1) 선언적 파티션
선언적 파티션 구성 실습은 postgres 10.X 이상에서만 가능하다.
9.* 버전의 경우 테이블 파티션 명령어가 없기 때문에 2) Partitioning Using Inheritance(하단 참조)를 사용해야 한다.
select version();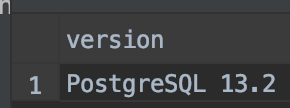
1. 파티션 테이블 생성
대형 아이스크림 회사를 위한 데이터베이스를 구축한다고 가정합니다. 이 회사는 매일 최고 기온과 각 지역의 아이스크림 판매량을 저장할 테이블을 다음과 같이 예정이다.
|
1
2
3
4
5
6
|
CREATE TABLE measurement (
city_id int not null, -- 도시 id
logdate date not null, -- 날짜
peaktemp int, -- 최고 온도
unitsales int -- 판매량
);
|
cs |
저장해야하는 오래된 데이터의 양을 줄이기 위해 가장 최근 2년 분량의 데이터만 보관하기로 결정했다. 매년 초에 가장 오래된 년도의 데이터를 제거할 것이다. 이 상황에서 파티셔닝을 사용하여 measurement 테이블에 대한 다양한 요구 사항을 모두 충족할 수 있다.
선언적 파티셔닝을 사용
1. 파티션 방법은 분할 key로 사용할 열(column) 목록을 포함해야 한다.
PARTITION BY RANGE절을 지정하여 테이블을 파티션 된 테이블로 만든다. 아래의 쿼리는 logdate(날짜)를 기준으로 파티션을 설정한다.
|
1
2
3
4
5
6
|
CREATE TABLE measurement (
city_id int not null ,
logdate date not null ,
peaktemp int ,
unitsales int
) PARTITION BY RANGE (logdate); -- 파티션 키를 logdate로 지정
|
cs |
2. 각 파티션 정의는 부모 테이블 파티션 방법 및 파티션 키에 해당하는 경계를 지정해야 한다.
새 파티션의 값이 하나 이상의 기존 파티션에 있는 값과 겹치도록 경계를 지정하면 오류가 발생한다. 이렇게 생성된 파티션은 모든 방법으로 일반적인 PostgreSQL 테이블이다. 각 파티션에 대한 테이블 스페이스 및 스토리지 매개 변수를 개별적으로 지정할 수 있다.
위의 예제의 경우 각 파티션은 한 번에 1년의 데이터를 삭제해야하는 요구 사항과 일치하도록 테이블 생성 쿼리는 다음과 같다.
|
1
2
3
4
5
6
7
8
9
10
|
CREATE TABLE measurement_y2020 PARTITION OF measurement
FOR VALUES FROM ('2020-01-01') TO ('2020-12-31');
CREATE TABLE measurement_y2021 PARTITION OF measurement
FOR VALUES FROM ('2021-01-01') TO ('2021-12-31')
TABLESPACE pg_default;
CREATE TABLE measurement_y2022 PARTITION OF measurement
FOR VALUES FROM ('2022-01-01') TO ('2022-12-31')
TABLESPACE pg_default;
|
cs |
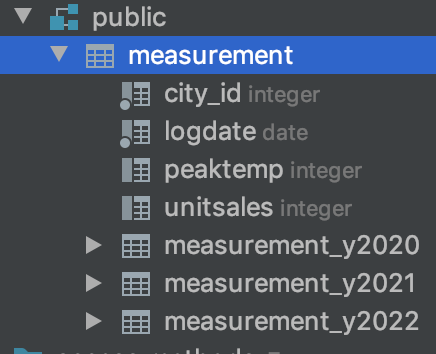
생성후 테이블의 구조. 해당 테이블의 하위에 파티션으로 생성한 테이블이 위치한다.
번외 TABLESPACE (오라클과 postgres 에만 있음)
- 해당 테이블을 저장할 때 로컬 경로를 지정해서 저장 가능한 기능
postgres에서 테이블스페이스는 DB 관리자에 의해 데이터베이스의 객체가 저장될 수 있는 파일 시스템의 경로로 정의된다. 테이블스페이스가 생성되면 데이터베이스 객체에 객체를 생성할 때 이름에 의해서 테이블스페이스가 참조될 수 있다.
