자연어 처리(NLP) 시스템, 추천 엔진, 검색 기반 시스템과 같은 머신 러닝(ML) 애플리케이션을 구축할 때, 일정 수준 이상의 규모가 되면 k-Nearest Neighbor(k-NN) 검색을 활용된다. 데이터가 수억 개에서 수십억 개까지 늘어나면, k-NN 검색을 확장하는 것이 큰 도전 과제가 된다.

이러한 문제를 해결하기 위해 Approximate k-Nearest Neighbor (ANN) 검색이 등장했다. ANN은 k-NN 문제의 일부 제약을 완화함으로써 검색 속도를 획기적으로 줄일 수 있는 방법을 제공한다.
벡터 검색을 이해하는 쉬운 방법은 전통적인 어휘 검색(Lexical Search) 과 비교해보자. 우리가 익숙한 엘라스틱서치의 어휘 검색은 사용자가 입력한 단어나 그 변형(어간, 동의어 등)을 찾아 TF-IDF와 같은 알고리즘을 사용하여 색인된 데이터와 비교하는 방식이다. 반면, 벡터 검색(의미 검색)은 단어나 문장의 실제 의미를 파악하고, 의미적으로 유사한 항목을 찾는 데 초점을 맞춘다.
k-NN 검색은 주어진 데이터 집합에서 쿼리 벡터와 가장 가까운 k개의 벡터를 찾는 문제이다. 단순히 모든 벡터와 거리를 계산하여 상위 k개를 선택하는 방식은 이해하기 쉽지만, 데이터가 커질수록 확장성이 문제가 된다. 기본적인 k-NN 알고리즘의 검색 복잡도는 O(N log k) 로, 데이터가 수백만 개 이상이 되면 속도가 급격히 저하된다.
ANN 검색은 이러한 한계를 극복하기 위해 색인 시간을 늘리고, 검색 시 더 많은 메모리를 사용하며, 완전한 정확성 대신 근사값을 반환하는 방식을 채택한다. 이를 통해 검색 속도를 획기적으로 개선할 수 있으며, 여러 가지 알고리즘을 활용하여 구현 되어 있다.
1. 브루트포스 (Exact kNN)
기본적으로 dense_vector 필드를 설정하면 브루트포스(Exact kNN, Exhaustive Search) 를 사용할 수 있다.
이 방식은 모든 벡터를 순차적으로 비교하여 가장 유사한 결과를 찾는 방식으로, 정확도는 높지만 검색 속도가 느릴 수 있다.
PUT my_index
{
"mappings": {
"properties": {
"my_vector": {
"type": "dense_vector",
"dims": 128,
"index": true,
"similarity": "l2_norm"
}
}
}
}
2. Hierarchical Navigable Small Worlds(HNSW) 알고리즘
* 자세한 사항은 논문 Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs 을 읽는것을 추천한다.
Hierarchical Navigable Small Worlds (HNSW) 알고리즘은 Approximate k-Nearest Neighbor (ANN) 검색에서 가장 널리 사용되는 방법 중 하나이다. 엘라스틱서치의 k-NN 플러그인이 최초로 지원한 알고리즘이며, nmslib 유사도 검색 라이브러리에서도 매우 효율적으로 활용된다
이 알고리즘 핵심 아이디어는 서로 가까운 벡터를 연결하는 계층적 그래프를 구축하여 검색을 최적화하는 것이다.
HNSW의 작동 방식
HNSW는 연결 그래프(connected graph) 를 사용하여 벡터 간 관계를 표현한다. 쿼리가 주어지면, 알고리즘은 이 그래프를 탐색하며 가장 가까운 이웃을 찾는다. 탐색 과정에서 항상 현재 위치에서 가장 가까운 후보를 선택하여 이동하는 방식으로 최적의 검색 속도를 유지한다.
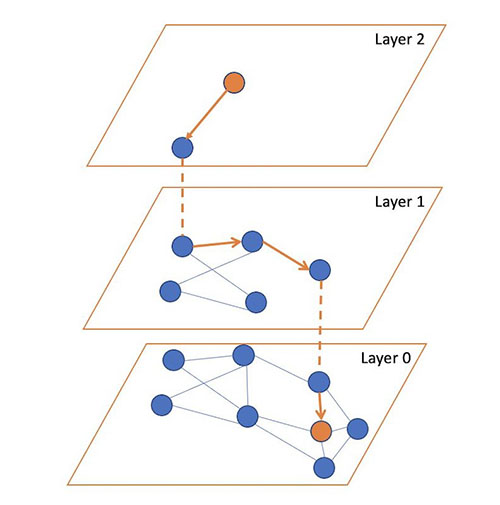
OpenSearch의 HNSW 알고리즘에 대해 세 가지 매개 변수를 조정할 수 있다.
