tinder 틴더?
- 위치 기반 소셜 검색 애플리케이션
- 상대의 사진과 400자 미만의 간단한 소개를 읽고 마음에 들면 오른쪽으로 스와이프해 좋아요(Like)를, 그렇지 않으면 왼쪽으로 스와이프해 거절(nope)을 하는 직관적인 방식, 위로 올리면 Super Like.
- 양쪽 모두가 좋아요를 보내면 매치가 성사되며, 매칭 된 뒤에는 채팅이 가능
- 자신이 좋아요를 받은 숫자가 표시되고, 유료 결제를 하면 자신에게 좋아요를 보낸 대상을 볼 수 있다
소개 영상
1. 기능 요구 사항
- 유저는 자신의 정보를 추가하고 사진을 업로드하여 Tinder 프로필을 만들 수 있어야 한다.
- 유저는 지리적으로 가까운 지역에있는 다른 사용자의 추천을 볼 수 있어야 한다
- 유저는 다른 추천 사용자를 좋아 (오른쪽으로 스 와이프)하거나 싫어 (왼쪽으로 스 와이프) 할 수 있어야 한다
- 유저는 다른 사용자와 일치 할 때 알림을 받아야 한다
- 유저는 다른 위치로 이동시 주변 사용자의 추천을 받을 수 있어야 합니다.(실시간)
2. 추정 및 제약 사항
- 하루 18억 건의 스와이프 (좋아요/싫어요)
- 하루 1500만 명의 전 세계 사용자
- 하루 1억 건의 메시지
!! 디비에 대한 분산처리는 필수적이다!!
3. 시스템 API

사용자 미디어(예: 사진)는 파일 서버에 업로드되고 사용자 위치를 포함한 사용자 정보는 Amazon DynamoDB와 같은 key-value로 저장된다. 유저의 데이터는 지역 분할 인덱스(5.GeoShard)에 사용자를 추천하기 위한 대기열에 추가된다.
4. 디비 테이블 설계
다른 테이블과의 조인 관계가 필요 없으므로, nosql로 저장한다.
사용자 프로필 정보를 저장하기 위한 json 구성은 아래와 같다. 이 데이터를 유지 관리하기 위해 Amazon DynamoDB 저장소를 사용한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
{
"userId": "AWDGT567RTH",
"name": "Julie",
"age": 25,
"gender": "F",
"location": {
"latitude": 123123,
"longitude": 123123
},
"media": {
"images": [
"https://mybucket.s3.amazonaws.com/myfolder/img1.jpg",
"https://mybucket.s3.amazonaws.com/myfolder/img2.jpg",
"https://mybucket.s3.amazonaws.com/myfolder/img3.jpg"
]
},
"recommendationPreferences": {
"ageRange": {
"min": 21,
"max": 31
},
"radius": 50
}
}
|
cs |
5. 추천 알고리즘
근처 유저를 추천을 할 때 추천할 해당 유저의 프로파일에 대한 정보를 전달해줘야 하며, 1500만의 유저를 빠르게 검색해야 하므로, 샤딩은 필수적이다. 검색 시 프로파일에 대한 특정 키워드 검색이 필요하므로 텍스트 검색에 특화되어야 한다.
따라서 샤딩+분산처리가 가능하며, 키워드 검색이 가능한 엘라스틱서치로 구축해야 한다.