장점
- DB가 생성된 볼륨 또는 파티션에 여유공간이 부족할 때 테이블스페이스를 다른 파티션이나 디스크에 생성하여 시스템을 재구성할 때까지 DB를 확장할 수 있다.
- 데이터베이스 객체의 성능 최적화를 위해 사용할 수 있다는 것이다. 예를 들어 매우 사용량이 많으면서 자주 업데이트되는 인덱스를 위해 고성능 SSD를 장착하고 테이블스페이스를 생성하여 인덱스를 SSD에 생성하여 성능을 개선하는 데 사용될 수 있다.
만약 물리적으로 다른 경로를 DB에 사용하고자 할 때 테이블스페이스로 지정하여 DB를 확장할 수 있다. 테이블 스페이스는 다음과 같은 DDL 문으로 생성할 수 있으며 해당 테이블스페이스에 태이블을 생성할 수 있다.
|
1
|
CREATE TABLESPACE fasttablespace LOCATION '/tmp/data'; # 실제 로컬 폴더가 있어야 한다.
|
cs |
테이블 스페이스 생성 확인
|
1
|
SELECT * FROM pg_tablespace;
|
cs |

3. 분할 된 테이블의 키 열과 원하는 다른 인덱스에 인덱스를 생성한다.
키 인덱스가 꼭 필요한 것은 아니지만 대부분의 시나리오에서 유용하다. 이렇게 하면 각 파티션에 일치하는 인덱스가 자동으로 만들어지며 나중에 만들거나 연결하는 모든 파티션에도 인덱스가 생성된다. 분할된 테이블에 선언된 인덱스 또는 고유 제약 조건은 분할된 테이블과 동일한 방식으로 동작한다. 실제 데이터는 개별 파티션 테이블의 하위 인덱스에 존재한다.
|
1
|
CREATE INDEX ON measurement (logdate);
|
cs |
4. postgresql.conf 에서 enable_partition_pruning 구성 매개 변수가 비활성화되어 있지 않은지 확인한다 . 그렇다면 쿼리가 원하는대로 최적화되지 않는다.
위의 예에서는 매년 새 파티션을 작성하므로 필요한 DDL을 자동으로 생성하는 스크립트를 작성하는 것이 좋습니다.
2. insert 테스트
|
1
2
3
4
|
insert into measurement
values (1, date('2021-06-30'), 1, 1);
select * from measurement;
|
cs |

위와 같이 measurement 테이블 조회시 데이터가 추가된 것을 볼 수 있다.
또한 해당 데이터는 measurement_y2021에 들어간것을 확인할 수 있다.
|
1
|
select * from measurement_y2021;
|
cs |

insert시 파티션으로 설정된 칼럼 범위에 포함된 데이터가 아니라면 에러가 발생한다.
ex: 파티션의 범위가 2020, 2021, 2022년 이므로 2000년의 데이터는 에러가 발생한다.
|
1
2
3
|
# 에러 코드. date가 파티셔닝의 범위에서 벗어남
insert into measurement
values (9999, date('2000-12-30'), 9999, 9999);
|
cs |

3. 파티션 테이블 삭제
필요없는 데이터가 축적된 2020년의 테이블(오래된 데이터)을 제거하는 가장 간단한 옵션은 더 이상 필요하지 않은 파티션을 삭제하는 것입니다.
|
1
|
DROP TABLE measurement_y2020;
|
cs |
4. 실행 계획 + 파티션 프루닝
파티션 프루닝은 선언적으로 파티션 된 테이블은 성능을 향상시키는 쿼리 최적화 기술이다.
|
1
2
3
4
5
|
SET enable_partition_pruning = on; -- default
SELECT count(*)FROM measurement
WHERE logdate >=DATE '2022-01-01';
|
cs |
파티션 프루닝이 없으면 위의 쿼리는 measurement 테이블 의 각 파티션을 스캔합니다. 파티션을 사용하면 실행계획은 각 파티션의 정의를 검사하고 쿼리의 WHERE 절을 충족하는 행을 포함된 파티션 만을 스캔한다.
