할당되는 경우 0이 아니게 됩니다. 이 변수는 직접 접근할 수 없고, PyString_CHECK_INTERNED를 통해 접근이 가능합니다.
#define PyString_CHECK_INTERNED(op) (((PyStringObject *)(op))->ob_sstate)
Interned dictionary
Stringobject.c에서 interned는 문자열이 저장 될 객체에 대한 참조를 선언합니다. (https://hg.python.org/releasing/2.7.9/file/753a8f457ddc/Objects/stringobject.c#l24)
static PyObject *interned;이 객체는 파이썬 dictionary 이며 다음과 같이 초기화됩니다.
interned = PyDict_New();그리고 실제 구현 PyStirng_InternInPlace에서 구현됩니다.
PyString_InternInPlace(PyObject **p)
{
register PyStringObject *s = (PyStringObject *)(*p);
PyObject *t;
if (s == NULL || !PyString_Check(s))
Py_FatalError("PyString_InternInPlace: strings only please!");
if (!PyString_CheckExact(s))
return;
if (PyString_CHECK_INTERNED(s))
return;
if (interned == NULL) {
interned = PyDict_New();
if (interned == NULL) {
PyErr_Clear(); /* Do not leave an exception */
return;
}
}
t = PyDict_GetItem(interned, (PyObject *)s);
if (t) {
Py_INCREF(t);
Py_DECREF(*p);
*p = t;
return;
}
if (PyDict_SetItem(interned, (PyObject *)s, (PyObject *)s) < 0) {
PyErr_Clear();
return;
}
Py_REFCNT(s) -= 2;
PyString_CHECK_INTERNED(s) = SSTATE_INTERNED_MORTAL;
}
Intern dictionary의 키는 문자열 객체 포인터 이며, 값 또한 동일합니다.
intern의 의사 코드는 다음과 같습니다.
interned = None
def intern(string):
if string is None or not type(string) is str:
raise TypeError
if string.is_interned:
return string
if interned is None:
global interned
interned = {}
t = interned.get(string)
if t is not None:
return t
interned[string] = string
string.is_interned = True
return string
Interning string의 장점
객체 공유
intern을 하면 문자열 객체를 공유하여 메모리 양이 줄어듭니다.
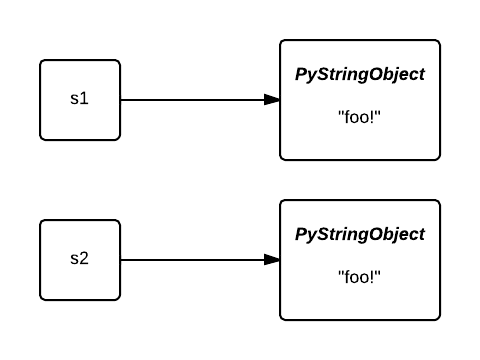
S1과 S2 두 개의 다른 객체가 생성되었습니다.
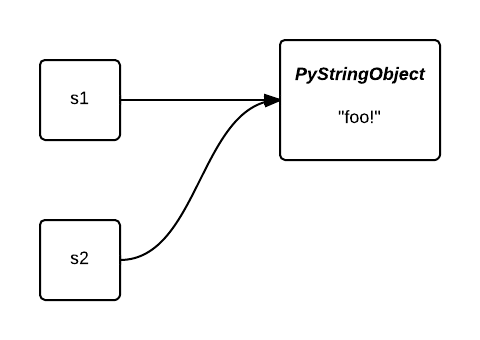
Intern 후에는 동일한 객체를 가리킵니다.
엔트로피가 낮은 목록을 처리할때 ( 질서 정연한 데이터 ) interning이 적합합니다. 예를 들어 말뭉치를 토큰화 할 때 단어 빈도의 분포를 interning에 사용할 수 있습니다.
다음 예제는 Shakespeare의 Hamlet을 NLTK로 분석하여 interning한 결과입니다.
import guppy
import nltk
hp = guppy.hpy()
hp.setrelheap()
hamlet = nltk.corpus.shakespeare.words('hamlet.xml')
print hp.heap()
hamlet = [intern(wrd) for wrd in nltk.corpus.shakespeare.words('hamlet.xml')]
print hp.heap()
$ python intern.py
Partition of a set of 31187 objects. Total size = 1725752 bytes.
Index Count % Size % Cumulative % Kind (class / dict of class)
0 31166 100 1394864 81 1394864 81 str
...
Partition of a set of 4555 objects. Total size = 547840 bytes.
Index Count % Size % Cumulative % Kind (class / dict of class)
0 4 0 328224 60 328224 60 list
1 4529 99 215776 39 544000 99 str
...
결과에서 알수 있듯이 string의 선언이 31187에서 4555로 대폭 줄어들었으며 메모리는 6.5배나 차이가 납니다.
포인트 비교
문자열의 비교시 O (n) 바이트 당 바이트 비교 대신 O (1) 포인터 비교 할 수 있습니다.