추천 시 가장 중요한 요건은 거리이다. 현재 근처에 있는 사람을 만나고 싶어 할 것이다. 한국 사람이 지금 당장 인도나 파키스탄의 사람을 만나고 싶어 하는 건 아닐 것이다.
때문에 유저의 정보에 위치에 대한 정보를 토대로 검색되어야 한다. 문제는 "어떠한 값을 기준으로 위치기반 추천 시스템을 만들고 분산처리를 할 수 있는가?"이다.
5. GEOshard
위치기반 추천 시스템을 위해서는 먼저 사용자의 정보 중 위치에 대한 정보를 토대로 데이터를 분산시킬 수 있다. 만일 한국의 유저 대부분이 서울에 몰려 있다면, 검색량이 많은 서울에 유저 디비 하나, 부산에 하나를 위치함으로써 검색을 분산시킬 수 있다.
위치에 따라 분산시키기 위해서 위치만으로 해싱 가능한 시스템(GeoShard)이 필요하다.
먼저 간단한 방법으로는 지도를 일정한 거리로 나뉘어서 해당 칸에 속하는 유저들은 해당 지역의 디비에 저장하는 방식이다.
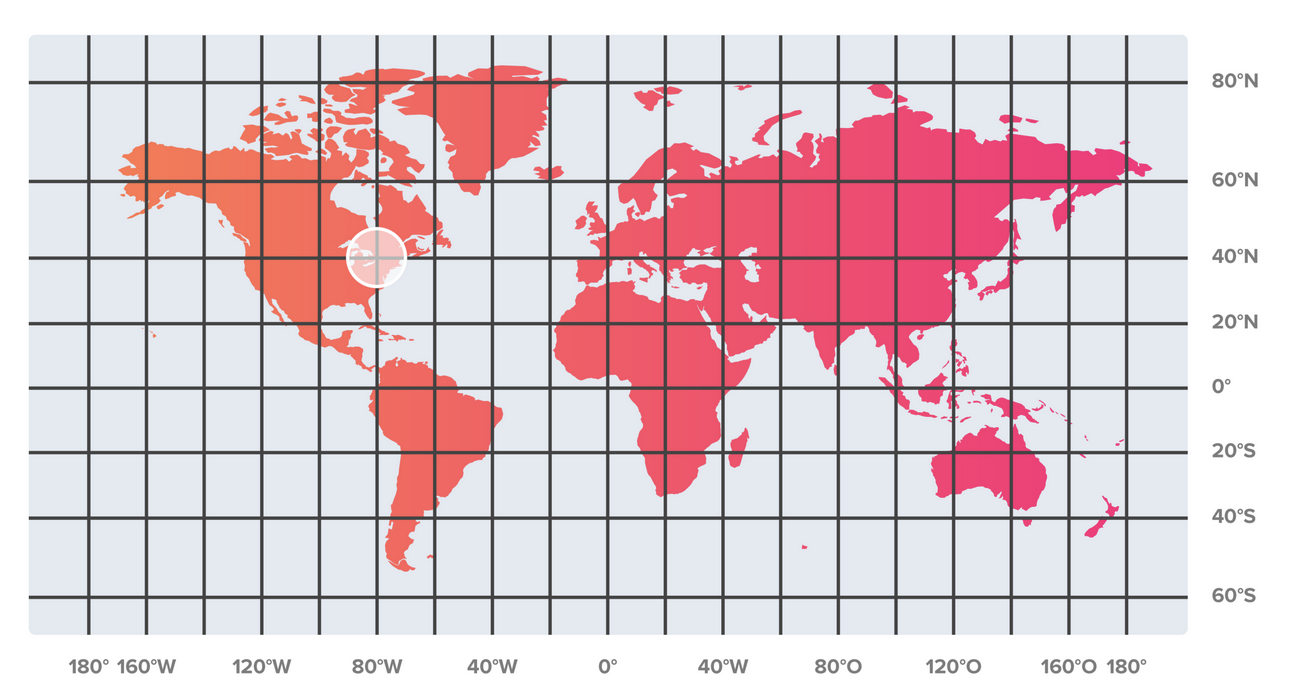
하지만 지도에 따른 거리로 샤딩 할 경우 지도의 왜곡에 따른 데이터 불일치가 일어날 수 있다. 또한 대부분의 사용자들은 특정 지역에 몰려 있다.
거리상으로 데이터를 구분한다면 다음의 문제점이 발생한다.
- 특정 지역에만 쏠림 현상이 있다. (대부분의 유저가 미국 동부와 유럽 서부 쪽에 대부분의 사용자들이 몰려 있다.)
- 거리상으로 나눈 디비에서 추천하기 때문에 유저가 없는 지역은 추천 유저가 아예 없을 수도 있다. (ex: 아프리카 지역은 실제 사용자가 적다)
- 유저의 이동에 따라 지속적으로 추천의 변경을 신경 써야 한다.
위에 대한 해결책으로 아래의 데이터를 중심으로 지역을 나눌 수 있다.
- unique user count
- active user count
- user queries count in an hour
- or 위에 모두
간단하게 unique user count를 사용한다면, 합계만으로 균등하게 지역을 나눌 수가 있다.
거리상으로 나뉘어 있다면 10명을 추천하기 위해 추천 유저를 찾기 위해 일부 데이터가 없는 디비에 검색하게 될 것이다. 하지만 활성 유저 카운트로 지역을 나눈다면 검색 시 주변 몇 개의 샤딩된 디비만 참조하게 되므로 쿼리의 속도 또한 높일 수 있다.
활성 유저의 카운트로 나뉜다면 아래와 같이 균등한 모양이 아닌 서로 다른 넓이 / 모양의 지역으로 나뉘는 샤딩으로 나뉠 수 있다.