EXPLAIN 명령과 enable_partition_pruning 구성 매개 변수를 사용하면 파티션 계획과 그렇지 않은 계획의 차이를 표시 할 수 있다.
이 유형의 테이블 설정에 대한 일반적인 최적화되지 않은 계획은 다음과 같습니다.
- enable_partition_pruning = off 에서는 파티션 테이블을 모두 스캔한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
SET enable_partition_pruning = off;
EXPLAIN
SELECT count(*)FROM measurement
WHERE logdate >=DATE '2022-01-01';
QUERY PLAN
-----------------------------------------------------------------------------------
QUERY PLAN
Append (cost=0.00..37.85 rows=420 width=100) (actual time=0.016..0.017 rows=1 loops=1)
-> Seq Scan on measurement_y2021_city_1_to_100 measurement_1 (cost=0.00..17.88 rows=210 width=100) (actual time=0.011..0.012 rows=0 loops=1)
Filter: (logdate >= '2022-01-30'::date)
Rows Removed by Filter: 2
-> Seq Scan on measurement_y2022_city_101_to_200 measurement_2 (cost=0.00..17.88 rows=210 width=100) (actual time=0.004..0.004 rows=1 loops=1)
Filter: (logdate >= '2022-01-30'::date)
|
cs |
프루닝은 전체 테이블 순차 스캔 대신 이 쿼리에서는 파티션의 범위에 따라 이전 테이블(2021 이전 테이블)을 전혀 스캔할 필요가 없다는 것입니다.
파티션 정리를 사용하면 동일한 답변을 제공하는 훨씬 효율적인 실행계획을 얻을 수 있다.
- enable_partition_pruning = on 상태에서는 2022년 테이블 하나만 스캔한다.
|
1
2
3
4
5
6
7
8
9
10
11
|
SET enable_partition_pruning = on;
EXPLAIN
SELECT count(*)FROM measurement
WHERE logdate >=DATE '2022-01-01';
QUERY PLAN
-----------------------------------------------------------------------------------
QUERY PLAN
Seq Scan on measurement_y2022_city_101_to_200 measurement (cost=0.00..17.88 rows=210 width=100) (actual time=0.009..0.010 rows=1 loops=1)
Filter: (logdate >= '2022-01-30'::date)
|
cs |
파티션 프루닝은 인덱스의 존재가 아니라 파티션 키에 의해 암시적으로 정의 된 제한 조건에 의해서만 구동된다
따라서 키 열에 인덱스를 정의 할 필요는 없다. 지정된 파티션에 대해 인덱스를 작성해야 하는지 여부는 파티션을 스캔하는 쿼리가 따라 다르다.
5. partition by range multiple columns - 복합 칼럼 파티션
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
CREATE TABLE measurement (
city_id int not null ,
logdate date not null ,
peaktemp int ,
unitsales int ,
name char(20) not null
) PARTITION BY RANGE (logdate, city_id);
CREATE TABLE measurement_y2021_city_1_to_100 PARTITION OF measurement
FOR VALUES FROM ('2021-01-01', 1) TO ('2021-12-31', 100)
TABLESPACE pg_default;
CREATE TABLE measurement_y2022_city_101_to_200 PARTITION OF measurement
FOR VALUES FROM ('2022-01-01', 101) TO ('2022-12-31', 200)
TABLESPACE pg_default;
|
cs |
복합 칼럼을 파티션을 생성할 경우 해당 범위가 겹칠수 없다. (겹친다면 파티션 생성 시 에러가 발생한다)
|
1
2
3
4
5
6
7
8
|
insert into measurement
values (1, date('2021-06-30'), 1, 1, 'name1');
insert into measurement
values (101, date('2021-06-30'), 1, 1, 'name2');
insert into measurement
values (1, date('2022-12-30'), 1, 1, 'name3');
|
cs |
데이터의 추가 일 경우 서로 겹치는 데이터를 넣을 경우 ( 두번째로 실행한 insert는 date()의 범위는 첫 번째 테이블인 measurement_y2021_city_1_to_100에 속하지만, city_id는 두 번째 테이블인 measurement_y2022_city_101_to_200에 속한다) 파티셔닝의 레인지의 순서대로 보기 때문에 (logdate 먼저, 체크 후 city_id ) 첫 번째 테이블인 measurement_y2021_city_1_to_100로 들어간다.
