일관된 해싱은 여러 스토리지 서버 간에 데이터를 분할하여 스토리지 시스템의 확장성을 구현하기 위해 수행된다.
많은 서버 (데이터베이스 서버+ 파티션)에 많은 데이터가 분산되어 있고 사용 가능한 서버 수가 지속적으로 변경되는 경우 (서버 추가 또는 서버 제거) 일관된 해싱을 사용한다.
단순 해싱을 쓸 수 없는 이유
간단한 해싱은 데이터와 지정된 키를 모듈러 함수를 통해 지정된 범위의 숫자로 생성한다. 모듈러 함수로 md5 사용한다면 0~2^128−1 범위에서 임의의 값을 얻을 수 있다.
이제 우리의 해시 함수는 server_number = hash(key)%n 로 계산된다. 이것은 [0- (n-1)] 범위로 제공하며 n은 서버의 수가 된다.
이렇게 하면 서버수에 따라 데이터가 완벽하게 나뉜다.
value를 3대의 서버로 나누기 위해 n=3으로 설정하고 계산하면 다음과 같다.
Example -> number of servers, n = 3 and we have 6 keys
keys hash value server_number(hashing)
key1 100 1 ( 100%3 == 1 )
key2 577 1 ( 577%3 == 1 )
key3 872 2 ( 872%3 == 2 )
key4 376 0 ( 376%3 == 0 )
key5 23 2 ( 23 %3 == 2 )
key6 6798 0 (6798%3 == 0 )위의 server_number(hashing)에 따라 3 개의 서버에 키가 배포되는 방법이다.
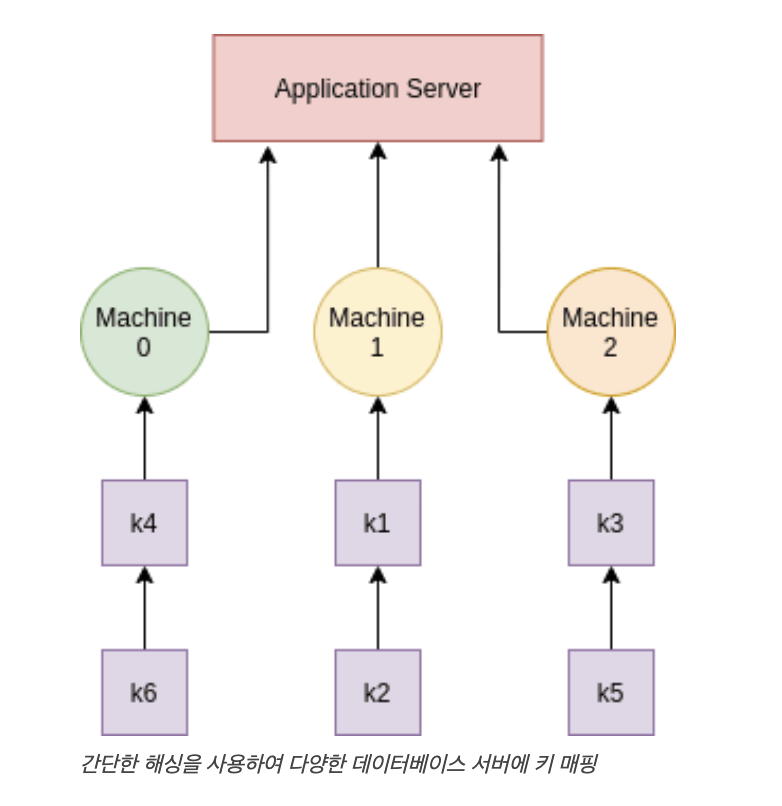
이때 새로운 서버가 추가되면 문제가 발생한다.
새 서버에도 키를 추가해야 하며 이를 위해 각 키의 서버 번호를 찾기 위해 모든 해시를 다시 계산해야 하므로 (서버 대수 = 4) 데이터의 위치가 변경된다.
n=4로 설정 후 다시 계산하면 다음과 같다.
Example -> number of servers, n = 4 and we have 6 keys
keys hash value server_number(hashing)
key1 100 0
key2 577 1
key3 872 0
key4 376 0
key5 23 3
key6 6798 2
또 한가지 문제는 서버가 제거될 때 발생한다. 이때에도 해시(갱신된 서버 개수)를 다시 계산해야 한다.
우리가 직면하게 될 문제는 데이터의 쏠림이다. 한 서버엔 너무 많은 키가 할당되어 있고, 다른 서버의 데이터는 너무 적거나 키가 균일하지 않게 배포됩니다. (한쪽으로 쏠림)