6. s3 cell & geosharding algorithm (참조 https://medium.com/tinder-engineering/geosharded-recommendations-part-1-sharding-approach-d5d54e0ec77 a)
실제 틴더에서는 google s2를 사용한다. s2는 Hilbert curve를 기반으로 한다. Hilbert curve상에서 가까운 두 점은 물리적으로도 가까운 위치에 있다.

지구의 표면을 Hilbert curve로 채운 다음 cube에 투영하면 s2가 된다. s2는 level 0(33만 평방 마일)부터 level30 (1평방 센티미터)까지 레벨을 가지고 있으며, 틴더에서는 level 7이나 level8이 가장 잘 맞는다고 결론 내렸다.

이제 기준점은 level8로 한다면 다시 sharding에 따른 cell을 찾아야 한다. 한 쉘에 유저 쏠림 현상을 없애기 위해 쉘의 크기를 유저의 수만큼 계산하여 할당해야 한다.
Hilbert curve를 유저 수로 cell을 생성했을 경우 아래와 같이 나눌 수 있다. (틴더에서는 총 55개로 나눈다고 한다)
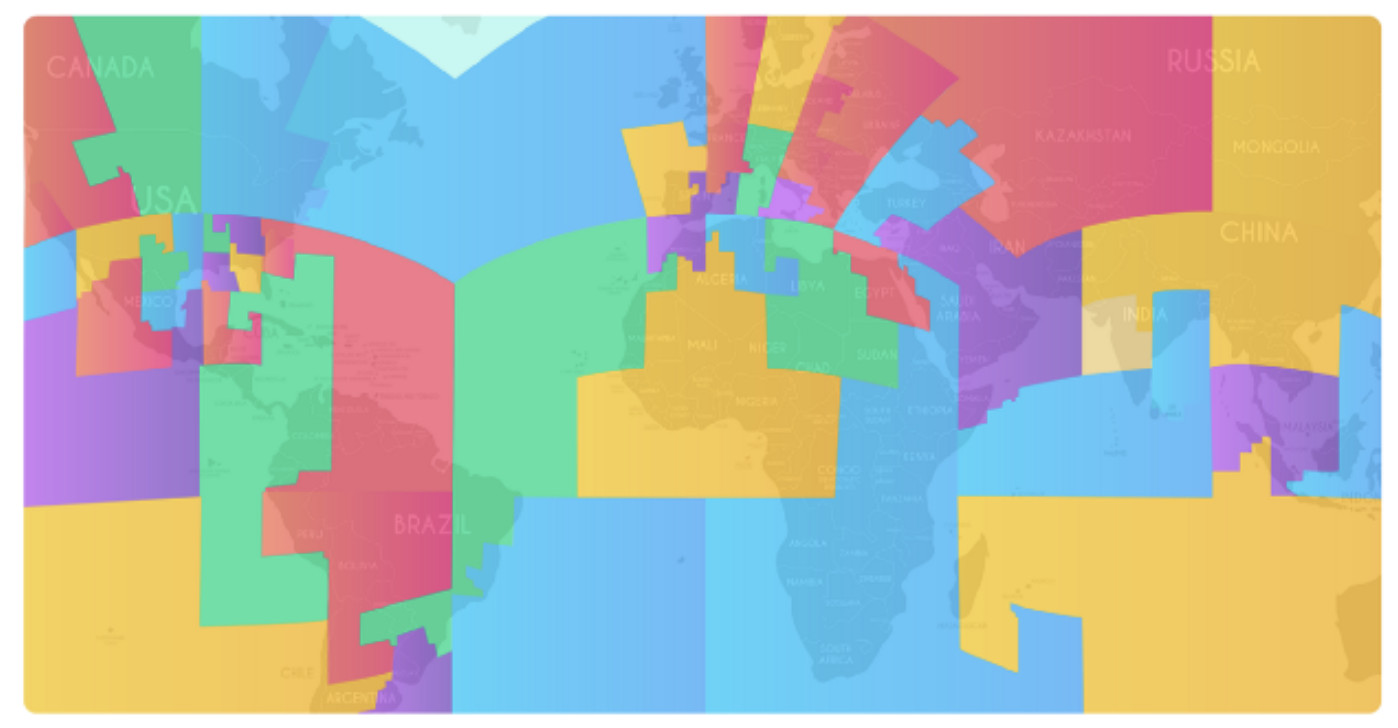
해당 cell 안에서 100마일 이내의 유저를 찾아야 하므로, level8보다 작은 level 6~7로 나눌 수 있다. 해당 쉘이 포함된 디비에 유저 추천을 요청하면 된다. 따라서 query는 55개의 샤딩된 디비중 3개 정도에 query를 요청하면 된다.
- 100마일 거리 계산 = circle
- s2 cells 계산 = Hilbert curve
- Geoshards DB에 요청