|
1
|
select * from measurement_y2021_city_1_to_100
|
cs |

6. 선언적 파티셔닝의 한계
- 분할된 테이블의 고유한 제약 조건(즉, 기본 키)에는 모든 파티션 키 열이 포함되어야 한다. 이 제한은 제약 조건을 구성하는 개별 인덱스가 자체 파티션 내에서만 고유성을 직접 적용할 수 있기 때문에 존재하며, 따라서 파티션 구조 자체는 서로 다른 파티션에 중복되지 않도록 보장해야 한다
- INTERT에서 행 트리거를 시작하기 전에 새 행의 최종 대상이 되는 파티션은 변경할 수 없다.
- 유니크 키는 언제나 파티션의 기준이 되는 칼럼이 포함되어야 한다. 그렇지 않으면 아래의 에러가 발생한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
CREATE TABLE measurement (
id bigint primary key,
city_id int not null ,
logdate date not null ,
peaktemp int ,
unitsales int ,
name char(20) not null
) PARTITION BY RANGE (logdate);
[0A000] ERROR: unique constraint on partitioned table must include all partitioning columns
Detail: PRIMARY KEY constraint on table "measurement" lacks column "logdate" which is part of the partition key.
|
cs |
PRIMARY KEY or unique 추가를 한다면 아래와 같이 해야 한다
|
1
2
3
4
5
6
7
8
9
|
CREATE TABLE measurement (
city_id int not null ,
logdate date not null ,
peaktemp int ,
unitsales int ,
name char(20) not null,
-- CONSTRAINT pk_logdata_city_id PRIMARY KEY (logdate, city_id), -- primary key 추가시
-- CONSTRAINT unique_logdata_city_id unique (logdate, city_id) -- unique key 추가시
) PARTITION BY RANGE (logdate);
|
cs |
개별 파티션은 백그라운드에서 상속을 사용하여 부모테이블에 연결된다. 선언적으로 분할된 테이블 또는 해당 파티션과 함께 상속의 모든 일반 기능을 사용할 수는 없다. 특히 파티션은 파티션 테이블 이외의 상위 테이블을 가질 수 없으며 파티션 테이블과 일반 테이블에서 상속할 수도 없다.
분할된 테이블과 해당 파티션으로 구성된 파티션 계층은 여전히 상속 계층이므로, 몇 가지 예외를 제외하고 모든 일반 상속 규칙이 적용된다.
- 파티션은 부모에 없는 열을 가질 수 없다. CREATE TABLE을 사용하여 파티션을 만들 때 열을 지정할 수 없으며 ALTER TABLE을 사용하여 사실상 파티션에 열을 추가할 수도 없다. 열이 부모와 정확히 일치하는 경우에만 ALTER TABLE... ATTACH PARTITION을 사용하여 테이블을 파티션으로 추가할 수 있다.
- 분할 테이블의 CHECK 및 NOT NULL 제약 조건 모두 항상 모든 파티션에 상속된다. 상위 테이블에 동일한 제약 조건이 있는 경우 파티션 열에 NOT NULL 제약 조건을 놓을 수 없다.
- 파티션이 없는 한 파티션 테이블에만 제약 조건을 추가하거나 삭제하는 데만 사용한다. 파티션이 있는 경우만 사용하면 오류가 발생한다. 대신 파티션 자체에 대한 제약 조건을 추가하고 상위 테이블에 없는 경우 해당 제약 조건을 삭제할 수 있다.
2) 상속을 통한 파티션 - Partitioning Using Inheritance
9.* 이하 버전에서 쓰던 파티션 방식, 하지만 명시적 파티션보다 파티션 조건을 트리거를 통해 명시함으로써 더 많은 기능으로 활용할 수 있다.
테이블 상속을 사용하여 파티셔닝을 구현할 수 있으며, 다음과 같은 선언적 파티셔닝에서 지원되지 않는 몇 가지 기능을 사용할 수 있다.
