1. random forest
의사결정 트리가 여러 개 모인 것.
하나의 의사결정 트리는 훈련 데이터에 오버 피팅되는 경향이 있다.
오버 피팅을 해결하기 위해 여러 개의 결정 트리를 모아 random forest가 나왔다.
1.1 동작
- Bagging : training set의 부분집합을 활용하여 트리 형성 (각각의 부분집한의 인스턴스는 중복될 수 있다)
- bagging features : training set의 feature별로 트리를 형성한다.
- classiify : 2번에서 여러 개의 트리를 통해 ground truth(경계선)을 형성한다.
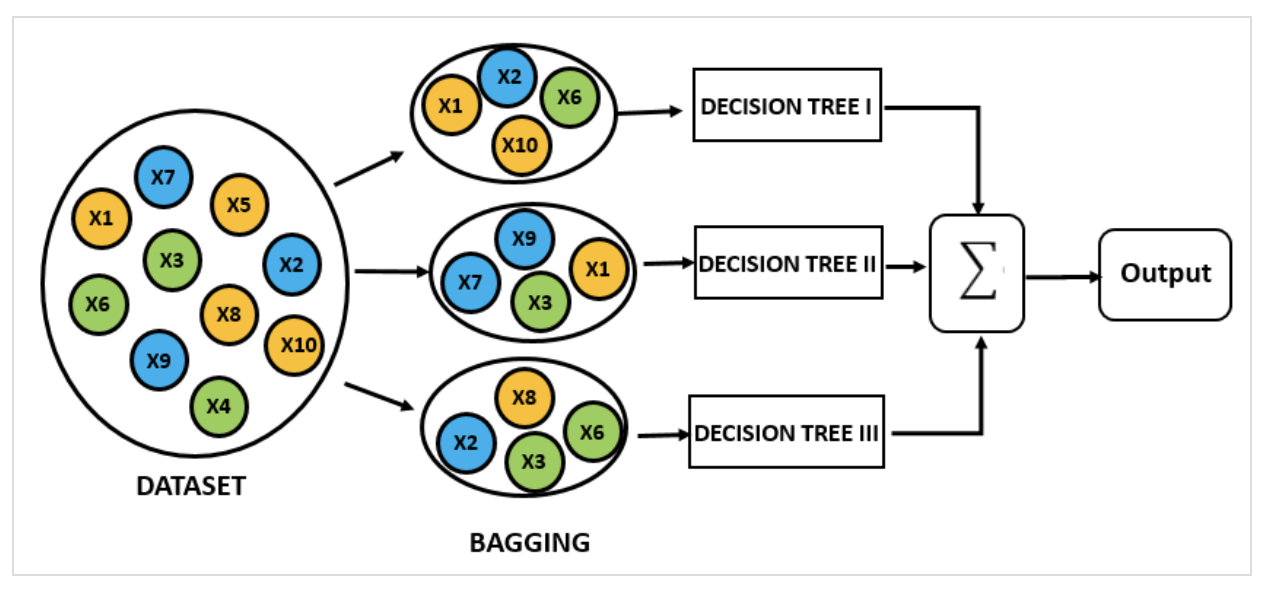
랜덤 포레스트가 생성한 일부 트리는 overfitting 될 수 있지만, 많은 수의 트리를 생성함으로써 overfitting이 예측하는 데 있어 큰 영향을 미치지 못하도록 예방할 수 있다.
