1. 원인 파악하기
GET _cluster/health?pretty
GET _cat/shards?v
................
"current_state" : "unassigned",
................
"details" : "... nested: CircuitBreakingException[[parent] Data too large, data for [internal:index/shard/recovery/start_recovery] would be [16763448606/15.6gb], which is larger than the limit of [16320875724/15.1gb] ..."
- CircuitBreakingException: 메모리 차단기 발동! ES가 OOM(Out Of Memory)으로 다운 직전에 발동됨
- [parent] Data too large: 메모리가 너무 꽉 찼음
- start_recovery: 샤드를 복구(이동)하려고 시도하는 순간에 발생
- would be [15.6gb], which is larger than the limit of [15.1gb] : 이 작업을 수행하려면 총 15.6GB가 필요한데, 내가 설정해 둔 안전 한계선(Limit)은 15.1GB
임시방편으로 매일마다 캐시를 비우고 reroute를 실행했었다.
POST /_cache/clear
POST /_cluster/reroute?retry_failed=true
매일 아침마다 이게 뭐하는 짓인가 해서, 힙을 줄일 방법을 알고 싶었다.
그럼 heap 을 누가 그렇게 먹고 있냐? → 샤드/세그먼트/인덱스 수
GET _cluster/stats
GET _cat/allocation?v
현재 샤드수가 노드당 1300개를 돌파하는 상황이였다. (보통 적절한 수가 500개 max였다...) 샤드 수가 진짜 많다!!
지금까지 운영되었던게 억지로 사양을 늘리면서 버틴거였다.
그외 확인해야 할 사항들
가장 큰 문제는 샤드가 너무 많다는것 (정확히는 인덱스 자체가 너무 많았다 두개의 프로젝트가 하나의 es에 로그를 넣고 있었다. )
그외에도 힙메모리 확보를 위해 다음을 확인했었다.
- Fielddata 캐시 확인 (text 필드가 True일 경우 메모리를 과하게 점유할수 있다.)
- 불필요한 인덱스 관리 (ILM만 잘 지정해주면 된다.)
- segment 병합 (굳이 검색안하는 인덱스의 세그먼트가 계속 힙메모리에 올라가 있는게 문제가 된다.)
- mapping 최적화 ( 인덱스의 필드수를 줄여야 하는데.. 이부분은 불가능했다.)
다음 확인해 보기
GET _cat/nodes?v&h=name,heap.current,heap.max,heap.pct
name heap.current heap.max
data-prd-es-o-06-data 9.4gb 16gb
data-prd-es-o-09-data 8.8gb 16gb
data-prd-es-o-08-data 6.6gb 16gb
data-prd-es-o-10-data 7.7gb 16gb
data-prd-es-o-12-data 8.6gb 16gb
data-prd-es-o-07-data 7.1gb 16gb
data-prd-es-o-11-data 6.3gb 16gb
GET _cat/shards?v&h=index,prirep,shard,node샤드가 9000개가 있었...다.. 그리고 상위 인덱스가 35% 이상의 샤드가 차지하고 있었다.
참고로 가장 많은 인덱스를 차지하고 있는건 접속 로그로 2년간 보관되어야 해서 계속 남아두고 있는 상태였다.
| prefix (대략 서비스) | 인덱스 개수 | 샤드 개수(prim+repl) |
| 403개 | 806개 | |
| 93개 | 372개 | |
| 60개 | 240개 | |
| 60개 | 240개 | |
| 60개 | 240개 | |
| 60개 | 240개 | |
| 60개 | 240개 | |
| 60개 | 240개 | |
| 60개 | 240개 | |
| 58개 | 232개 |
다음 쿼리로 어떤 ILM이 걸려 있는지 확인!
이미 충분히 ILM이 잘 걸려 있어서, 이 부분은 패스 했다.