- 선언적 파티션은 파티션 테이블과 원본 테이블이 정확히 동일한 열을 가져야 하지만 테이블 상속을 사용하면 자식 테이블에 부모에 열을 달리 할 수 있다
- 테이블 상속은 다중 상속을 허용한다
- 선언적 파티셔닝은 범위, 목록 및 해시 파티셔닝만 지원하는 반면 테이블 상속을 통해 사용자가 선택한 방식으로 데이터를 나눌 수 있다. 그러나 제약 조건 제외가 자식 테이블을 효과적으로 제거할 수 없으면 쿼리 성능이 저하될 수 있다.
- 일부 작업에서는 테이블 상속을 사용할 때도 다 선언적 파티셔닝을 사용할 때 더 강력한 잠금이 필요하다. 예를 들어 파티션을 ACCESS EXCLUSIVE 테이블에서 파티션을 제거하려면 상위 테이블에 대한 ACCESS EXCLUSIVE 잠금을 가져와야 하는 반면, SHARE UPDATE EXCLUSIVE 잠금은 일반 상속의 경우 충분하다
모든 "하위" 테이블이 상속되는 "마스터" 테이블을 만든다. 이 테이블에는 데이터가 포함되지 않습니다. 모든 하위 테이블에 동일하게 적용되지 않는 한 이 테이블에 검사 제약 조건을 정의하면 안 된다. 인덱스나 고유한 제약 조건을 정의해도 의미가 없다.
1. 마스터 테이블 생성
마스터 테이블은 위에서 정의된 measurement 테이블이다.
|
1
2
3
4
5
6
|
CREATE TABLE measurement (
city_id int not null,
logdate date not null,
peaktemp int,
unitsales int
);
|
cs |
2. 마스터를 상속하는 자식 테이블 생성
각각 마스터 테이블에서 상속되는 여러 "하위"테이블을 작성한다. 일반적으로 이러한 테이블은 마스터에서 상속된 집합에 열을 추가하지 않는다. 선언적 파티셔닝과 마찬가지로 이러한 테이블은 모든 방법으로 일반적인 PostgreSQL 테이블 (또는 외부 테이블)이다
제약 조건으로 인해 다른 자식 테이블에서 허용되는 키 값이 겹치지 않아야 한다.
|
1
2
3
4
5
6
7
8
9
10
11
|
CREATE TABLE measurement_y2020 (
CHECK ( logdate >= DATE '2020-01-01' AND logdate <= DATE '2020-12-31' )
) INHERITS (measurement);
CREATE TABLE measurement_y2021 (
CHECK ( logdate >= DATE '2021-01-01' AND logdate <= DATE '2021-12-31' )
) INHERITS (measurement);
CREATE TABLE measurement_y2022 (
CHECK ( logdate >= DATE '2022-01-01' AND logdate < DATE '2022-12-31' )
) INHERITS (measurement);
|
cs |
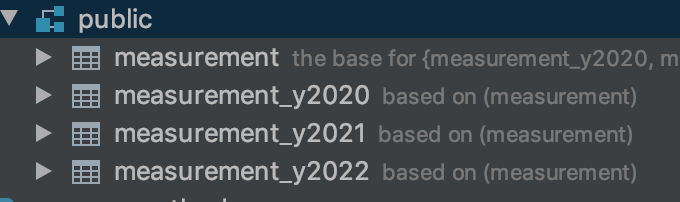
3. 각 하위 테이블에 대해 키 열에 인덱스 및 원하는 다른 인덱스를 만듭니다.
