Oracle, PostgreSQL, MySQL Core Architecture 책 발췌
1. MVCC architecture
postgreSQL는 Multi Generation Architecture이다. 이는 update 작업이 발생 시 페이지의 이전 레코드를 overwrite 하는 대신 새로운 레코드를 만드는 구조이다.

postgreSQL의 레코드의 헤더는 레코드가 어디에 입력했는지 가르키는 라인 포인터를 가지고 있으며, 실제 레코드의 정보는 튜플의 헤더에 정보를 가지고 있다.
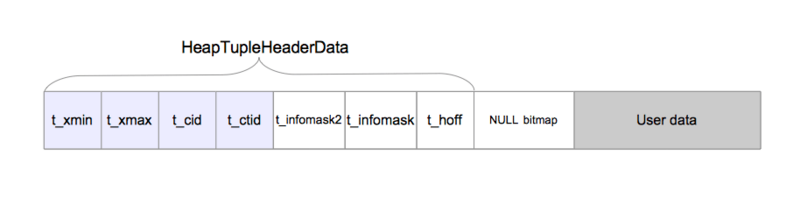
- t_xmin : insert 시의 XID
- t_xmax : delete 시의 XID
- t_cid : insert, delete , command id
- t_ctid : 해당 튜플의 현재 버전을 가리키는 포인터
- t_infomask: commit 여부
- t_hoff : 튜플의 헤더 길이
2. Insert / update의 내부 동작
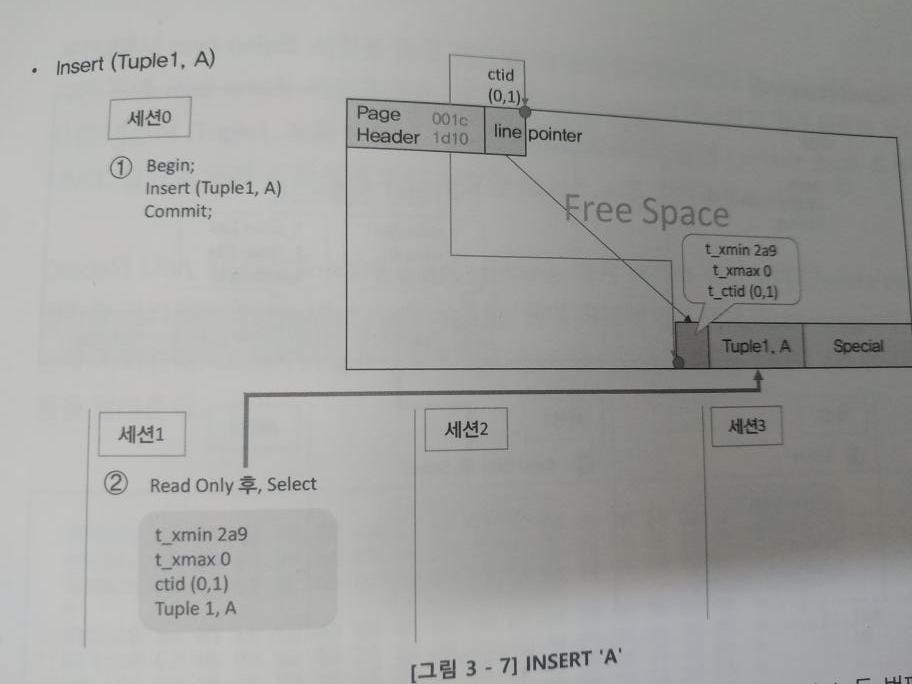
첫번째 insert
Insert ( tuple1, A )
Commit;- 라인 포인터가 가리키는 위치(page offset)에 생성되었음을 알려준다.
- t_xmin의 값이 입력 되고, t_ctid(0, 1)은 자기 자신을 가리킨다. (데이터가 하나이므로)
- read only로 고정시켜, 세션 0/세션 1에서 둘 다 읽을 수 있다.
첫 번째 업데이트
Update(tuple1, b)
Commit;- Insert된 (tuple1, A)를 (tuple1, B)로 update 하였다.
