resources:
requests:
cpu: 500m
memory: 512Mi
top - 05:43:42 up 1 day, 10:29, 0 users, load average: 0.64, 0.88, 1.29
Tasks: 5 total, 1 running, 4 sleeping, 0 stopped, 0 zombie
%Cpu(s): 6.8 us, 1.0 sy, 0.0 ni, 91.4 id, 0.2 wa, 0.0 hi, 0.6 si, 0.0 st
MiB Mem : 7945.9 total, 805.2 free, 3249.5 used, 3891.1 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 4355.2 avail Mem
CPU는 6% 메모리는 50% 정도를 사용하고 있다.
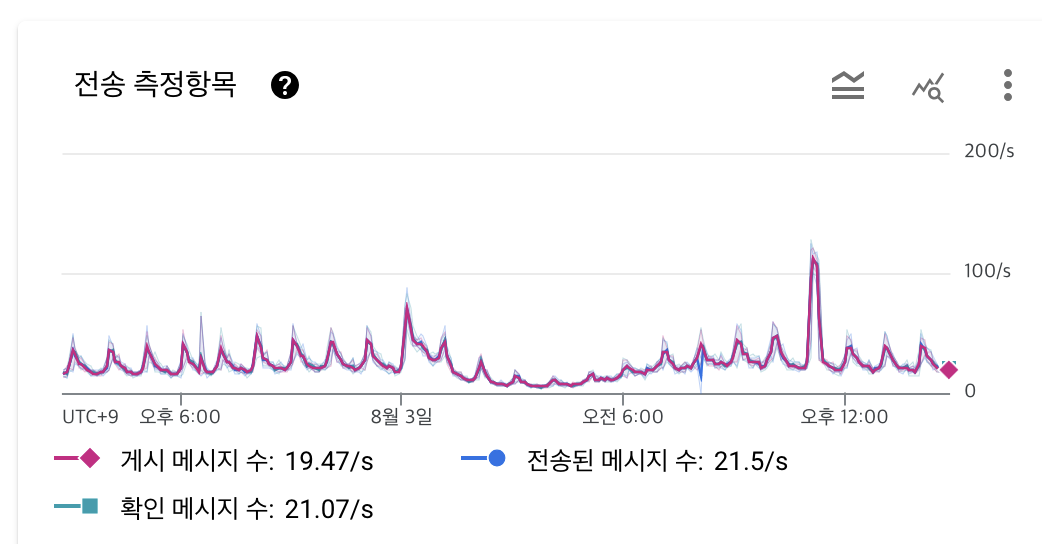
평소때는 초당 20개씩 쌓이지만, 피크일때는 200개정도 쌓인다. (주기적으로 알람을 보낼때 사용자 로그가 쌓이고 있다)
사실 데이터양이 늘어도 CPU50%를 넘지 않는다. 참고로 초당 600개가 넘을때에도 fluentd두대로 충분히 커버 가능하면서 자원은 70%를 넘지 않았다.
현재는 CPU와 메모리가 노는김에 튜닝을 해볼까 해서, 한번 시도해보았다.
먼저 producer로는 fluentd를 사용하고 있다.
현재 셋팅되어 있는 코드이다.
<match **>
@type kafka2
brokers <카프카서버>
use_event_time true
# buffer settings
<buffer topic>
@type file
path /var/log/fluent/buffer/td/
flush_interval 3s
</buffer>
# data type settings
<format>
@type json
</format>
# topic settings
topic_key topic
# producer settings
required_acks 1
compression_codec lz4
</match>
producer의 경우에는 두가지 정도로 튜닝하는데, 크게 로그 수집 or 스트리밍 데이터 수집 으로 보면 된다.
각각의 튜닝은
- 로그 수집기(Logstash 또는 Fluentd) → Kafka
ex : 이벤트 수가 적고 요청이 잦다면, batch.size=64KB, linger.ms=50ms, compression=lz4 로 튜닝해 네트워크/처리 효율을 높임. - 실시간 마켓 가격 데이터 수집
ex : 일부 유실 허용 가능하므로 acks=0, batch.size=32KB, linger.ms=5ms 설정해 지연 최소화.
로 보면 된다.
나는 다음과 같이 튜닝해 보았다.
