자연어 representation ML 흐름
1. 단어 임베딩
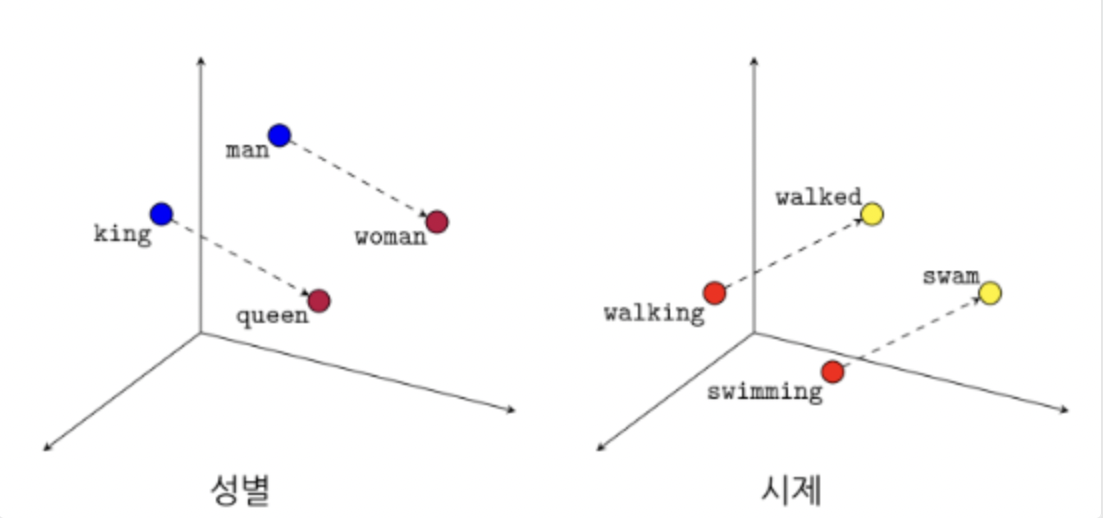
단어를 숫자로 표현하는것 == 단어의 벡터값를 보면 그 단어를 안다
단어와 단어의 의미를 수치화 했지만, 문장의 의미는 알수가 없음
2. RNN & seq2seq
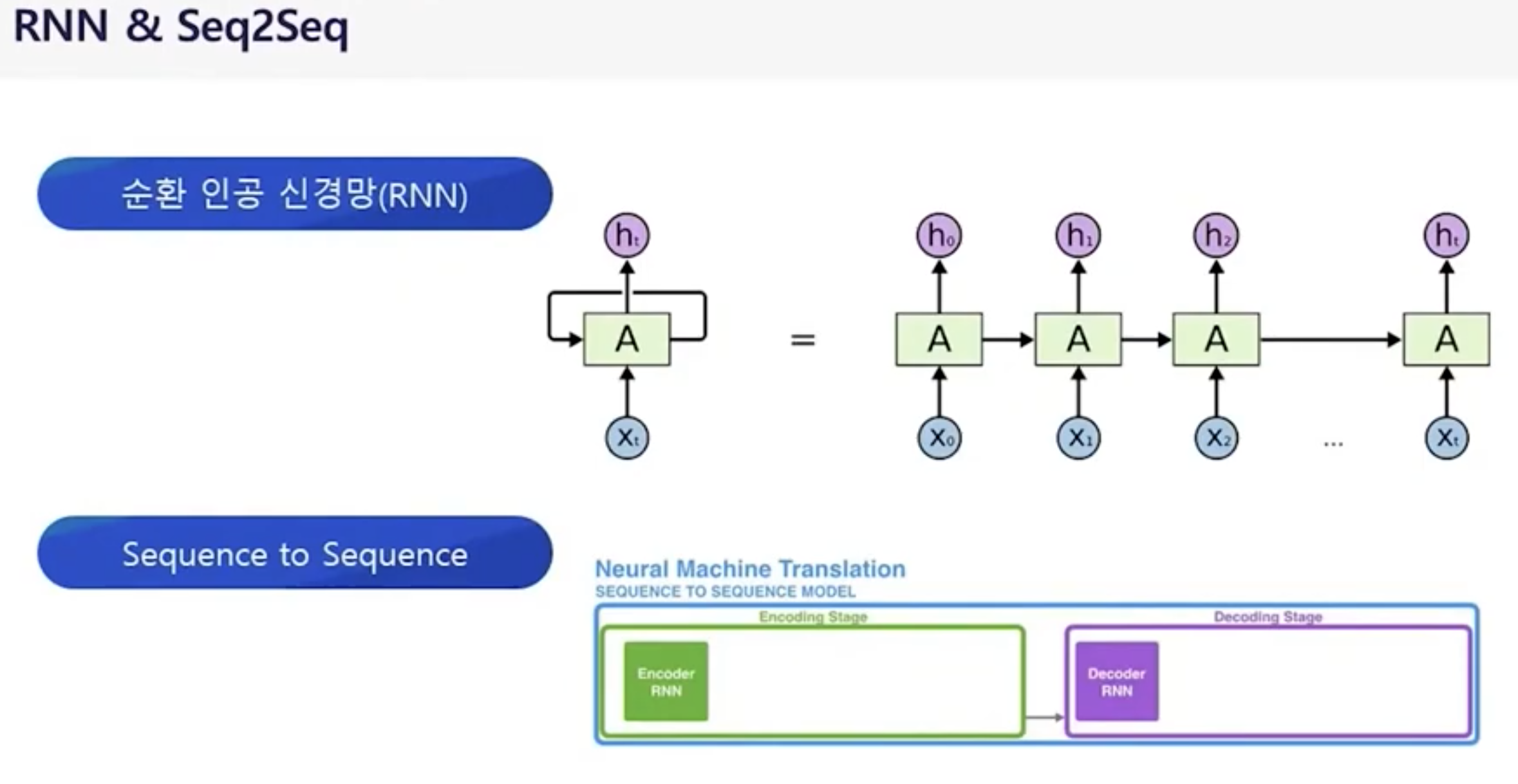
RNN == 데이터를 순서대로 넣으면(입력값) 값이 잘 나오네?
*인코더 -> 압축 / 디코더 -> 확대
seq2seq == 문장(질문)의 단어를 순서대로 넣으면 문장(답변)을 순서대로 나오게끔!
- 순서대로 넣는건 입력값이 많아질수록 연산량이 폭팔적으로 증가 (무조건 순서대로 연상하므로 병렬 불가 ) -> 문장이 길어지면 앞에 값에 대한 의미가 사라짐 -> 순서가 들어간건 좋은데, 너무 많은 양은 어떻게 처리하지??