- t_xmax값이 입력된다. 이는 2aa까지 유효한 레코드라 것을 알려준다.
- 세션 2에서 read-only로 시점을 잡는다면, (tuple1, B)를 읽을 수 있다. 하지만 세션 1에서는 SCN을 보존시키고 있기 때문에 여전히 (tuple1, A)를 읽을 수 있다. ( t_xmax의 값에 따라 읽을수 있다. )
- t_ctid는 다음 이미지가 어디에 있는지 가리킨다. 즉 헤더가 가리키는 (0,2)가 최신인 것을 알 수 있다.

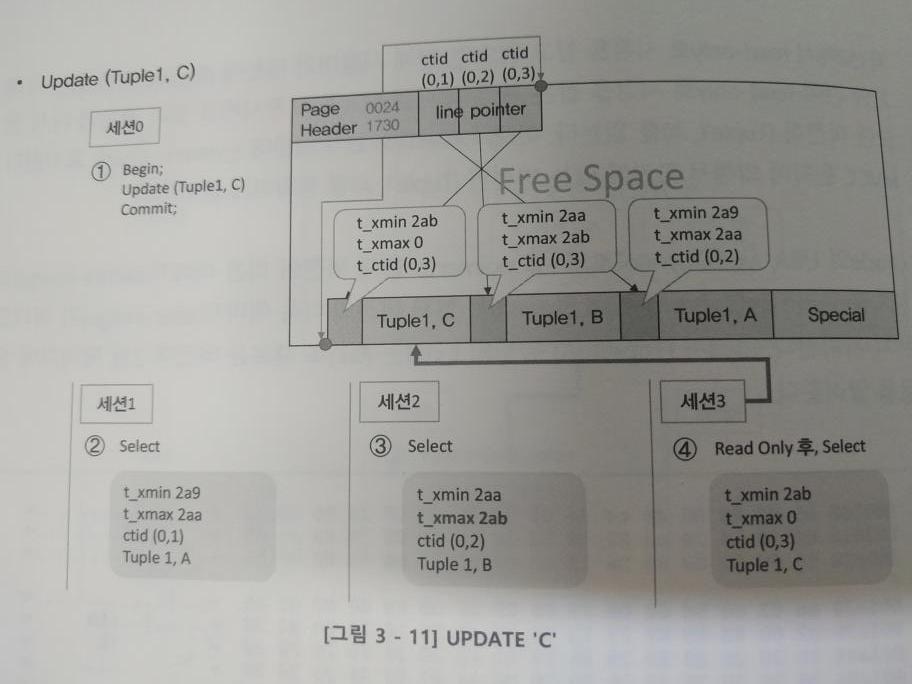
두 번째 업데이트
Update(tuple1, C)
commit이번에는 (tuple1, C)로 업데이트하였다.
- 세션 1은 read-only 잡은 시점이므로 (tuple1, A)를 읽고, 세션 2는 (tuple1, B)를 읽는다.
- 이때 업데이트가 되었기 때문에 세션 2에서 t_xmax가 바뀐다.
- 세션 3의 시점은 (tuple1, C)를 읽는다.
- 세션 1, 2, 3은 같은 레코드를 읽지만, 다른 세션이기 때문에 여러 개의 버저닝을 한다.
Update 후 커밋하지 않음
Update(tuple1, B)아래의 그림은 MVCC로 insert/update가 충돌하지 않는 것을 보여준다.
- 세션 1은 (tuple1, A)를 읽는다.
- 세션 2는 (tuple1, B) -> (tuple1, C)로 업데이트하려 했으나, 아직 커밋이 되지 않아 락 상태로 걸려있다.

- postgreSQL과 Mysql은 스냅숏과 리드 뷰를 가지고 있는데, 이는 select를 할 때 commit하지 않은 트랜잭션 리스트를 가지고 있어야만 정확하게 데이터를 읽을 수 있는 구조이다.

위의 그림은 각기 쿼리 시점이 다른 세션을 뜻한다.