1.3 문제점
- 정상치를 모두 고려해야 하므로 계산 부하가 크다
- 매번 정상치를 프로파일링 해서 이상치를 계산해야 하므로 생성 및 재활용이 어렵다
2. isolation forest
공간분할 기반 이상 탐지
- 특정 한 개체가 isolation 되는 leaf 노드(terminal node)까지의 거리를 outlier score로 정의
- 그 인스턴스 간의 평균 거리(depth)가 짧을수록 outlier score는 높아짐
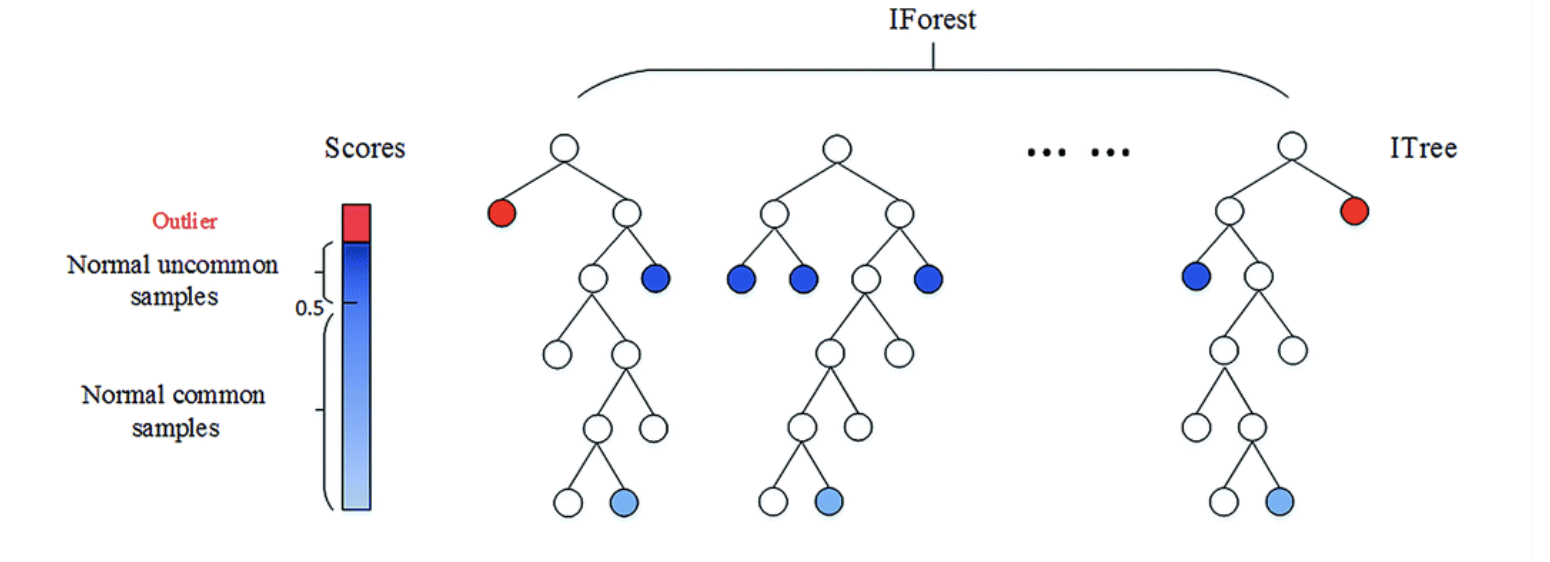
2.1 동작
1) 랜덤 하게 차원을 선택해서 임의의 기준으로 공간을 분할.
- 군집 내부에 있는 이상치 Xi의 경우 공간 내에 한 점만 남기고 완전히 고립시키려면 많은 횟수의 공간 분할을 수행해야 하지만, X0의 경우 적은 횟수의 공간 분할로 고립이 가능하다.