이를 증명하기 위해, 두 문자열의 길이가 서로 맞지 않을 때와 길이에 따라 두 문자열의 동등성을 확인하는 데 필요한 시간을 측정했습니다
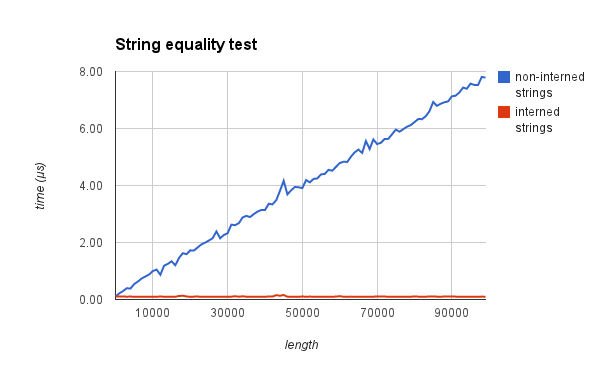
Native Interning
특정 조건에서 문자열은 기본적으로 intern 됩니다. 첫 번째 예제에서 foo! 대신 foo를 선언하면 자동으로 interning 됩니다.
>>> s1 = 'foo'
>>> s2 = 'foo'
>>> s1 is s2
TrueInterned or not Interned?
이 포스팅을 쓰기 전엔 문자열의 길이와 문자열을 구성하는 문자를 고려하여 문자열에 따라 기본적으로 interning이 된다고 생각했습니다. 하지만 문자열의 길이에 대해선 딱히 규칙을 추론할 수 없었습니다.
>>> 'foo' is 'foo'
True
>>> 'foo!' is 'foo!'
False
>>> 'foo' + 'bar' is 'foobar'
True
>>> ''.join(['f']) is ''.join(['f'])
True
>>> ''.join(['f', 'o', 'o']) is ''.join(['f', 'o', 'o'])
False
>>> 'a' * 20 is 'aaaaaaaaaaaaaaaaaaaa'
True
>>> 'a' * 21 is 'aaaaaaaaaaaaaaaaaaaaa'
False
>>> 'foooooooooooooooooooooooooooooo' is 'foooooooooooooooooooooooooooooo'
True
모든 길이 0 및 1 문자열도 삽입됩니다.
stringobject.c에서 이번에는 다음 함수 PyString_FromStringAndSize()와 PyString_FromString()의 함수에서 다음을 볼 수 있습니다.
/* share short strings */
if (size == 0) {
PyObject *t = (PyObject *)op;
PyString_InternInPlace(&t);
op = (PyStringObject *)t;
nullstring = op;
Py_INCREF(op);
} else if (size == 1 && str != NULL) {
PyObject *t = (PyObject *)op;
PyString_InternInPlace(&t);길이가 0과 1인 문자열도 모두 interning 됩니다.
컴파일 타임에 문자열이 삽입됩니다
Python 코드는 직접 해석되지 않으며 바이트 코드라는 중간 언어를 생성하는 클래식 컴파일 체인을 거칩니다. 파이썬 바이트 코드는 가상 머신에 의해 실행되는 명령어 세트입니다 이러한 명령어 목록은 여기 에서 찾을 수 있으며 dis 모듈을 사용하여 특정 기능 또는 모듈에 의해 실행되는 명령어를 찾을 수 있습니다.
>>> import dis
>>> def foo():
... print 'foo!'
...
>>> dis.dis(foo)
2 0 LOAD_CONST 1 ('foo!')
3 PRINT_ITEM
4 PRINT_NEWLINE
5 LOAD_CONST 0 (None)
8 RETURN_VALUE
파이썬에서는 모든 것이 객체이고 Code 객체는 바이트 코드 조각을 나타내는 Python 객체입니다. Code 객체는 상수, 변수 이름 등 실행에 필요한 모든 정보와 함께 제공됩니다. CPython에서 Code 객체를 빌드할 때 더 많은 문자열이 삽입됩니다.
PyCodeObject *
PyCode_New(int argcount, int nlocals, int stacksize, int flags,
PyObject *code, PyObject *consts, PyObject *names,
PyObject *varnames, PyObject *freevars, PyObject *cellvars,
PyObject *filename, PyObject *name, int firstlineno,
PyObject *lnotab)
...
/* Intern selected string constants */
for (i = PyTuple_Size(consts); --i >= 0; ) {
PyObject *v = PyTuple_GetItem(consts, i);
if (!PyString_Check(v))
continue;
if (!all_name_chars((unsigned char *)PyString_AS_STRING(v)))
continue;
PyString_InternInPlace(&PyTuple_GET_ITEM(consts, i));
}
codeobject.c (https://hg.python.org/releasing/2.7.9/file/753a8f457ddc/Objects/codeobject.c#l72)에서 튜플은 consts프로그램에 선언할때 부울, 부동 소수점 수, 정수, 문자열 등은 컴파일 시에 정의된 리터럴이 포함되어 있습니다. 튜플에 저장된 문자열은 all_name_chars함수에 의해 필터링되지 않습니다 .
아래 예제 s1에서 컴파일 타임에 선언됩니다. 반대로 s2런타임에 생성됩니다.
s1 = 'foo'
s2 = ''.join(['f', 'o', 'o'])
결과적 s1으로 인턴 s2s2 되지는 않지만 인턴 될 것입니다.