1번 세션은 XID가 90이므로, 그 이후 발생된 데이터들만 있으므로 아무것도 조회가 되지 않는다.
2번 세션은 XID가 106번으로, t_xmin가 100, 104인 레코드가 조회된다. 101번은 쿼리 시작 지점에 104보다 이전 시점에 update or delete가 되어 조회되지 않는다. t_xmin는 105는 아직 commit 전으로 읽지 못한다.
3번 세션은 XID가 120으로 100, 104, 110번을 읽을수 있다. t_xmin 105번은 아직 commit 전으로 읽을수 없다.
3. vacuum
postgreSQL은 특정 데이터를 update 하거나 delete 한다고 해서 해당 영역이 자동으로 재사용되거나 사라지지 않는다. 또한 트랜잭션의 ID개수는 40억인데, 이를 초과하는 트랜잭션 겹침 현상이 발상하면 오래된 자료를 손실할 수 있으며, query planner가 사용할 통계 정보 갱신을 위해 vacuum이 필요하다.
Insert into t2 values(‘A1001’, ‘A’, ‘A’)
Insert into t2 values(‘A1002’, ‘A’, ‘A’)
Update t2 set c2 = ‘B’ where c1 = ‘A1001’아래의 그림과 같이 공간이 형성된다.
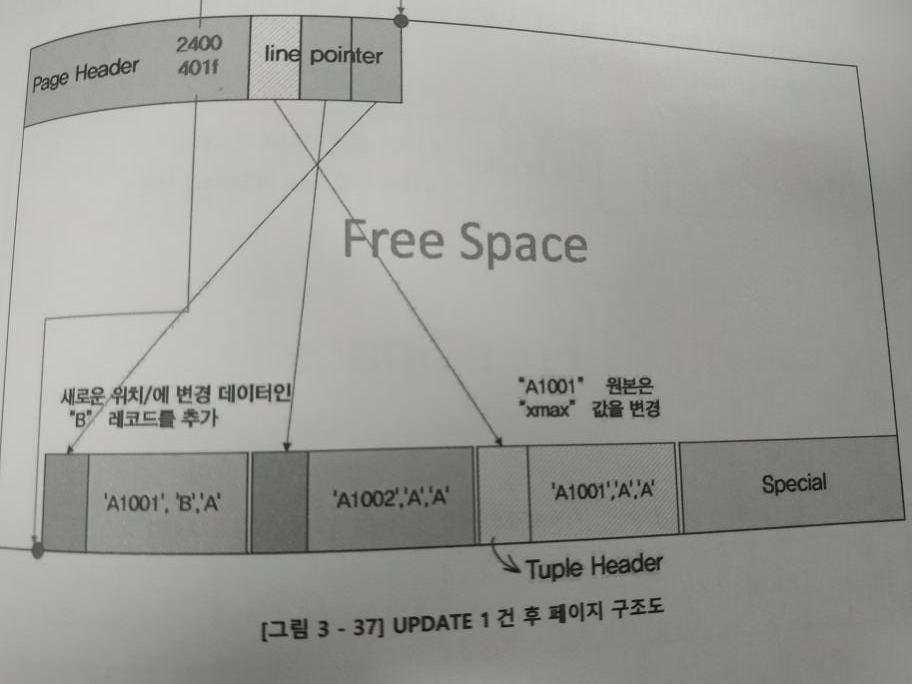
3.1 표준 Vacuum 동작시
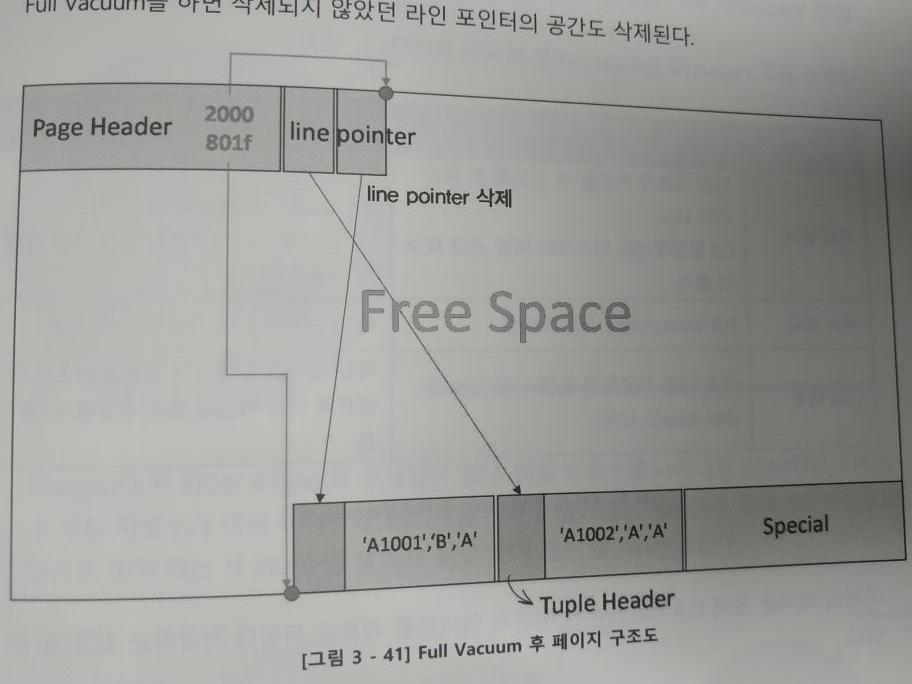
- (‘A1001’, ‘A’, ‘A’)의 라인 포인터는 삭제되나 공간은 남아있다.
