https://arxiv.org/pdf/1907.11692
결론
기존 BERT 성능을 다음을 통해 향상 시킬 수 있었음
• 더 많은 데이터에 대한 더 큰 배치 사이즈를 사용해 더 오래 학습
• NSP 삭제
• Dynamic Masking
• 더 많은 sequence로 학습을 통해성능 향상
요약
언어 모델 사전 학습은 상당한 성능 향상을 가져왔지만 다양한 접근 방식을 신중하게 비교하기는 어렵습니다. 훈련은 계산 비용이 많이 들고, 종종 다양한 크기의 비공개 데이터 세트에서 수행되며, 많은 주요 하이퍼파라미터와 학습 데이터 크기의 영향을 측정합니다. 그 결과, BERT는 훈련이 상당히 부족했으며, 그 이후에 발표된 모든 모델의 성능과 일치하거나 능가할 수 있는 것으로 나타났습니다.
이전에 간과되었던 설계 선택의 중요성을 강조하고 최근 보고된 개선의 원천에 대한 의문을 제기합니다.
하이퍼파미터 튜닝과 훈련 세트 크기의 효과에 대한 면밀한 평가가 포함된 BERT 사전 훈련를 발표합니다. 그 결과, BERT의 훈련이 상당히 부족하다는 사실을 발견하고 모든 BERT 이후 방법의 성능과 비슷하거나 능가할 수 있는 개선된 BERT 모델 훈련 레시피(RoBERTa)를 제안했습니다.
(1) 더 많은 데이터에 대해 더 큰 배치로 더 오랜 모델 훈련
(2) 다음 문장 예측 목표 제거
(3) 더 긴 시퀀스에 대한 훈련
(4) 훈련 데이터에 적용되는 마스킹 패턴 동적 변경
4.1 Static vs. Dynamic Masking
Dynamic Masking
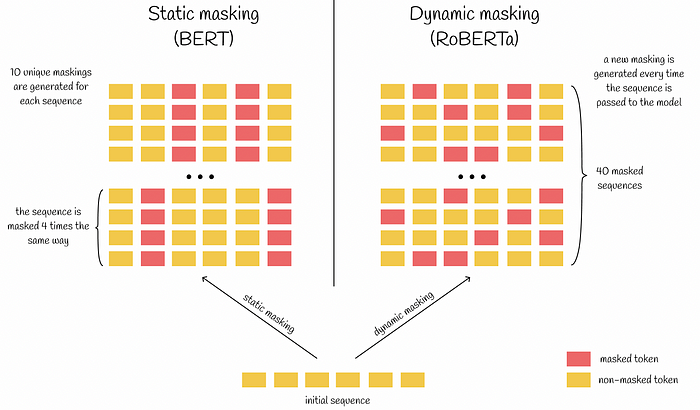
- 기존의 BERT는 data preprocessing과정에서 masking을 한번 수행.
- 본 논문에서는 data 10개를 각 sequencerk 40 epoch에 걸쳐 10가지 방법으로 masking되도록 처리.
- 동일한 mask는 4번만 보게 됨. 이 전략은 큰 데이터셋을 pre-train할때 중요함.
4.2 Model Input Format and Next Sentence Prediction
NSP(Next Sentence Prediction) : 기존 BERT의 pretrain 절차에서 모델은 동일한 문서에서 연속적으로 샘플링되거나(p = 0.5) 서로 다른 문서에서 샘플링된 두 개의 연결된 문서 세그먼트를 관찰합니다. 세그먼트가 동일한 문서에서 나온 것인지 아니면 별개의 문서에서 나온 것인지 예측하도록 훈련됩니다.
NSP를 제외하면 성능이 크게 저하된다고 여겼으나, NSP를 제거해도 성능에 문제 없음을 위해 다음의 실험을 진행
- SEGMENT-PAIR+NSP: 기존 bert + NSP
- SENTENCE-PAIR+NSP: 각 입력에는 document의 인접부분 또는 다른 document의 sentence 쌍으로 구성됨
- FULL-SENTENCES: 각 입력은 하나 이상의 document에서 연속적으로 sampling된 전체 sentence / NSP는 사용하지 않음.
- DOC-SENTENCES: 입력이 document 경계를 넘을 수 없다는 점을 제외하고 FULL-SENTENCES와 유사하게 구성 / NSP는 사용하지 않음.

DOC-SENTENCES가 성능이 젤 좋았지만, FULL-SENTENCES를 사용해 다른 실험군과 비교
4.3 Training with large batches
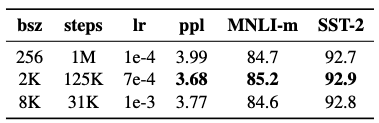
큰 batch로 training을 진행하는 것이 MLM을 위한 복잡도 뿐만 아니라 end-task의 정확도를 향상시킨다는 것을 알 수 있다
4.4 Text Encoding
기존 BERT는 character level BPE 방식을 사용했지만 RoBERTa는 Byte Level BPE를 사용함 (GPT-2도 Byte Level BPE 사용)
character level BPE : BPE는 pre-tokenizer(공백기준분리)에 token을 문자단위(character-level)로 쪼갠 것들의 집합
5. RoBERTa
이제까지 살펴본 dynamic masking, NSP 제거, large mini batch, Byte-level BPE를 통합하여 training을 진행하고, 그 영향을 평가한다. 저자들은 이러한 configuration을 Robustly optimized BERT approach(RoBERTa)라고 명명한다
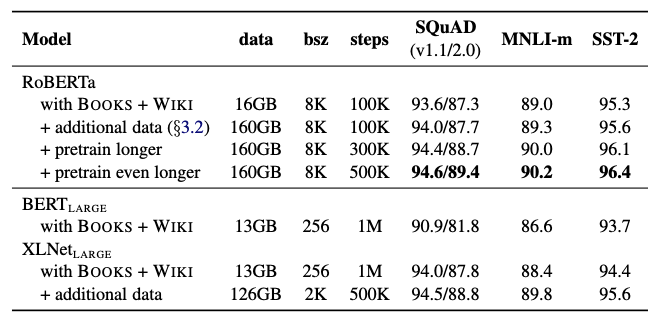
GLUE, SQuAD, RACE 이렇게 세 가지 벤치마크에 대해서 실험했을 때 모두 SOTA를 달성.
비교 모델로는 Masked-LM objective를 이용하면서 다른 구조를 가진 모델인 XLNet과 기존의 BERT를 사용
7. Conclusio
- 더 많은 데이터에 대한 더 큰 배치 사이즈를 사용해 더 오래 학습
- NSP 삭제
- Dynamic Masking
- 더 긴 sequence로 학습을 통해성능 향상
https://junnyhi.tistory.com/221
'ML > 인공지능' 카테고리의 다른 글
| bigquery ML 분류 (긍정/부정) - 영어 (1) | 2025.07.13 |
|---|---|
| bigquery ML Titanic (1) | 2025.06.24 |
| [논문 리뷰] SPLADE: Sparse Lexical and Expansion Modelfor First Stage Ranking (0) | 2024.04.09 |
| [논문 리뷰]ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT (1) | 2024.04.07 |
| [논문 리뷰] T-RAG: LESSONS FROM THE LLM TRENCHES (0) | 2024.03.30 |