결국 Google의 S2 라이브러리와 같은 지역 라이브러리를 사용하여 사용자의 위치를 지역 분할에 매핑하고 해당 분할과 연결된 색인에 사용자를 추가가 가능하다.
이로써 해당 유저의 근처 거리를 계산할 수 있으므로 사용자 근처의 다른 사용자를 추천에 표시될 수 있다.
실제 틴더 서비스에서는 추천 검색 범위를 100km로 제한되어 있다.
7. 좋아요 / 싫어요에 따른 실시간 추천 시스템 구성
위에는 실제 데이터가 어디에 저장되고, 거리에 따라 어떻게 찾는지를 알아보았다. 이제 추천 시스템의 대략적인 시스템 구성이다.
- 사용자가 추천된 유저에 대해 스와이프(좋아요 , 싫어요)를 했을 때, 웹소켓을 통해 해당 결괏값을 서버로 전송한다. (websocket)
- kafka + queue를 통해 요청을 차례대로 대기 큐로 쌓으며 대용량 처리를 가능하게 한다.
- 전송된 데이터로는 유저 정보와 스와이프 된 유저 정보, lat / lng의 위경도 데이터가 전송
- 위경도 데이터를 통해 해당 유저가 저장된 geoshard에 접근 가능
- 샤딩 디비는 추천 알고리즘에 의해서 갱신
- 갱신된 엘라스틱서치의 데이터에서 다시 근처의 추천할 수 있는 유저를 검색하여 사용자에게 전송된다.

8. 요청 데이터의 처리
여러 데이터 저장소가 있는 분산 시스템을 다룰 때 일관성 문제를 해결해야 한다. 일관성을 위해 디자인하지 않으면 쓰기 실패(사용자가 이동하여 디비가 바뀌었을 때) 또는 삭제되지 않은 오래된 데이터가 남을 수 있다.
일관성 문제에 대한 다음 설루션을 다뤄야 한다.
- 쓰기에 대해 순서를 보장
- 모든 데이터 저장소에서 강력하게 일관된 읽기를 보장
Geosharded 인덱스 디자인에서 데이터는 다른 디비에서 다른 디비로 이동할 수 있다. 즉 사용자가 다른 나라로 이동했을 경우를 생각해야 한다. 이란 경우 Tinder 세계에서 가장 간단한 예는 사용자가 "Passport" 기능을 활용한다. 사용자는 지구 상의 다른 곳으로 위치를 이동하더라도 즉시 로컬 사용자를 스와이프 할 수 있다
로컬 사용자가 Passporting 사용자를 찾고 일치 항목을 만들 수 있도록 문서를 해당 지오 샤드로 이동한다. 동일한 문서에 대한 다중 쓰기가 서로 밀리초 이내에 발생하는 것은 매우 일반적이다.
Kafka는 이 문제에 대한 확장 가능한 설루션을 제공한다.. 특정 파티션에 대한 키의 일관된 해싱으로 병렬 처리를 허용하는 항목에 대해 파티션을 지정할 수 있다. 동일한 키를 가진 문서는 항상 동일한 파티션으로 전송되며 소비자는 경쟁을 피하기 위해 사용 중인 파티션에 대한 잠금을 획득할 수 있다.