이 함수 all_name_chars는 ASCII 문자, 숫자 또는 밑줄로 구성되지 않은 문자열, 즉 식별자처럼 보이는 문자열을 제외합니다.
#define NAME_CHARS \
"0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefghijklmnopqrstuvwxyz"
/* all_name_chars(s): true iff all chars in s are valid NAME_CHARS */
static int
all_name_chars(unsigned char *s)
{
static char ok_name_char[256];
static unsigned char *name_chars = (unsigned char *)NAME_CHARS;
if (ok_name_char[*name_chars] == 0) {
unsigned char *p;
for (p = name_chars; *p; p++)
ok_name_char[*p] = 1;
}
while (*s) {
if (ok_name_char[*s++] == 0)
return 0;
}
return 1;
}
이러한 모든 설명을 이해했다면 이제 'foo!' is 'foo!'의 값은 False반면 'foo' is 'foo'의 값이 True인 값을 이유를 이해할 수 있습니다.
바이트 코드 최적화는 더 많은 문자열 상수를 생성합니다
아래 예제에서 문자열 연결의 결과는 런타임이 아니라 컴파일 타임에 수행됩니다.
>>> 'foo' + 'bar' is 'foobar'
True그렇기 때문에 ‘foo’+’bar’는 interning 되어 True가 반환됩니다.
소스 코드 컴파일 단계는 첫 번째 버전의 바이트 코드를 생성합니다. 이 "원시"바이트 코드는 마지막으로 "peephole optimization"라는 마지막 컴파일 단계로 들어갑니다.
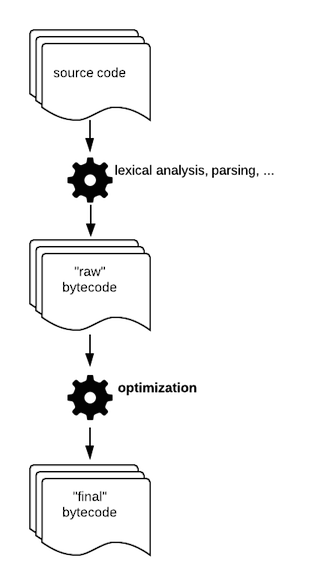
이 단계의 목표는 일부 명령어를 더 빠른 명령어로 대체하여보다 효율적인 바이트 코드를 생성하는 것입니다.
Constant folding
peephole optimization 중에 적용되는 기술 중 하나를 constant folding이라고 하며 상수 표현식을 미리 단순화하는 것으로 구성됩니다.
SECONDS = 24 * 60 * 60컴파일러가 위의 코드를 만난다면, 표현식을 계산된 값을 86400으로 대체할 것입니다. 이것이 바로 'foo' + 'bar'에 일어난 일입니다. foobar 함수를 정의하고 해당 바이트 코드를 디어셈블 해 봅니다.
>>> import dis
>>> def foobar():
... return 'foo' + 'bar'
>>> dis.dis(foobar)
2 0 LOAD_CONST 3 ('foobar')
3 RETURN_VALUE
두 초기 상수를 이미 합쳐서 선언되었습니다. 'foobar'. CPython 바이트 코드가 최적화되지 않은 경우, 출력은 다음과 같습니다.
>>> dis.dis(foobar)
2 0 LOAD_CONST 1 ('foo')
3 LOAD_CONST 2 ('bar')
6 BINARY_ADD
7 RETURN_VALUE다음 표현식이 True로 평가되는 이유입니다.
>>> 'a' * 20 is 'aaaaaaaaaaaaaaaaaaaa'
큰 . pyc 파일 피하기
왜 ‘a’ * 21 is ‘aaaaaaaaaaaaaaaaaaaaa’은 True가 아닐까요?
>>>'a' * 20 is 'aaaaaaaaaaaaaaaaaaaa'
True
>>> 'a' * 21 is 'aaaaaaaaaaaaaaaaaaaaa'
False.pyc 파일을 기억하시나요? 파이썬 바이트 코드는 pyc 파일에 저장됩니다. ['foo!'] * 10**9는 어떻게 될까요? 만일 이토록 긴 문자열이 생성된다면, 이 현상을 피하기 위해, 길이가 20보다 길면 구멍 peephole optimization를 통해 생성된 시퀀스가 삭제됩니다.
Immutability required
마지막으로 파이썬 문자열은 immutable이기 때문에 interning이 작동합니다. mutable은 의미가 없습니다.
근데 정수는 … 왜??
>>> x, y = 256, 256
>>> x is y
True
>>> x, y = int('256'), int('256')
>>> x is y
True
>>> 257 is 257
True
>>> x, y = int('257'), int('257')
>>> x is y
False
'app > python' 카테고리의 다른 글
| array의 연산을 빠르게 하는 방법 (0) | 2021.04.09 |
|---|---|
| Peephole optimization (0) | 2020.04.09 |
| wsgi를 왜 쓰나요 (3) | 2020.03.31 |
| Python dictionary implementation (1) | 2020.03.21 |
| python list implementation (0) | 2020.03.20 |


