https://storage.googleapis.com/gweb-research2023-media/pubtools/4443.pdf
Introduction
Bigtable은 대규모(페타바이트 단위) 구조화된 데이터를 관리하기 위한 분산형 스토리지 시스템입니다.
웹 인덱싱, Google 어스, Google 파이낸스 등 Google의 많은 프로젝트에서 Bigtable에 데이터를 저장하고 있습니다. Bigtable은 광범위한 적용성, 확장성, 고성능, 고가용성 등 여러 가지 목표를 달성했습니다.
여러 면에서 Bigtable은 데이터베이스와 유사하지만 완전한 관계형 데이터 모델을 지원하지는 않습니다. 클라이언트에 데이터 레이아웃과 형식에 대한 동적 제어를 지원하는 간단한 데이터 모델을 제공합니다.
빅테이블 스키마 매개변수를 통해 클라이언트는 데이터를 메모리에서 제공할지, 디스크에서 제공할지 동적으로 제어할 수 있습니다.
2 Data Model
빅테이블은 희소하고 분산된 영구적인 다차원 정렬 맵입니다. 맵은 행 키, 열 키, 타임스탬프로 인덱싱됩니다.
(row:string, column:string, time:int64) → string
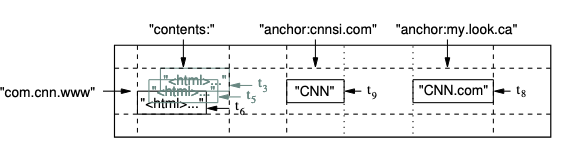
Rows
테이블의 행 키는 임의의 문자열입니다. 단일 행 키 아래의 모든 데이터 읽기 또는 쓰기는 원자적입니다. 빅테이블은 행 키별로 사전적 순서로 데이터를 유지합니다.
테이블의 행 범위는 동적으로 분할됩니다. 각 행 범위를 태블릿이라고 하며, 이는 배포 및 로드 밸런싱의 단위입니다.
Column Families
Column 키는 Column Families라는 집합으로 그룹화됩니다. Column Families는 액세스 제어의 기본 단위입니다.
Column Families에 저장된 모든 데이터는 일반적으로 동일한 유형이며 일반적으로 압축됩니다.
데이터를 저장하기 전에 ColumnFamilies를 생성해야 합니다. 빅테이블 팀은 테이블에 포함된 Column Families의 개수를 적게(많아야 수백 개) 만들 것을 권장합니다.
Column 키의 이름은 다음과 같은 구문을 사용하여 지정합니다: family: qualifier 액세스 제어와 디스크 및 메모리 계정은 Column Families에 저장됩니다.
Timestamps
빅테이블의 각 셀에는 동일한 데이터의 여러 버전이 포함될 수 있습니다. 이러한 버전은 타임스탬프를 기준으로 색인화됩니다. 빅테이블 타임스탬프는 64비트 정수입니다. 셀의 다른 버전은 타임스탬프가 줄어드는 순서로 저장됩니다.
빅테이블은 마이크로초 단위의 시간인 타임스탬프를 할당할 수 있습니다. 사용자가 직접 순서를 정의할 수도 있습니다.
셀 버전을 자동으로 가비지 수집하도록 Bigtable에 지시하는 두 가지 column Families별 설정이 있습니다.
Building Blocks
Google SSTable 파일 형식은 내부적으로 Bigtable 데이터를 저장하는 데 사용됩니다. SSTable은 키와 값이 모두 임의의 바이트 문자열인 키에서 값으로 정렬된 불변의 맵입니다.
내부적으로 각 SSTable은 블록 시퀀스를 포함합니다. 블록 인덱스는 블록을 찾는 데 사용됩니다. SSTable을 사용하는 방법에는 두 가지가 있습니다.
1. 인덱스는 SSTable이 열릴 때 메모리에 로드됩니다. 이 경우 조회에는 디스크 검색이 한 번 필요합니다. 먼저 인메모리 인덱스에서 적절한 블록을 찾은 다음 디스크에서 적절한 블록을 읽습니다.
2. 전체 SSTable이 메모리에 매핑됩니다. 그러면 디스크 탐색 없이 조회를 수행할 수 있습니다.
Chubby는 가용성이 높고 영구적인 분산 잠금 서비스입니다. 맥락상 ZooKeeper는 Chubby 잠금 서비스를 모델로 하고 있습니다.