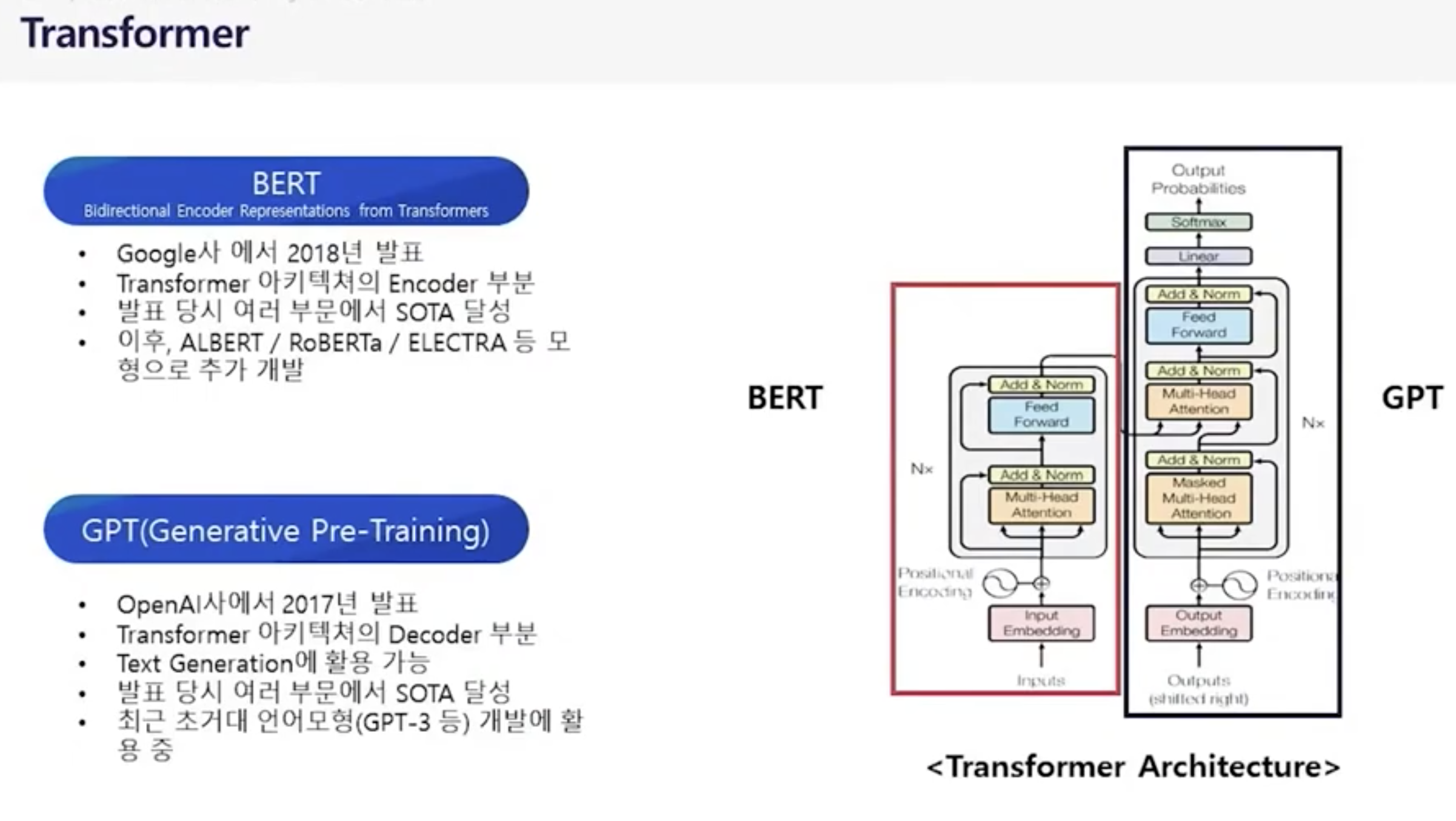
3. 트랜스퍼머

트랜스포머 == 순서대로 넣긴하는데, 위치정보도 같이 넣어준다
모든 값(문장)을 한방에 넣어준다.