- 해당 튜플은 삭제되고, 공간도 삭제돼서 프리 스페이스가 증가한다.
- 하지만 현존하는 튜플이 밀려(앞으로 당겨져) (‘A1001’, ‘B’, ‘A)의 튜플이 남아있는 것처럼 된다.

3.2 full vacuum
삭제되지 않았던 라인 포인터와 공간까지 모두 삭제된다.
| 표준 Vacuum | Full vacuum | |
| 처리방식 | 다른 자료가 저장될 수 있도록 빈 공간으로 표시 Os 차원의 디스크의 확보 불가 |
새 파일로 저장하는 방식 Os 차원의 디스크 여유 공간 확보 |
| 처리속도 | 매우 빠름 | 매우 느림 |
| Look 여부 | 다른 작업 가능 (alter table 제외) | 테이블 락으로 모든 작업 불가 |
4. XID wraparound와 Freezing
XID는 대략 40억 개를 순환하여 사용한다. 현재 XID기준으로 20억 개를 사용했고, 앞으로 20억 개의 사용할 수 있다. 현재 기준으로 앞으로 20억 개는 새 XID라 데이터가 안보이고, 뒤의 20억개는 옛 XID라 데이터가 보인다.
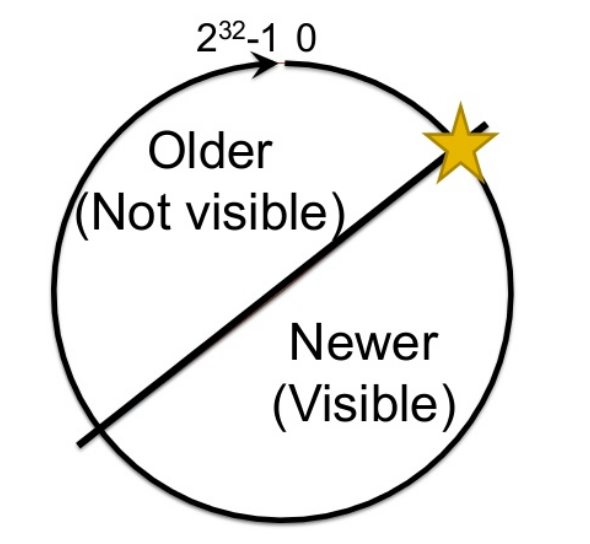
XID가 100인 시점에서 어떤 트랜잭션이 발생했다고 가정하자. XID가 100 시점에는 보이겠지만, 100 시점의 대칭점보다 작은 XID 시점에 왔을 때는 100에서 발생한 트랜잭션의 데이터가 보인다.(두 번째 스텝) 하지만 대칭점보다 큰 XID의 시점에서는 보이지 않는다. (세 번째 ) 대칭점이 이동하여 newer와 older의 위치가 변경되기 때문이다.