1. flush_interval 3s → 더 길게 (5~10s)
- 현 상태: 3초마다 flush
- 문제점: 트래픽이 많지 않을 경우 너무 자주 flush → I/O 낭비 가능성 있음
- 개선안: 5s로 변경
- 지연(latency)과 처리량(throughput) 사이의 트레이드오프 이므로 적절하게 설정해야 함 (1초로 하면 빠르게 자주 보냄 -> I/O 많아짐, 10초로 느리게 보냄 -> I/O는 적어지지만 데이터가 느리게 감)
- 너무 작으면 batch가 쪼개짐 → Kafka 전송 요청 수 증가
- 너무 크면 flush 지연 → 기본값(8MB) 정도 유지
3. queued_chunks_limit_size 512
- 버퍼 디렉터리 내에 적재 가능한 청크 수 제한
- 안 걸어두면 디스크가 가득 차는 위험 존재
- 자원이 충분하다면 128~512 정도 권장
4. linger_ms 0 -> 50
- 현상태 : 0 (메시지마다 바로 전송)
- 데이터가 많으면 벌크로 보내지 않아, I/O 낭비
- 50ms로 변경
5. batch_size 16384 (16KB) -> 65536 (64KB)
- 현상태 : 16384 (16KB)
- linger_ms와 마찬가지로 배치 사이즈를 크게 해서 여러개를 한번에 전송
추가로 worker와 멀티프로세서 관련은 셋팅을 못했는데, 사용하는 패키지가 지원하지 않아, 셋팅을 할수가 없었다...(할수 있었으면 워커와 멀티프로세서만 늘렸어도 충분했을꺼 같다.)
그리고 required_acks도 바꾸지 않았는데, ack를 모두 확인하는 all 을 하면 느려질꺼 같아 1로 그대로 두었다. (혹시나 데이터 누락이 생긴다면 변경해주면 된다)
최종 결과물
<match **>
@type kafka2
brokers <카프카 서버>
use_event_time true
# buffer settings
<buffer topic>
@type file
path /var/log/fluent/buffer/td/
flush_interval 5s
chunk_limit_size 8MB
queued_chunks_limit_size 128
</buffer>
# data type settings
<format>
@type json
</format>
# topic settings
topic_key topic
# producer settings
required_acks 1
compression_codec lz4
batch_size 65536
linger_ms 50
max_send_retries 5
</match>
이번엔 consumer 차례이다.
Kafka consumer 역할은 Logstash 를 사용중이며, 카프카의 데이터를 엘라스틱 서치에 전송하는 역활을 한다.
변경전
input {
kafka {
bootstrap_servers => "카프카서버"
codec => "json"
auto_offset_reset => "latest"
enable_auto_commit => "true"
group_id => "data_logstash-01"
client_id => "data_es_logstash-01"
topics => "토픽이름"
}
}
output {
elasticsearch {
codec => "json"
hosts => "엘라스틱서치서버"
index => "인덱스-%{+YYYYMMdd}"
workers => 1
}
}
변경후
input {
kafka {
bootstrap_servers => "카프카서버"
codec => "json"
auto_offset_reset => "latest"
enable_auto_commit => "true"
group_id => "data_logstash-01"
client_id => "data_es_logstash-01"
topics => "토픽이름"
consumer_threads => 3 # 스레드 1 -> 3으로 증가
fetch_min_bytes => 16384 # 배치 사이즈 증가
fetch_max_wait_ms => 1000 # batch 대기 증가
max_poll_records => 1000 # 기본 500 -> 1000 batch 읽기 증가
}
}
output {
elasticsearch {
codec => "json"
hosts => "엘라스틱서치서버"
index => "인덱스-%{+YYYYMMdd}"
flush_size => 2000 # bulk 1000 -> 2000 전송 사이즈 증가
idle_flush_time => 5 # flush 1 -> 5 대기 시간 증가
retry_on_conflict => 3 # 저번 충돌시 최대 3회 재시도
retry_max_interval => 10 # 전송 실패시 60s -> 10s 재시도 지연 방지
workers => 4 # 병렬 전송 증가
}
}
만일 CPU와 메모리가 남고, I/O도 남는다면 전체적으로 벌크 형식으로 수정하여, 최적의 효과를 볼수 있다. (물론 지연 시간이 늘어날수도 있으니 모니터링을 잘 보면서 튜닝을 하면 된다.)
'server > kafka' 카테고리의 다른 글
| [kafka] KIP-98 Exactly Once Delivery and Transactional Messaging (0) | 2025.11.21 |
|---|---|
| [kafka] kafka connect to es (1) | 2025.11.17 |
| kafka-reassign-partitions (3) | 2025.07.30 |
| fluentd grpc ruby 버전 에러 (3) | 2025.07.29 |
| ksqldb (1) | 2025.07.17 |