-> 병렬 처리 가능
-> 뒤의 연산에서도 앞의 데이터에 대한 의미를 가질수 있음
4. BERT && GPT
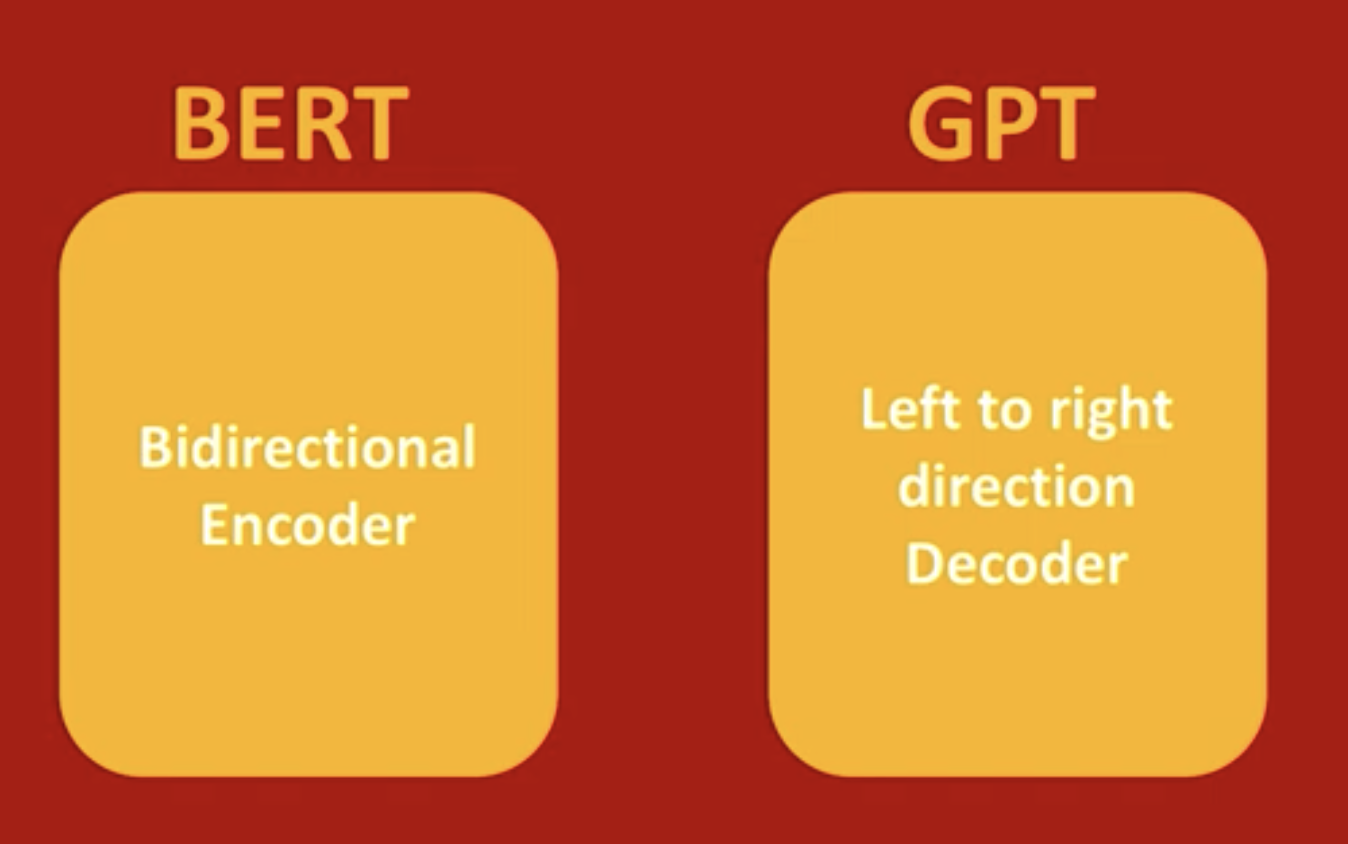
문맥을 양방향으로 이해하는 딥러닝 모델!!

bert -> 분류 == 언어의 이해하고 정량화 (output : 숫자)
gpt -> 생성 == 언어의 생성 (output : 글 )
GPT
앞 단어만 있어도 뒤의 단어를 예측 (left to right)
사람이 필요없는 비지도 학습으로 입력값만 많으면 엄청나게 학습이 가능!!
구글 : gpt는 한방향으로만 학습하기 때문에 저거 안될거 같은데?