Chubby 서비스는 5개의 활성 복제본으로 구성되며, 이 중 하나가 마스터로 선출되어 요청을 적극적으로 처리합니다. Chubby는 Paxos 알고리즘을 사용하여 복제본의 일관성을 유지합니다.
Chubby는 디렉터리와 작은 파일로 구성된 네임스페이스를 제공합니다. 각 디렉터리 또는 파일은 잠금으로 사용할 수 있으며, 파일에 대한 읽기와 쓰기는 원자적입니다. 각 Chubby 클라이언트는 Chubby 서비스에서 세션을 유지합니다. 클라이언트의 세션이 만료되면 모든 잠금과 열린 핸들을 잃게 됩니다. Chubby 클라이언트는 변경 또는 세션 만료 알림을 위해 Chubby 파일 및 디렉터리에 콜백을 등록할 수도 있습니다.
Implementation
모든 클라이언트에 연결된 라이브러리 하나의 마스터 서버 다수의 태블릿 서버
시스템의 핵심은 마스터 서버이며, 마스터 서버는 다음과 같은 작업을 수행합니다:
-태블릿 서버에 태블릿 할당
-태블릿 서버의 추가 및 만료 감지
-태블릿 서버 부하 분산
-GFS에서 파일 가비지 수집
-스키마 변경 처리(테이블 및 column Families 생성)
각 태블릿 서버는 태블릿 세트(10~1,000개)를 관리합니다. 태블릿 서버는 태블릿에 대한 읽기 및 쓰기 요청을 처리합니다. 너무 커진 태블릿을 분할합니다.
처음에는 각 테이블이 하나의 태블릿으로만 구성됩니다. 테이블이 커지면 기본적으로 약 100~200MB 크기의 여러 개의 태블릿으로 자동 분할됩니다.
Tablet Location
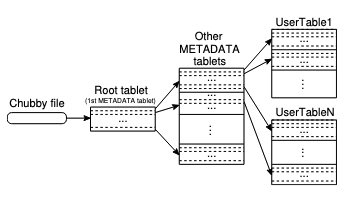
빅테이블은 위 그림과 같이 3단계 계층 구조를 사용하여 태블릿 위치 정보를 저장합니다.
- 첫 번째 레벨은 루트 태블릿의 위치가 포함된 Chubby에 저장된 파일입니다.
- 루트 태블릿에는 고유한 메타데이터 테이블에 모든 태블릿의 위치가 포함되어 있습니다.
- 각 메타데이터 태블릿에는 사용자 태블릿 세트의 위치가 포함되어 있습니다.
루트 태블릿은 메타데이터 테이블의 첫 번째 태블릿일 뿐이며 절대로 분할되지 않습니다. 메타데이터 테이블은 행 키 아래에 태블릿의 위치를 저장합니다.
태블릿 위치는 메모리에 저장되므로 GFS 액세스가 필요하지 않다는 점을 기억해야 합니다. 또한 클라이언트 라이브러리는 태블릿 위치를 미리 가져올 수 있습니다.
5.2 Tablet Assignment
각 태블릿은 한 번에 하나의 태블릿 서버에 할당됩니다. 마스터는 이를 추적합니다.
태블릿이 할당되지 않고 충분한 공간을 가진 태블릿 서버를 사용할 수 있게 되면 마스터가 태블릿을 할당합니다.
빅테이블은 Chubby를 사용하여 태블릿 서버를 추적합니다. 태블릿 서버가 시작되면 지정된 Chubby 디렉토리에 있는 고유한 이름의 파일을 생성하고 exclusive lock을 획득합니다. 태블릿 서버는 exclusive lock을 잃으면 태블릿 서비스를 중단합니다.
태블릿 서버는 파일이 여전히 존재하는 한 해당 파일에 대한 exclusive lock을 다시 획득하려고 시도합니다. 파일이 더 이상 존재하지 않으면 태블릿 서버는 다시는 서비스를 제공할 수 없으므로 스스로 종료됩니다.
마스터는 태블릿 서버가 더 이상 태블릿을 제공하지 않는 시기를 감지하고 가능한 한 빨리 태블릿을 재할당할 책임이 있습니다. 마스터는 주기적으로 각 태블릿 서버에 잠금 상태를 요청합니다.