- m – 벡터가 그래프에서 얻을 수 있는 최대 엣지의 수. 이 값이 클수록 그래프에서 더 많은 메모리를 사용하지만 검색시 근사치가 더 좋아질 수 있다.
- ef_search – 탐색 중에 방문할 후보 노드의 대기열 크기. 노드를 방문하면 해당 노드의 이웃 노드가 향후 방문할 대기열에 추가. 값이 클수록 검색 대기 시간은 증가하지만 검색시 근사치가 더 좋아질 수 있다.
- ef_construction – 탐색을 위한 후보 대기열 크기를 제어. 값이 클수록 인덱스 대기 시간은 증가하지만 더 나은 검색시 근사치를 제공할 수 있다.
PUT my_index
{
"mappings": {
"properties": {
"my_vector": {
"type": "dense_vector",
"dims": 128,
"index": true,
"similarity": "l2_norm",
"index_options": {
"type": "hnsw",
"m": 16, // 그래프 간선 개수 조정
"ef_construction": 200 // 인덱싱 시 검색 후보 개수
}
}
}
}
}
3. Inverted File System(IVF) 알고리즘
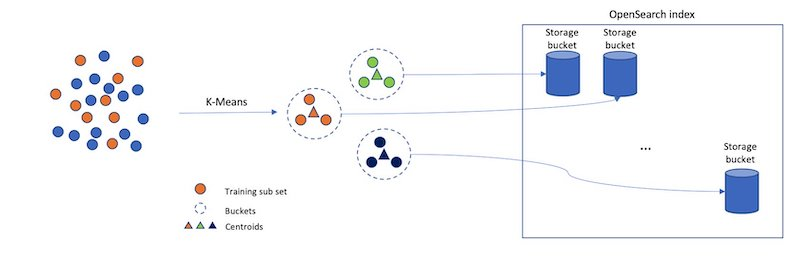
Inverted File System (IVF) 알고리즘은 벡터를 여러 버킷(bucket) 으로 나누어 검색 속도를 최적화하는 방법으로, 검색 시 전체 데이터셋을 탐색하는 대신, 특정 버킷만 조회하여 검색 시간을 단축할 수 있다.
es k-NN 플러그인은 Faiss의 IVF 구현을 지원하기 시작했다. [Faiss는 Meta에서 개발한 고밀도 벡터의 효율적인 유사도 검색 및 클러스터링을 위한 오픈소스 라이브러리]
IVF의 작동 방식
IVF의 핵심 아이디어는 벡터를 무작위로 나누는 것이 아니라, 유사한 벡터끼리 같은 버킷에 배치하는 것. 이를 위해 버킷마다 대표 벡터(centroid)를 설정하고, 새로운 벡터가 색인될 때 가장 가까운 대표 벡터를 가진 버킷에 저장되어 서로 유사한 벡터들이 동일하거나 인접한 버킷에 위치하게 된다.
PUT my_index
{
"mappings": {
"properties": {
"my_vector": {
"type": "dense_vector",
"dims": 128,
"index": true,
"similarity": "l2_norm",
"index_options": {
"type": "ivf",
"nlist": 100 // IVF 리스트 개수 조정
}
}
}
}
}
이외에도 정말 여러가지 알고리즘과 구현체가 있다. 자신의 상황에 맞게 골라서 써야한다...
자세한 사항은 아래의 링크들을 참조하길
끝!
참고 사항
https://ivoryrabbit.github.io/posts/IVF/
https://www.elastic.co/search-labs/blog/introduction-to-vector-search
'server > system design' 카테고리의 다른 글
| 인터넷 연결이 안되었는데 youtube 페이지는 어떻게 나오는걸까? (1) | 2025.02.05 |
|---|---|
| [3] 이력서 챗봇 만들기 - postgreSQL pg_vector (0) | 2025.02.03 |
| fastapi로 server sent event 구현 실습 (0) | 2025.01.28 |
| [2] 챗봇 프론트 화면을 만들어보자. (0) | 2025.01.24 |
| 게임 거래소 아키텍처 설계 (전세계 검색기) (0) | 2025.01.18 |