단순 / 일반 해싱에서 직면하는 주요 문제 :
- 서버 추가 시 다시 계산 후 할당
- 서버 제거 시 다시 계산 후 할당
- 키의 비균일 분포
일관된 해싱
일관된 해싱은 재구성이 최소화되는 방식으로 노드/서버 집합에 데이터를 배포 방식이다.
일관된 해싱은 노드 or 서버 수에 독립적으로 작동한다.
가상 링이 형성되고 서버가 링 주위에 분산되어 있다고 가정한다.
해시 함수는 position = hash (key) % (2 ^ 32)라고 정의한다. 여기서 2 ^ 32는 위치의 수 (또는 링 길이이면서 데이터가 들어갈 수 있는 크기)이고 완전히 임의의 숫자이므로 원하는 만큼 많은 수를 선택할 수 있다
링 서버 (데이터베이스 서버) 및 키 위치 찾기
- 서버의 위치를 찾기 위해 고유번호(ex:서버의 IP 주소, 혹은 서버 번호)를 해시를 취한 다음 위의 해시 함수를 사용하여 위치를 계산할 수 있다.
- 링의 계산된 위치에 서버를 놓는다
- 키와 동일한 해시값을 갖는 서버에 키를 매핑한다 (키 해시 값 == 서버 해시 값).
- 키 해시 값이 어떤 서버와도 일치하지 않는 경우 키는 시계 방향으로 가장 가까운 서버에 매핑된다.

링에 새 서버 추가
새 서버를 추가 시 서버의 해시 값(machine 4)이 서버 0과 서버 1 사이에 있다고 가정해 보자.
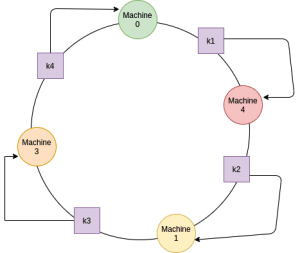
새 서버를 추가한 결과 모든 키 값을 다시 해시할 필요가 없으며 서버 0과 서버 1 사이에 있는 데이터만 다시 해시 값을 통해 재 할당된다. n 개의 서버와 k 개의 키가 있는 경우 k/n개의 키만 다시 해시하면 된다. 전체 데이터를 해시값을 다시 계산한 단순 해싱에 비해 상당히 개선되었다
링에서 서버 제거
서버 2가 다운 or 삭제되었다면, 그 안에 저장된 데이터는 시계 방향으로 인접한 서버에 저장된 키만 다시 할당한다.

비균일 분포
대부분의 키가 단일 시스템 또는 단일 서버 근처에 해시되었을 때 (데이터 쏠림) 하나의 서버가 다른 모든 서버에 비해 더 많은 키를 가지고 있기 때문에 이상적이지 않다.

이 문제를 극복하기 위해 가상의 복제본 서버를 도입한다.(아래의 그림에서 machine0의 대수가 세대, machine 1은ㅇ 두대, machine3은 두대가 되었다) 복제본 서버(vnode라고 부른다)를 도입하고 서버의 각 복제본은 다른 값으로 해시된다. 즉, 더 많은 머신이 임의의 위치에 링에 배치됨을 의미한다. 이러한 복제본의 수가 증가함에 따라 배포는 점점 더 균일해진다.