사용자의 ID를 geoshard에 매핑하는 매핑 데이터 저장소를 통해 일관된 해싱 작업을 포함하는 큐 메시지 시스템 카프카를 통해 일관된 해싱을 통해 각각의 샤딩된 디비로 이동이 가능하다.
추천 시스템까지의 아키텍처를 그린다면 다음과 같다.
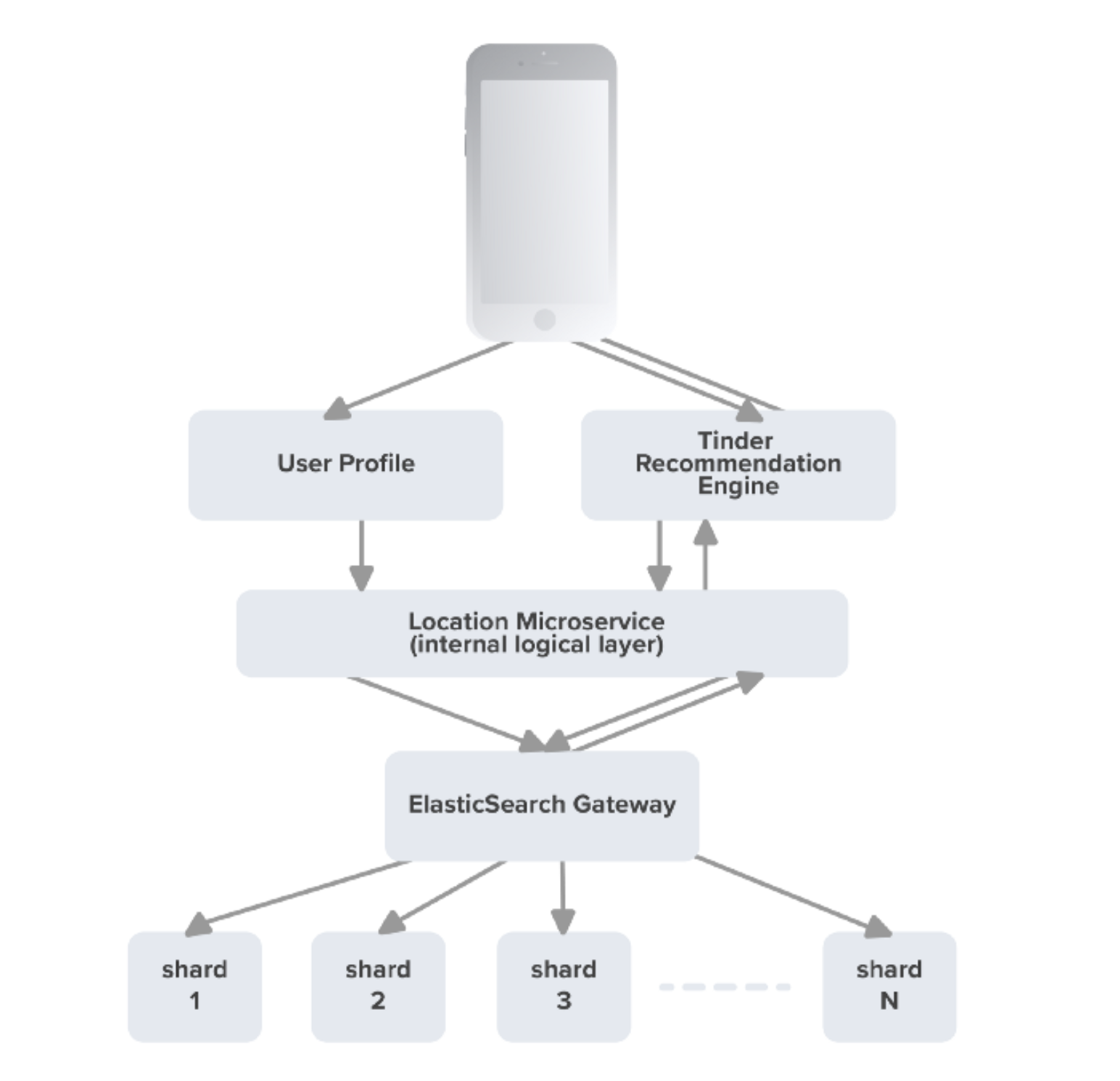
전체 아키텍쳐

참고
- https://medium.com/tinder-engineering/geosharded-recommendations-part-1-sharding-approach-d5d54e0ec77 a
- https://medium.com/tinder-engineering/geosharded-recommendations-part-2-architecture-3396a8a7efb
- https://medium.com/tinder-engineering/geosharded-recommendations-part-3-consistency-2d2cb2f0594b
- https://medium.com/tinder-engineering/taming-elasticache-with-auto-discovery-at-scale-dc5e7c4c9ad0
- https://medium.com/tinder-engineering/how-we-improved-our-performance-using-elasticsearch-plugins-par t-2-b051da2ee85b
- https://www.youtube.com/watch?v=tndzLznxq40&ab_channel=GauravSenGauravSen
- https://techtakshila.com/system-design-interview/chapter-5/
- https://www.youtube.com/watch?v=nBdTBDJNOh8&ab_channel=TechDummiesNarendraL
- https://brunch.co.kr/@andrewhwan/58
- https://brunch.co.kr/@sonjoosik/9
- https://s2geometry.io/
- https://www.youtube.com/watch?v=tndzLznxq40&ab_channel=GauravSenGauravSen
- https://techtakshila.com/system-design-interview/chapter-5/
'server > system design' 카테고리의 다른 글
| 확률적 자료구조 (0) | 2021.08.12 |
|---|---|
| 7. UBER // 쏘카 // lyft // 카카오택시 (1) | 2021.08.09 |
| 5. dropbox // google drive (0) | 2021.07.30 |
| 4. instagram // Flickr // Picasa (0) | 2021.07.23 |
| 3. twitter (0) | 2021.07.21 |