태블릿 서버가 잠금을 잃어버렸다고 보고하거나 마스터가 서버에 연결할 수 없는 경우, 마스터는 서버의 파일에 대한 독점 잠금을 획득하려고 시도합니다.
시작 시 마스터는 현재 태블릿 할당을 검색해야 합니다. 다음 단계를 수행합니다
1 마스터가 Chubby에서 고유한 마스터 잠금을 가져옵니다.
2 마스터는 Chubby에서 서버 디렉터리를 스캔하여 라이브 태블릿 서버를 찾습니다.
3 마스터는 모든 라이브 태블릿 서버와 통신하여 각 서버에 어떤 태블릿이 할당되어 있는지 확인합니다.
4 마스터는 메타데이터 테이블을 스캔하여 태블릿 세트를 학습합니다.
위의 과정에서 마스터가 아직 할당되지 않은 태블릿을 발견할 때마다 마스터는 할당되지 않은 태블릿 세트에 해당 태블릿을 추가합니다.
5.3 Tablet Serving

태블릿은 GFS에 유지됩니다.
태블릿 서버에 쓰기 작업이 도착하면 태블릿 서버가 진위 여부와 무결성을 확인합니다. 그 후 변경 내용이 커밋 로그에 기록됩니다. 쓰기가 커밋되면 그 내용이 멤테이블에 삽입됩니다.
읽기 작업이 태블릿 서버에 도착하면 태블릿 서버는 진위 여부와 무결성을 확인합니다. 그 후, 작업은 SSTables와 멤테이블의 시퀀스를 병합한 보기에서 실행됩니다.
이러한 읽기 및 쓰기 작업 외에도 태블릿 업데이트 및 태블릿 복구 작업이 있습니다.
업데이트는 재실행 레코드를 저장하는 커밋 로그에 커밋됩니다. 이러한 업데이트 중 최근에 커밋된 업데이트는 memtable이라는 정렬된 버퍼에 메모리에 저장되고, 이전 업데이트는 SSTable 시퀀스에 저장됩니다.
6 Refinements
블룸 필터
읽기 작업은 태블릿의 모든 SSTable에서 읽어야 하지만 데이터가 이 메모리에 없으면 많은 디스크 액세스 해야 합니다. SSTable에서 생성된 Bloom 필터를 사용하면 SSTable에 지정된 행/열 쌍에 대한 데이터가 포함되어 있는지 여부를 확인할 수 있습니다.
블룸 필터를 저장하는 데 사용되는 소량의 태블릿 서버 메모리는 읽기 작업에 필요한 디스크 검색 횟수를 크게 줄여줍니다
Scaling
시스템의 태블릿 서버 수를 1대에서 500대로 늘리면 총 처리량이 100배 이상 크게 증가합니다. 예를 들어, 태블릿 서버의 수가 500배 증가하면 메모리에서 무작위 읽기 성능이 거의 300배 증가합니다.
그러나 성능은 선형적으로 증가하지는 않습니다. 대부분의 벤치마크에서 태블릿 서버를 1대에서 50대로 늘릴 때 서버당 처리량이 크게 감소합니다. 이러한 성능 저하는 여러 서버 구성의 부하 불균형으로 인해 발생하며, 종종 다른 프로세스가 CPU와 네트워크를 차지하기 위해 경쟁하기 때문입니다. 로드 밸런싱 알고리즘은 이러한 불균형을 처리하려고 시도하지만 두 가지 주요 이유로 인해 완벽한 작업을 수행할 수 없습니다. 태블릿 이동 횟수를 줄이기 위해 리밸런싱이 조절되고벤치마크가 진행되면서 벤치마크에서 생성된 부하가 이동하기 때문입니다.
'server > system design' 카테고리의 다른 글
| [25 Computer Papers] 4. Cassandra - A Decentralized Structured Storage System (0) | 2024.09.21 |
|---|---|
| 레디스 트러블 슈팅 (1) | 2024.09.19 |
| [25 Computer Papers] 2. Dynamo: Amazon’s Highly Available key-value Store (1) | 2024.09.05 |
| [25 Computer Papers] 1. The Google File System (1) | 2024.09.04 |
| 쿠폰발급 서비스 구축하기 (실험용) (0) | 2022.08.12 |