GET /_ilm/policy
GET /_all/_settings/index.lifecycle.name
2. 작업 내용들
1. stg 인덱스는 replica를 1개로 수정하기
먼저 다음 쿼리로 stg 가 들어간 인덱스 찾기
GET _cat/indices/*stg*?h=index,rep&s=index
index rep
stg_application_log-20251121 1
하지만 이미 1개로 잡혀 있다. 참고로 rep1 은 replica가 1개 있다는 뜻으로 , stg은 굳이 있을 필요가 없어 0으로 만들려고 한다.
총 샤드 = pri * (1 + rep) → 2 * (1 + 1) = 4개 가 되므로, rep를 0으로 만들면 샤드가 2개가 된다!!!
replica 개수를 설정한다면 다음으로 하면 된다.
PUT *stg*/_settings
{
"index": {
"number_of_replicas": 0
}
}위는 현재 인덱스에만 적용되고 앞으로 생성되는 인덱스에 적용하려면 템플릿에 추가해주면 된다.
2. fielddata/agg가 많이 쓰이는 필드
GET _stats/fielddata?fields=*나의 경우 _all.total.fielddata.memory_size_in_bytes ≈ 204,725,032 bytes → 대략 200MB 정도
16GB heap 기준으로 보면, fielddata가 차지하는 비중은 아주 크진 않음아서 이건 패스
3. refresh_interval 쪽 상태
GET _all/_settings?filter_path=**.settings.index.refresh_interval
{
"metricbeat-7.10.2-2025.11.26-000008" : {
"settings" : {
"index" : {
"refresh_interval" : "5s"
}
}
},
"metricbeat-7.10.2-2025.11.23-000007" : {
"settings" : {
"index" : {
"refresh_interval" : "5s"
}
}
},
"metricbeat-7.10.2-2025.11.20-000006" : {
"settings" : {
"index" : {
"refresh_interval" : "5s"
}
}
},
"metricbeat-7.10.2-2025.11.17-000005" : {
"settings" : {
"index" : {
"refresh_interval" : "5s"
}
}
}
}override 된 건 metricbeat 인덱스들만 5초로 설정돼 있고, 나머지 로그 인덱스는 설정이 안 보이는 걸로 봐서 1초로 돌고 있는것으로 보였다.
시스템에서 설정된 값 확인하기
GET .kibana_1/_settings?include_defaults=true&filter_path=**.index.refresh_interval
{
".kibana_1" : {
"defaults" : {
"index" : {
"refresh_interval" : "1s"
}
}
}
}
1초로 설정되어 있어. 모든 인덱스가 결국1초로 된다는 뜻이다.
1초일 경우엔 기존에 만들어둔 쿼리 캐시/집계 캐시가 세그먼트 변경으로 인해 무효화된다.
refresh_interval 간격을 늘리게 되면 (1초 -> 10초) 변경하면 결국 세그먼트 구성을 더 오래 유지하게 된어 GC가 줄어들어 힙 확보에 도움이 된다.
해당 작업도 템플릿에 적용하면 인덱스에 자연스럽게 적용된다.
PUT /*_stg_*,logs_*/_settings
{
"index" : {
"refresh_interval" : "30s"
}
}
3. hot-warm-cold는 뭐고, 왜 필요한가?
운영을 오래 한 Elasticsearch 클러스터는 보통 이런 상황을 맞이한다.
- 데이터 노드는 계속 늘어났고
- 인덱스/샤드는 더 빠른 속도로 쌓이고
- 어느 날부터 힙은 항상 70~90% 근처에서 있음
- GC 로그는 계속 에러만 뱉어내고 있음
로그 보관 기간은 이미 줄일 만큼 줄였고, 템플릿/replica/refresh_interval 도 손봤는데, 여전히 “최근 데이터”와 “옛날 데이터”가 같은 자원 위에서 똑같이 취급되고 있다면 이제는 구조를 바꿔야 할 타이밍이다.
그게 바로 hot-warm-cold (데이터 티어링) 이다.