20억이 넘어가게 되면 데이터가 손실되기 때문에 이를 방지 하지 위해 Freezing으르 한다.
“Freezing”은 vacuum으로 실행되며, XID 100을 freezing 하면 frozneXID가 되어 대칭점이 지나도 xID100 시점의 데이터가 보이게 된다.

vacuum이 한 번도 안된 테이블은 vacuum_freeze_min_age(0.5억) 이 되면 autovacuum의 관리 대상이 된다. 이때 자동으로 vacuum + freeze 작업을 한다.
한 번이라도 vacuum 작업을 했다면, vacuum_freeze_table_age(1.5억)이 되어야만 autovacuum이 발생한다.
5. shared buffer
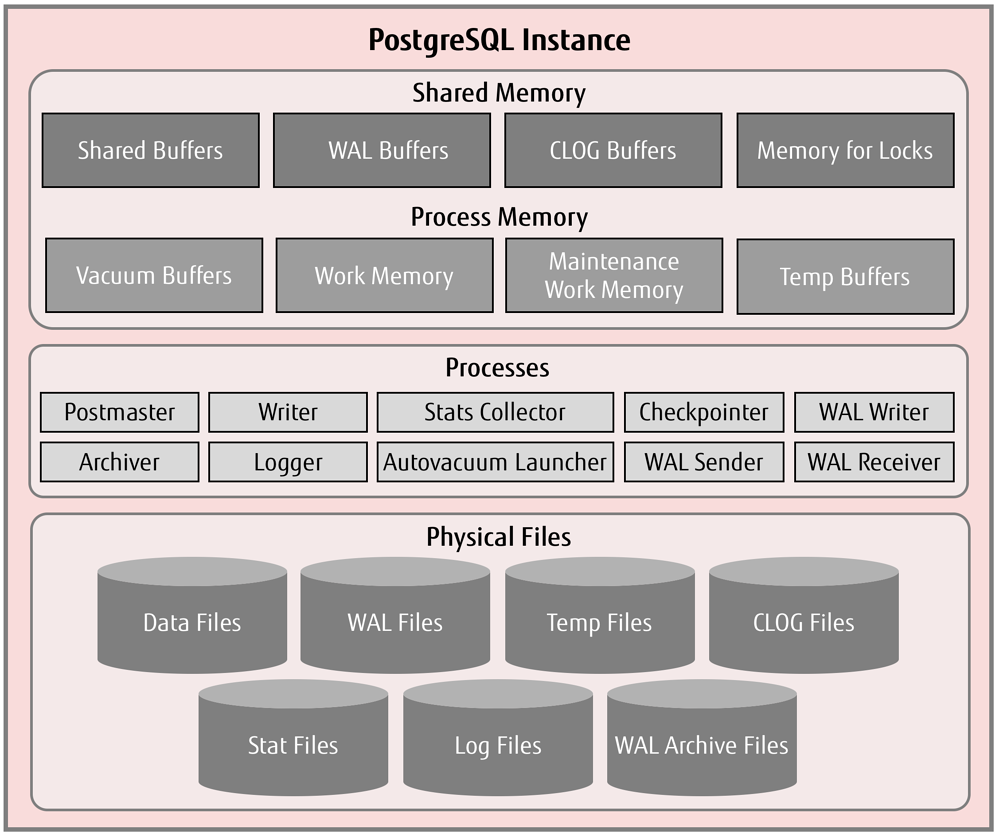
Hash table(SharedBufHash) : 데이터가 메모리에 로드되어 있는지 확인을 위한 테이블