|
1
2
3
|
CREATE INDEX measurement_y2020_logdate ON measurement_y2020 (logdate);
CREATE INDEX measurement_y2021_logdate ON measurement_y2021 (logdate);
CREATE INDEX measurement_y2022_logdate ON measurement_y2022 (logdate);
|
cs |
4. 적절한 트리거 함수를 마스터 테이블에 추가한다. 데이터가 자식에 추가할 수 있도록 간단한 트리거 기능을 사용할 수 있습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
-- 트리거 함수 생성
CREATE OR REPLACE FUNCTION measurement_insert_trigger()
RETURNS TRIGGER AS $$
BEGIN
IF ( NEW.logdate >= DATE '2020-01-01' AND
NEW.logdate <= DATE '2020-12-31' ) THEN
INSERT INTO measurement_y2020 VALUES (NEW.*);
ELSIF ( NEW.logdate >= DATE '2021-01-01' AND
NEW.logdate <= DATE '2021-12-31' ) THEN
INSERT INTO measurement_y2021 VALUES (NEW.*);
ELSIF ( NEW.logdate >= DATE '2022-01-01' AND
NEW.logdate <= DATE '2022-12-31' ) THEN
INSERT INTO measurement_y2022 VALUES (NEW.*);
ELSE
RAISE EXCEPTION 'Date out of range. Fix the measurement_insert_trigger() function!';
END IF;
RETURN NULL;
END;
$$
LANGUAGE plpgsql;
-- 트리거 함수 연결
CREATE TRIGGER measurement_trigger
BEFORE INSERT ON measurement
FOR EACH ROW EXECUTE PROCEDURE measurement_insert_trigger();
|
cs |
트리거 정의는 이전과 동일하다. 각 IF 조건은 자식 테이블의 CHECK 제약 조건과 정확히 일치해야 한다.
5. 데이터를 Insert 해보면 measurement에 모든 데이터가 insert 되고 logdate에 따라서 다시 measurement_y2020, measurement_y2021에 데이터가 등록된 것을 확인할 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
insert into measurement
values (1, date('2021-06-30'), 1, 1);
insert into measurement
values (2, date('2020-04-10'), 2, 2);
select * from measurement;
select * from measurement_y2020;
select * from measurement_y2021;
|
cs |
상속 파티션 시 경고 사항
상속을 사용하여 구현된 분할에는 다음 사항을 주의해야 한다.
- 모든 CHECK 제약 조건이 상호 배타적임을 확인하는 자동 방법은 없다. 자식 테이블을 생성하고 관련 개체를 직접 작성하거나 수정하는 것보다 자식 테이블을 생성 및 수정하는 코드를 만드는 것이 더 안전하다.
- 인덱스와 외래 키 제약 조건은 상속 자식이 아닌 단일 테이블에 적용되므로 몇 가지 주의 사항이 있다.
- 자식 파티션에 UPDATE / CHECK 제약 조건을 추가하려 한다면 실패하게 된다. 이러한 경우를 처리해야 하는 경우 하위 테이블에 적합한 업데이트 트리거를 배치할 수 있지만 구조 관리가 훨씬 복잡해진다.
- 수동 VACUUM 또는 ANALYZE 명령을 사용하는 경우 각 하위 테이블에서 개별적으로 명령을 실행해야 한다
|
1
|
ANALYZE measurement; -- 마스터 테이블만 처리됨
|
cs |
- INSERT ON CONFLICT 절이 있는 INSERT 문은 예상 한대로 작동하지 않는다. ON CONFLICT는 하위 관계가 아닌 지정된 대상관계에 대한 고유 한 위반의 경우에만 수행되기 때문이다.
7. 선언적 파티션 Best Practices
쿼리 계획 및 실행 성능이 불량한 설계로 인해 부정적인 영향을 받을 수 있으므로 테이블을 분할하는 방법을 신중하게 선택해야 한다.
가장 중요한 설계 결정 중 하나는 데이터를 분할하는 열(column)이다. 종종 분할된 테이블에서 실행되는 쿼리의 WHERE 절에 가장 흔하게 나타나는 열 또는 열 집합으로 분할하는 것이 최선의 선택이다. 여기서 파티션 바인딩 제약 조건과 호환되는 절은 불필요한 파티션을 제거하는 데 사용될 수 있다. 그러나 기본 키 또는 고유 제약 조건에 대한 요구 사항에 따라 다른 결정을 내려야 할 수도 있다. 파티션 전략을 계획할 때 원치 않는 데이터를 제거하는 것도 고려해야 한다. 전체 파티션은 상당히 빠르게 분리될 수 있으므로 한 번에 제거할 모든 데이터가 단일 파티션에 배치되도록 파티션 전략을 설계하는 것이 유리할 수 있다.