데이터 티어(data tiers) Hot-Warm-Cold 아키텍처
이 아키텍처는 데이터의 수명 주기(Lifecycle)와 조회 빈도에 따라 하드웨어 리소스를 효율적으로 배분하기 위해 사용한다. 특히 힙 메모리 관점에서도 중요한 의미를 가진다. 데이터의 수명 주기(Lifecycle)에 따라 노드(서버)의 역할을 나누고 데이터를 이동시키는 전략이다.
| 티어(Tier) | 데이터 상태 | 역할 및 특징 | 하드웨어 권장 |
| 🔥 Hot | 최신 (Ingest) | • 지금 막 들어오는 로그 • 쓰기(Indexing)와 검색이 매우 빈번함 • CPU와 IOPS가 많이 필요함 |
고성능 CPU 빠른 NVMe SSD |
| ♨️ Warm | 최근 (Read-Only) | • 검색은 되지만 수정되지 않는 데이터 (예: 지난주 로그) • Force Merge를 통해 힙 사용량을 최적화함 |
대용량 HDD/SSD 중급 CPU |
| ❄️ Cold | 장기 보관 | • 거의 조회되지 않으나 법적 보관용 • 검색 속도가 느려도 됨 |
저렴한 대용량 스토리지 |
Elasticsearch 7.10 이후부터는 이 개념이 공식적으로 data_hot, data_warm, data_cold, data_frozen 같은 데이터 티어 역할로 정식 지원된다. 여기에 ILM(Index Lifecycle Management) 정책을 붙여서 인덱스를 자동으로 계층 간에 이동시킨다.
인덱스는 생성 시 hot에 있다가 → 7일 지나면 warm → 30일 지나면 cold → 90일에 삭제되는 식으로 자동 이동하는 policy를 만들수 있다.
키바나에서는 아래와 같이 적용할수 있다. 템플릿에서 warm phase를 activate로 변경하고 원하는 날짜와 적당한 세그먼트 정보를 넣어주면 된다. 특히 force merge data를 해주면 강제로 3일이 지난 인덱스들은 하나의 인덱스가 되면서 세그먼트가 모두 1로 줄어들게 된다!!!
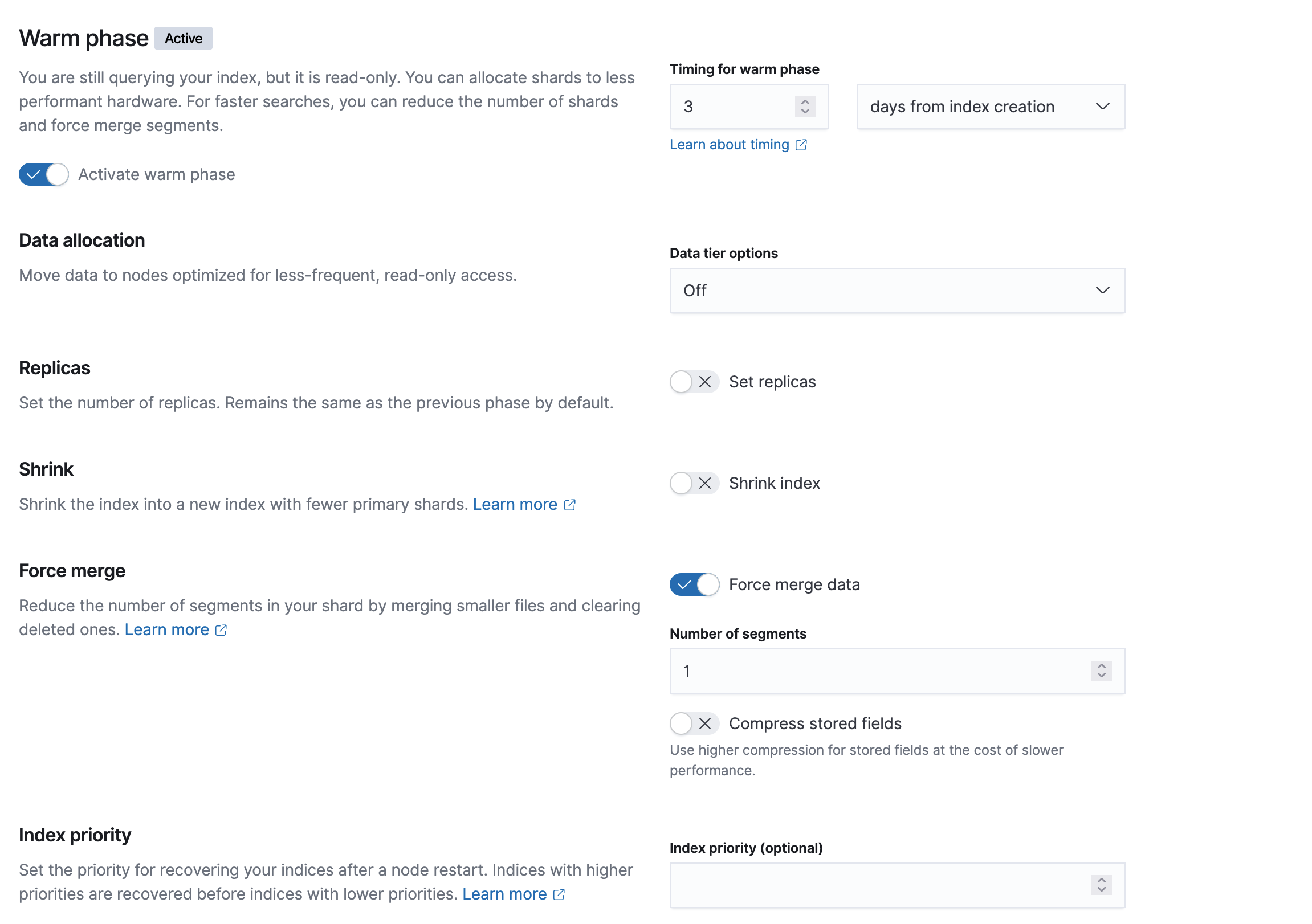
마스터 노드가 일하는 작업을 볼수 있다.
참고로 인덱스가 많다면 한번에 다 하지 말고, 나눠서 작업해야 한다. (시간이 엄청나게 오래 걸렸다 - 대략 이틀 걸림... 중간에 멈출수 없으므로, 나눠서 진행하자!!)
[2025-11-27T14:45:21,914][INFO ][o.e.x.i.IndexLifecycleTransition] [data-prd-es-01-master] moving index [amg_batch_application_log-20251124] from [{"phase":"warm","action":"forcemerge","name":"check-not-write-index"}] to [{"phase":"warm","action":"forcemerge","name":"readonly"}] in policy [14-days-policy]
[2025-11-27T14:45:22,645][INFO ][o.e.x.i.IndexLifecycleTransition] [data-prd-es-01-master] moving index [participate_log-20251115] from [{"phase":"warm","action":"forcemerge","name":"check-not-write-index"}] to [{"phase":"warm","action":"forcemerge","name":"readonly"}] in policy [14-days-policy]
[2025-11-27T14:45:23,318][INFO ][o.e.x.i.IndexLifecycleTransition] [data-prd-es-01-master] moving index [detail-20251119] from [{"phase":"warm","action":"forcemerge","name":"check-not-write-index"}] to [{"phase":"warm","action":"forcemerge","name":"readonly"}] in policy [14-days-policy]