한방향 디코더보다 양방향 인코더가 더 좋은거 같은데? 우리가 만들어 보겠음


BERT
질의 + 답변을 한방에 넣어서 학습
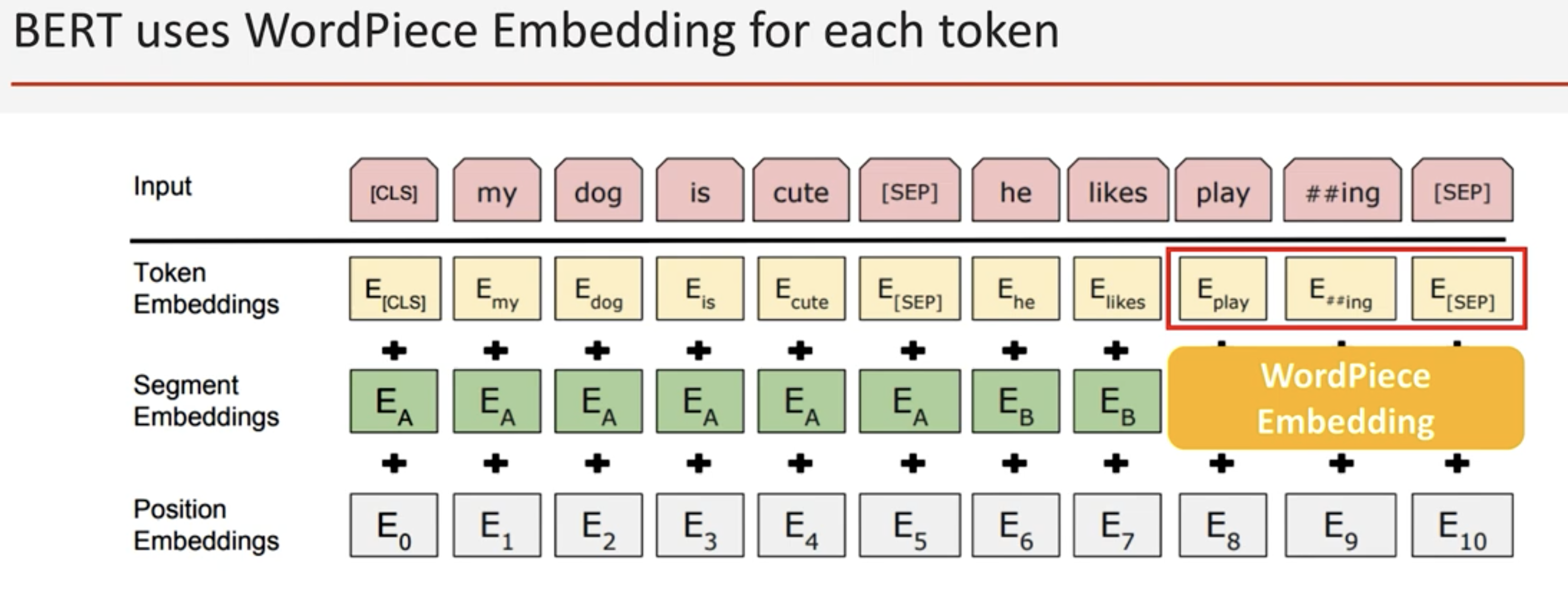
각 단어들을 워드피스로 쪼개서 학습 (모르는 단어들도 학습가능)
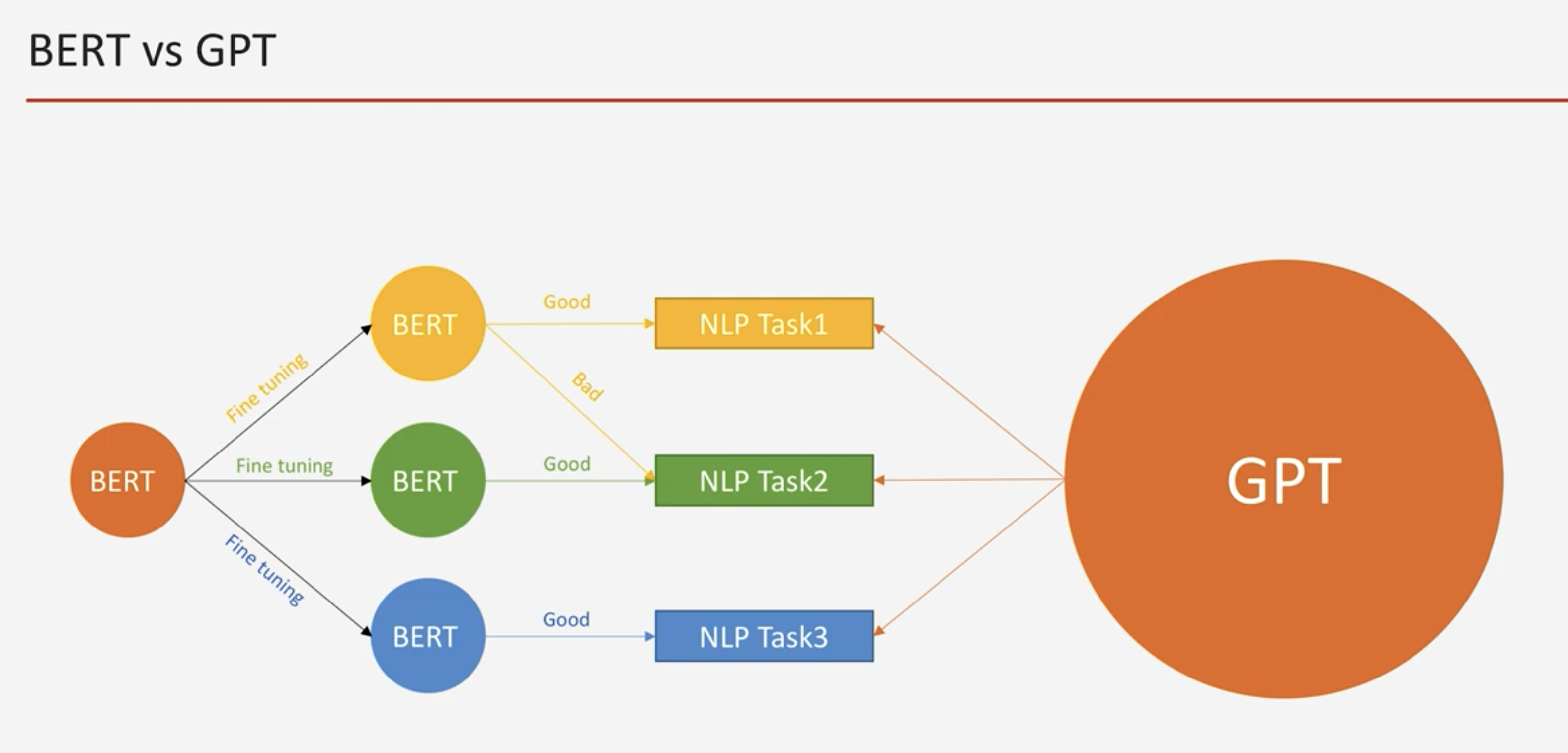
GPT : 모델이 엄청나게 큼
각각의 문제를 하나의 모델로 해결 가능함
find turing 불필요 (개발자 꺼져)
BERT : pretring 모델이 작음
각각의 문제를 해결하기 위해 따로 find turing이 필요 (개발자 필요)
'ML > 인공지능' 카테고리의 다른 글
| [사내 해커톤] ocr + gpt를 이용한 식품 성분 분석 및 추천 (0) | 2024.03.28 |
|---|---|
| [사내 해커톤] Stable Diffusion을 이용한 영상 가공 (0) | 2024.02.25 |
| openapi chatGPT 사용기 (0) | 2022.12.12 |
| 이상감지 소스 및 간략 설명 (0) | 2021.07.02 |
| 이상감지 (정리) (0) | 2021.05.25 |