Buffer pool : 디스크에 저장되어 있는 데이터를 메모리 상에 저장하는 장소
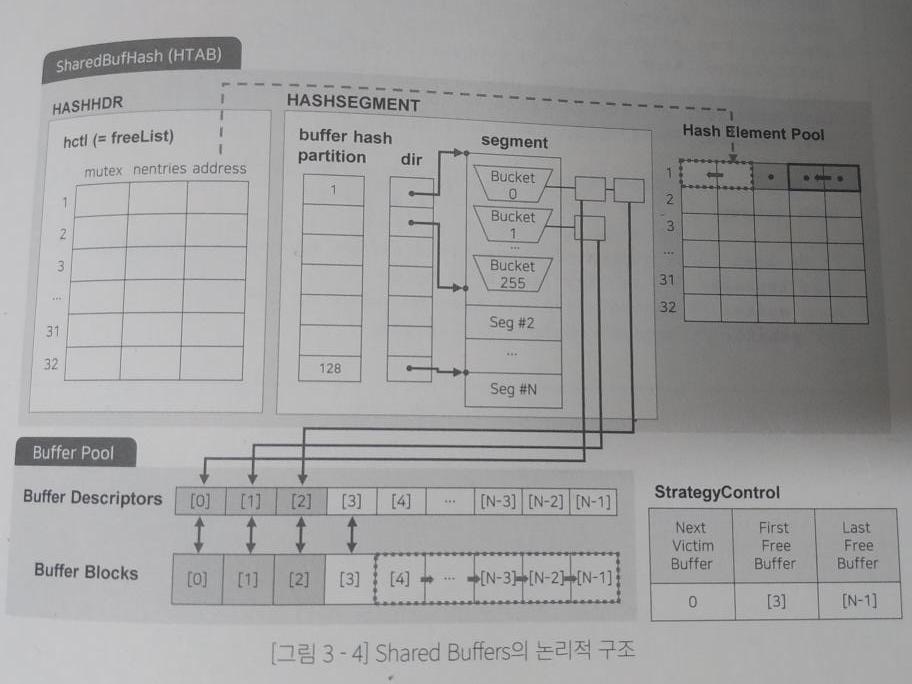
SharedBufHash
- HASHHDR(FreeList) : 헤시 테이블 헤더 구조체, hash element pool의 주소를 가리킴
- HASHSEGMENT
- partition : 엘리먼트 추가 시 락 제어
- dir : 각 세그먼트의 시작 포인터
- segment : bucket으로 이루어진 포인터 리스트
- hash element pool : 버킷에 할당하는 엘리먼트 집합
Buffer Pool
- Buffer Desc : block의 헤더 정보
- Buffer Blocks : 실제 데이터 로드 메모리
아래는 쿼리를 수행하기 위해 특정 데이터를 메모리에 올리는 작업의 시나리오이다.
1. 초기 상태 및 락 설정
- 현재 First Free buffer는 128번.