일관된 해싱 (Consistent hash) 알고리즘은 1997년 Karger가 개발했다. 웹 캐시를 구현하기 위해서 개발했는데, 캐시 노드의 추가와 삭제에 관계없이 높은 수준의 웹 히트율을 보장한다. 분산 캐시, 분산 스토리지, 라우팅, 분산 요청 처리 등 다양한 영역에서 사용하고 있다.
번외 확장된 consistent hash
Jump consistent hash
Google에서 공개한 해쉬 알고리즘. A Fast, Minimal Memory, Consistent hash Algorithm
아래는 jump consistent hash의 작동방식을 묘사한 그림이다.

말판 놀이를 한다고 가정해보자. Bucket size는 목적지까지의 거리다. Key는 말이다. 특수하게 제작된 주사위를 던져서 말을 앞으로 전진시켜서, 몇 번만에 목적지를 뛰어넘는지를 계산한다. 물론 멀리 뛸 확률은 점점 줄어든다. 이 확률을 1/N(거리)로 맞추면, 공정한 게임판을 만들 수 있다. 목적지까지의 거리(버킷 크기)가 4라면 1, 1/2, 1/3, 1/4의 확률을 가진다. 이 주사위를 매 판마다 던지면 된다.
이 말판 놀이의 핵심은 주사위 설계에 있다. 이 주사위는 대략 아래와 같은 모습을 가질 거다.

1을 만나기 전까지 0의 개수가 전진할 수 있는 칸의 숫자다.(반대로 해도 상관없다.) 그리고 0칸 이동(제자리)이 나올 경우에 한 칸을 이동할 수 있도록 규칙을 추가한다. 그러면 가장 재수 없는 경우에도 N(거리)만큼 주사위를 던지는 걸로 목적지에 도착할 수 있을 거다. 이 주사위를 여러 번 던지면, Jump 시퀀스를 만들 수 있다.
int32 _t JumpConsistentHash(uint64_t key, int32_t num_buckets) {
int64_t b =-1, j = 0;
while (j < num_buckets) {
b = j;
key = key * 2862933555777941757ULL + 1;
j = (b + 1) * (double(1LL << 31) / double((key >> 33) + 1));
}
return b;
}- num_buckets : 버켓의 크기다.
- while j < num_buckets : 점프를 했는데, 버켓의 크기를 넘어갔다면 현재 위치를 반환한다. 이 값이 클라이언트가 향할 노드의 위치다.
- key = key * 2862933555777941757 ULL + 1 : unsigned long long 64bit 데이터다. 이 녀석을 2진수로 변환하면
10011110111011001011101110011010000111101100001011000011111101이 된다. 2862933555777941757은 2^63보다 더 큰 값이다. 요 녀석을 double((key >> 33)) 연산을 해서, double로 형 변환을 하면, 랜덤 한 값을 얻을 수 있다. 이 값을 분모로 해서 나누기 연산을 하면, 1/N로 확률이 감소하는 주사위를 얻을 수 있다.
- b는 이전 칸의 위치다.
버킷이 1 늘어날 경우, 기존의 Key들이 새로운 버킷으로 할당될 확률은 1/N이 되기 때문에, Consistent hash의 조건을 만족한다.
결론 : 엄청 균등한 확률로 어떤 버킷에 들어갈지 결정한다. (서로의 확률이 비슷하기 때문에 한쪽으로 쏠리지 않는다)
참고
https://www.popit.kr/consistent-hashing/
https://nlogn.in/consistent-hashing-system-design/
https://www.joinc.co.kr/w/man/12/hash/consistent
https://www.popit.kr/jump-consistent-hash/
'server > 아키텍쳐' 카테고리의 다른 글
| airflow scheduler high cpu usage (1) | 2021.11.29 |
|---|---|
| 캐시 (0) | 2021.07.14 |
| airflow 시간대가 다른 두개의 dag을 ExternalTaskSensor 사용하기 (0) | 2021.04.16 |
| 코딩을 하기전 해야할 일들 (0) | 2018.12.28 |
| web developer roadmap (0) | 2018.12.20 |