[2025-11-27T14:45:24,023][INFO ][o.e.x.i.IndexLifecycleTransition] [data-prd-es-01-master] moving index [share_link_log-20251124] from [{"phase":"warm","action":"forcemerge","name":"check-not-write-index"}] to [{"phase":"warm","action":"forcemerge","name":"readonly"}] in policy [14-days-policy]
[2025-11-27T14:45:24,524][INFO ][o.e.x.i.IndexLifecycleTransition] [data-prd-es-01-master] moving index [network_postback-20251119] from [{"phase":"warm","action":"forcemerge","name":"check-not-write-index"}] to [{"phase":"warm","action":"forcemerge","name":"readonly"}] in policy [14-days-policy]
[2025-11-27T14:45:25,047][INFO ][o.e.x.i.IndexLifecycleTransition] [data-prd-es-01-master] moving index [server_postback-20251113] from [{"phase":"warm","action":"forcemerge","name":"check-not-write-index"}] to [{"phase":"warm","action":"forcemerge","name":"readonly"}] in policy [14-days-policy]
[2025-11-27T14:45:25,778][INFO ][o.e.x.i.IndexLifecycleTransition] [data-prd-es-01-master] moving index [pub_postback_request_log-20251113] from [{"phase":"warm","action":"forcemerge","name":"check-not-write-index"}] to [{"phase":"warm","action":"forcemerge","name":"readonly"}] in policy [14-days-policy]
[2025-11-27T14:45:26,240][INFO ][o.e.x.i.IndexLifecycleTransition] [data-prd-es-01-master] moving index [postback_log-20251113] from [{"phase":"warm","action":"forcemerge","name":"check-not-write-index"}] to [{"phase":"warm","action":"forcemerge","name":"readonly"}] in policy [14-days-policy]
[2025-11-27T14:45:26,830][INFO ][o.e.x.i.IndexLifecycleTransition] [data-prd-es-01-master] moving index [log-20251115] from [{"phase":"warm","action":"forcemerge","name":"check-not-write-index"}] to [{"phase":"warm","action":"forcemerge","name":"readonly"}] in policy [14-days-policy]