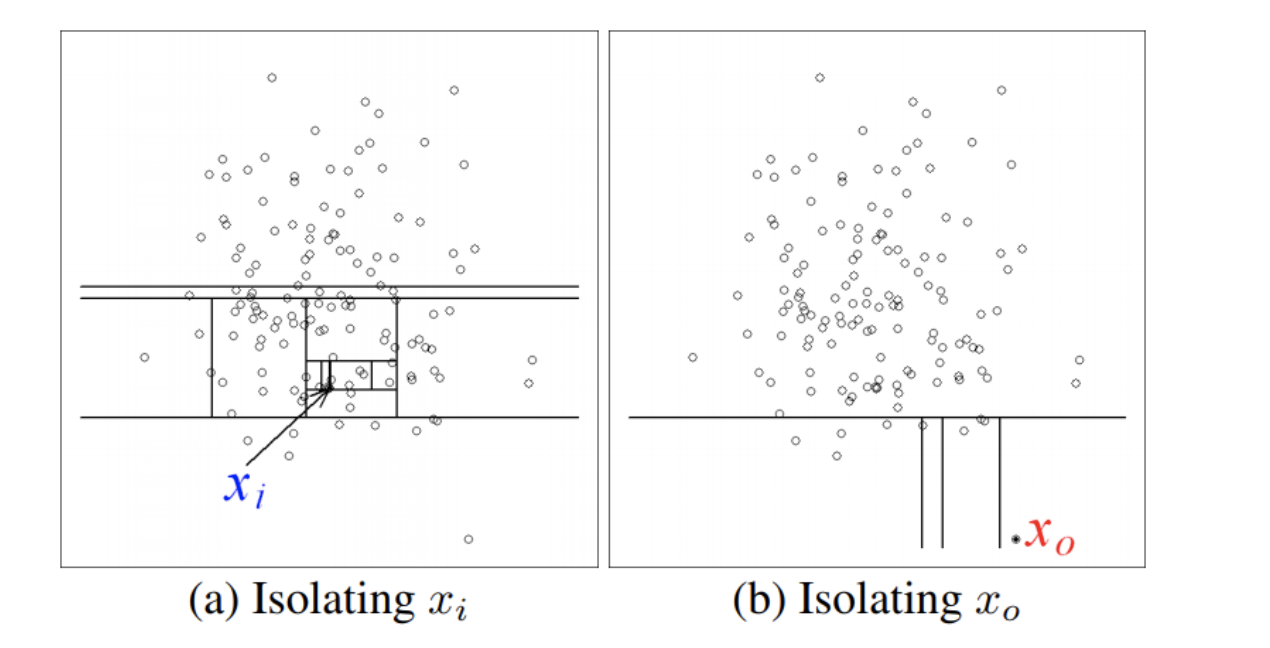
공간 분할은 차원과 기준값으로 표현할 수 있으므로, 여러 번의 공간 분할은 의사결정 나무(Desicion Tree) 형태로 표현 가능하다. 정상치일수록 완전히 고립시킬 수 있을 때까지 의사결정 나무를 깊숙하게 타고 내려가야 한다.(정상치는 많이 뭉쳐 있으므로), 반대로 이상치의 경우 상단부만 타더라도 고립될 가능성이 높다. 이런 특성을 이용하여 몇 회를 타고 내려가야 고립되는가의 기준으로 정상치와 이상치를 나눌 수 있다.
2.2 특징
Isoltion forest는 군집 기반 이상 탐지 알고리즘에 월등한 성능을 보이는데, 자기 자신을 제외한 모든 인스턴스에 대한 유클리디안 거리를 계산해야 하므로 O(N^2)의 수행 시간이 필요하지만, Isolation Forest의 경우 일부 데이터만 샘플링하여 의사결정 나무 모델을 생성하여, O(logN)의 수행 시간으로 처리된다.
또한 solation Forest는 전수 데이터를 이용하지 않고 일부 데이터만 샘플링해서 모델을 생성하기 때문에, 상대적으로 이런 오류에 강건한 특성을 가지게 된다.
train 데이터에 이상치가 포함되지 않아도 잘 동작하는데, score 판정 자체가 x까지의 경로 길이로 산정한다. 이상치가 학습 데이터에 있는지 없는지가 중요하지 않다.
Random Forest vs Isolation Forest
Random Forest (지도 학습): 각 트리의 예측을 결합하고, 각 트리를 통과한 결괏값으로 최종 예측한다.
Isolation Forest (비지도 학습): 각 트리의 예측을 결합하고, 해당 인스턴스의 거리까지의 경로의 길이를 계산한다. 이상치는 정상 데이터보다 분리하기가 쉬워 경로가 더 짧게 계산된다.
'ML > 인공지능' 카테고리의 다른 글
| 이상감지 소스 및 간략 설명 (0) | 2021.07.02 |
|---|---|
| 이상감지 (정리) (0) | 2021.05.25 |
| RNN // LSTM 공부한 내용 (0) | 2021.05.17 |
| 신경 회로망 모델 (0) | 2009.11.15 |
| ,,,,,,, (0) | 2009.05.18 |