테이블을 분할해야 하는 파티션의 목표 개수를 선택하는 것도 중요한 결정이다. 파티션이 충분하지 않으면 인덱스가 너무 크게 유지되고 데이터 인접성이 저하되어 캐시 적중률이 낮아질 수 있다. 그러나 파티션이 너무 많으면 쿼리 계획 및 실행 중에 쿼리 계획 시간이 길어지고 메모리 사용량이 늘어날 수 있다. 테이블을 분할하는 방법을 선택할 때는 향후 어떤 변경 사항이 발생할지도 고려해야 한다.
예를 들어, 고객당 하나의 파티션을 가지고 있고 현재 소수의 대규모 고객이 있는 경우, 수년 내에 다수의 소규모 고객을 보유하고 있는 경우를 고려해야 한다. 이 경우, LIST로 분할하려고 하기보다는 HASH로 분할하고 합리적인 수의 파티션을 선택하는 것이 더 나을 수 있다.
예를 들어, 고객당 하나의 파티션을 가지고 있고 현재 소수의 대규모 고객이 있는 경우, 수년 내에 다수의 소규모 고객을 보유한다고 가정해보자. 이 경우, LIST로 분할하려고 하고 데이터를 분할하는 것이 실제적인 것보다 RANGE로 분할하여 각각 정해진 수의 고객을 포함하는 합리적인 수의 파티션을 선택하는 것이 더 나을 수 있다.
하위 파티션은 다른 파티션보다 커질 것으로 예상되는 파티션을 더 분할하는 데 유용할 수 있다. 또 다른 옵션은 파티션 키에 여러 열이 있는 범위 분할을 사용하는 것이다. 이 중 어느 것이든 파티션의 수가 과도하게 늘어날 수 있으므로 파티션의 개수를 제한하는 것이 좋을 수도 있다.
쿼리 계획 및 실행 중에 파티션 오버헤드를 고려하는 것이 중요하다. 일반적인 쿼리를 통해 쿼리 계획이 작은 수의 파티션을 제외한 모든 파티션을 제거할 수 있다면 쿼리 실생 계획은 일반적으로 최대 수천 개의 파티션으로 파티션 계층 구조를 상당히 잘 처리할 수 있다. 플래너가 파티션 정리를 수행한 후에도 더 많은 파티션이 남아 있으면 계획 시간은 길어지고 메모리 소비량은 더 많아진다. 이는 UPDATE 및 DELETE 명령의 경우에 특히 해당된다. 많은 수의 파티션을 갖는 것에 대해 우려해야 하는 또 다른 이유는 서버의 메모리 사용량이 시간이 지남에 따라 크게 증가할 수 있으며, 특히 많은 세션이 많은 수의 파티션을 스캔하는 경우 더욱 그렇다. 이는 각 파티션이 해당 파티션에 닿는 각 세션의 로컬 메모리에 메타데이터를 로드해야 하기 때문이다.
데이터 웨어하우스 유형의 워크로드에서는 OLTP 유형의 워크로드보다 더 많은 수의 파티션을 사용하는 것이 합리적이다. 일반적으로 데이터 웨어하우스에서는 쿼리 실행 중에 대부분의 처리 시간이 소요되므로 쿼리 계획 시간은 그다지 중요하지 않다. 이러한 두 가지 워크로드 유형 중 하나를 사용하면 대량의 데이터를 다시 분할하는 작업이 매우 느릴 수 있으므로 올바른 결정을 조기에 내리는 것이 중요하다. 의도된 워크로드의 시뮬레이션은 파티셔닝 전략을 최적화하는 데 종종 유용합니다. 더 많은 파티션이 더 적은 수의 파티션보다 낫다고 가정하거나 그 반대의 경우를 가정하면 안 된다
참고
https://www.postgresql.org/docs/10/ddl-partitioning.html
https://www.postgresdba.com/bbs/board.php?bo_table=B10&wr_id=64
'Database > DB' 카테고리의 다른 글
| postgresql 한글 order by의 기준 (0) | 2023.03.08 |
|---|---|
| postgresql SQL Error [42P10]: ERROR: there is no unique or exclusion constraint matching the ON CONFLICT specification (0) | 2022.11.10 |
| 파티션 개념 (1) | 2021.06.21 |
| 객체 지향 데이터베이스 (OODB / object-oriented Database) (2) | 2021.06.18 |
| LeetCode sql 문제, 유저별 월별 집계 (0) | 2021.05.20 |