[2025-11-27T14:45:27,618][INFO ][o.e.x.i.IndexLifecycleTransition] [data-prd-es-01-master] moving index [participate-20251121] from [{"phase":"warm","action":"forcemerge","name":"check-not-write-index"}] to [{"phase":"warm","action":"forcemerge","name":"readonly"}] in policy [14-days-policy]
[2025-11-27T14:45:28,232][INFO ][o.e.x.i.IndexLifecycleTransition] [data-prd-es-01-master] moving index [detail_log-20251120] from [{"phase":"warm","action":"forcemerge","name":"check-not-write-index"}] to [{"phase":"warm","action":"forcemerge","name":"readonly"}] in policy [14-days-policy]
[2025-11-27T14:45:28,918][INFO ][o.e.x.i.IndexLifecycleTransition] [data-prd-es-01-master] moving index [batch_application_log-20251124] from [{"phase":"warm","action":"forcemerge","name":"check-not-write-index"}] to [{"phase":"warm","action":"forcemerge","name":"readonly"}] in policy [14-days-policy]
[2025-11-27T14:45:29,666][INFO ][o.e.x.i.IndexLifecycleTransition] [data-prd-es-01-master] moving index [ml_access_log-20251122] from [{"phase":"warm","action":"forcemerge","name":"check-not-write-index"}] to [{"phase":"warm","action":"forcemerge","name":"readonly"}] in policy [14-days-policy]
[2025-11-27T14:45:30,548][INFO ][o.e.x.i.IndexLifecycleTransition] [data-prd-es-01-master] moving index [pub_postback_request_log-20251121] from [{"phase":"warm","action":"forcemerge","name":"check-not-write-index"}] to [{"phase":"warm","action":"forcemerge","name":"readonly"}] in policy [14-days-policy]
지금은 힙메모리 확보가 문제여서 warm으로만 작업을 진행했지만, warm으로 변환시 codec 를 best_compression로 해주면 압축률이 높아져 디스크 확보할수 있다. (단!! 자주 쿼리를 날리는 인덱스에는 사용하면 성능저하가 발생한다!!)
끝
'Database > elastic search' 카테고리의 다른 글
| Elasticsearch 노드 간 디스크 불균형 문제 (0) | 2025.11.27 |
|---|---|
| [es] monitoring 설정 (0) | 2025.11.07 |
| [es] ILM + rollover 설정 (0) | 2025.11.05 |
| elastic search ingest (0) | 2025.09.02 |
| illegal argument exception (1) | 2025.07.25 |