- 데이터 로드를 위해 partition 53에 락을 설정 == dir 53에 락 설정 == segment 53에 락 설정

2. 데이터 로드
- Buffer block 128에 데이터 로드
- StategyControl의 first free buffer의 주소 변경 (128 -> 129)
- buffer desc 128에 헤더 정보 추가 ( 주소 : 0x7 f)
- freeList에서 빈 공간 찾기 (hash element pool의 3번을 찾음, 그림엔 없음)
- element pool의 빈 공간에 buffer desc의 헤더 주소 생성
- element pool의 정보를 segment의 bucket에 전달
- bucket에 buffer desc 헤더 정보 저장

3. 버킷과 buffer 연결
- bucket와 buffer desc에 rel값 저장
- buffer desc state를 연결로 변경
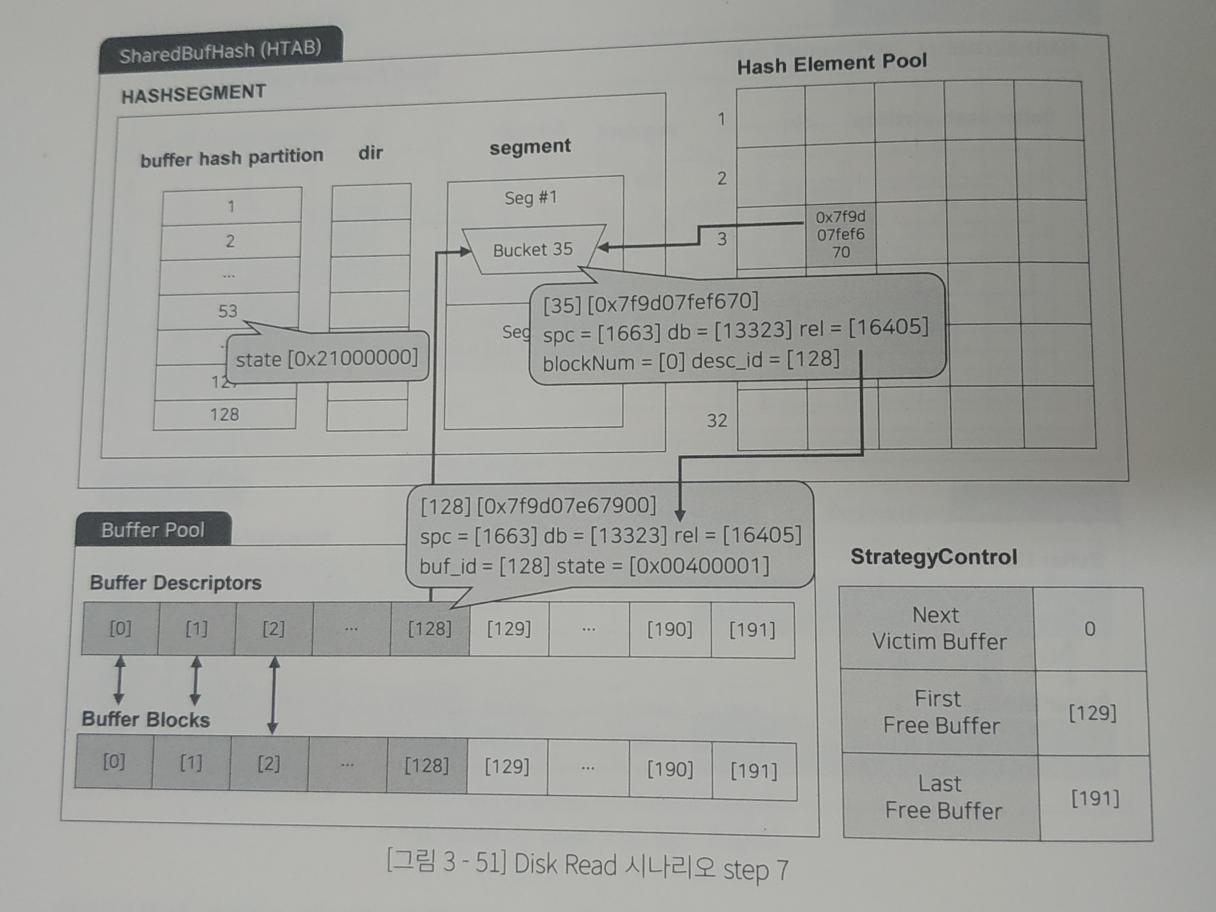
4. 락 해제
- partition의 53번 락 해제
- buffer desc 128의 락 해제

참고 자료
www.slideshare.net/pgdayasia/introduction-to-vacuum-freezing-and-xid
'Database > DB' 카테고리의 다른 글
| LeetCode sql 문제, 유저별 월별 집계 (0) | 2021.05.20 |
|---|---|
| postGIS 쿼리 튜닝 (0) | 2021.04.24 |
| DBMS core architecture 2 (0) | 2020.06.14 |
| DBMS core architecture 1 (0) | 2020.06.12 |
| postgreSQL 튜닝 (0) | 2020.06.11 |


