결론!!
1. 이 값이 데이터에 없는지 알고 싶어!! == Bloom filter
2. 그룹별로 카운팅을 하고 싶어!! == count min sketch
3. 엄청 큰 데이터의 카운팅을 하고 싶어 == hyper log log
해당 영상을 정리 및 풀어서 쓴 글입니다. 영상만 봐도 이해하시기 좋습니다!!
해시 == 고유한 key를 만들고 저장하고 싶은 것!! == 검색을 n(1)로 끝내고 싶어!!
하지만 저장하는 공간을 최소화하면 충돌문제가 일어나고, 해시 함수의 연산(보통은 충돌을 없애기 위해 모듈러 함수에서 key값을 엄청나게 큰 소수로 정한다)에도 많은 시간이 들어간다.
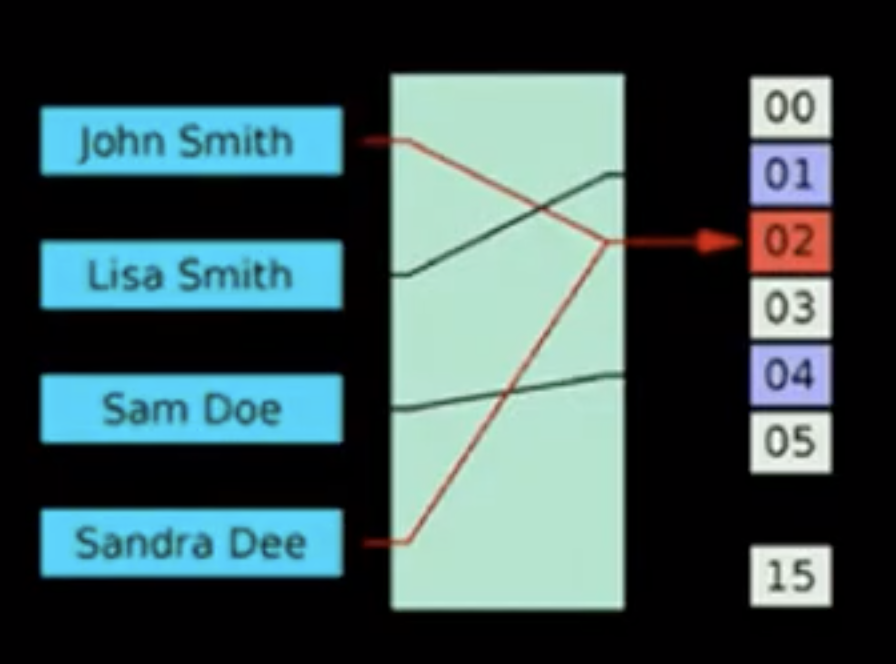
충돌이다!! John smith 와 sandra dee가 같은 곳을 바라보고 있다
충돌은 곧 디스크접근을 했다는 것이고, 그건 느린 연산을 엄청 많이 한다는 것과 같다. 속도를 높이기 위해선 충돌을 최대한 피해야 한다.
보통은 충돌을 피하기 위해 chaining(링크드리스트) 이나 liner probing(다음번 빈 곳에 저장)
여기까지가 그냥 아는 해시 자료구조...
그런데... 실제 서비스에서는 저런걸 쓰면 안 된다. 속도와 비용이 생명인데, 충돌을 최소화해야 한다.
그래서 위대하신 수학자 분들이 많이 만들어주셨다.
우리의 목표!! 원소가 집합에 속하는지 여부를 검사 == 충돌 검사
대표적으로 3개만 볼꺼임

1. Bloom filter
- 공간 효율적 확률 구조
- 데이터가 없는지 100%로 확인 가능, 하지만 데이터가 있는지는 정확히 알 수 없음!! (중요!!)
1.1 동작 방식
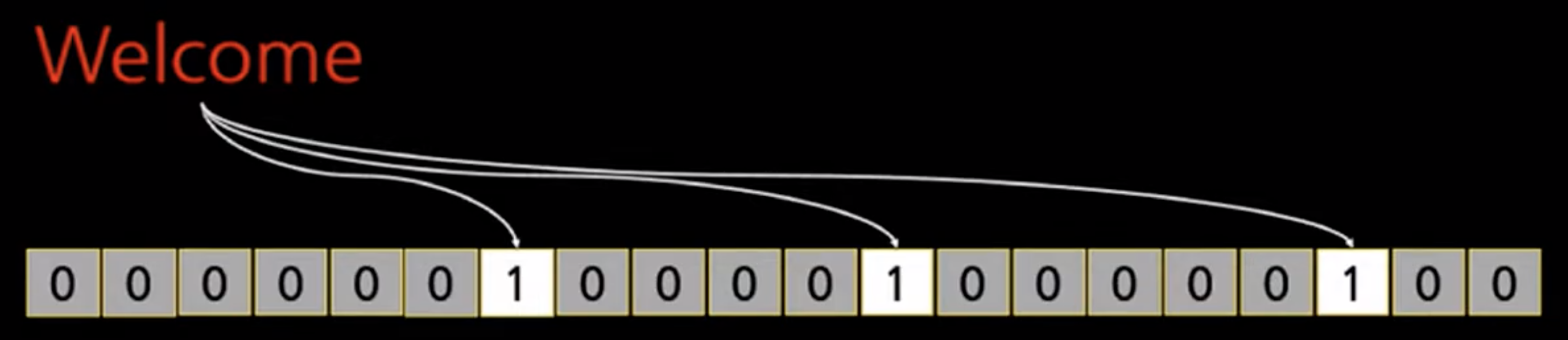
- 저장하고 싶은 집합의 값을 n개의 hash function을 거치게 하고
- 이를 통해 나온 각 bit를 bitmap으로 저장
welcome을 넣었을 때
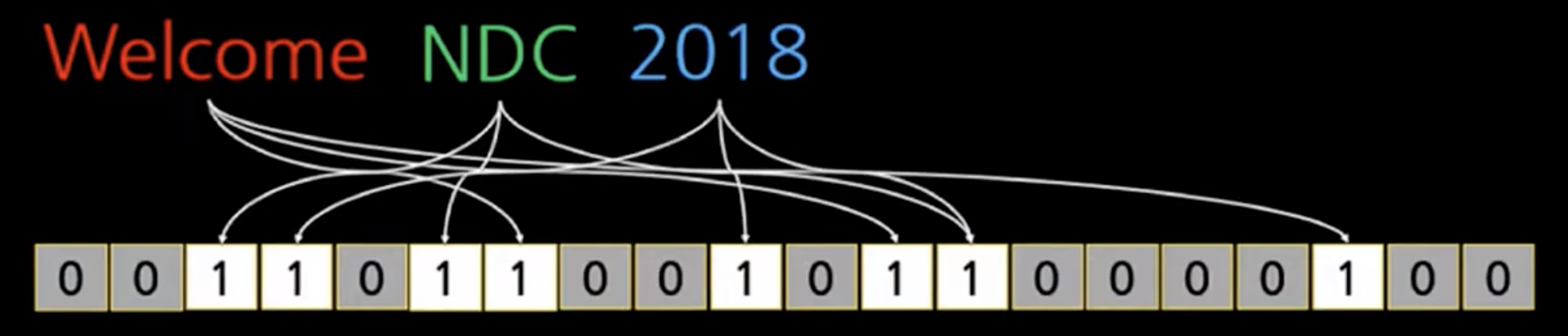
NDC , 2018을 추가했을 때 (비트의 같은 곳이 1이 된 것을 볼 수 있다 - 겹침)
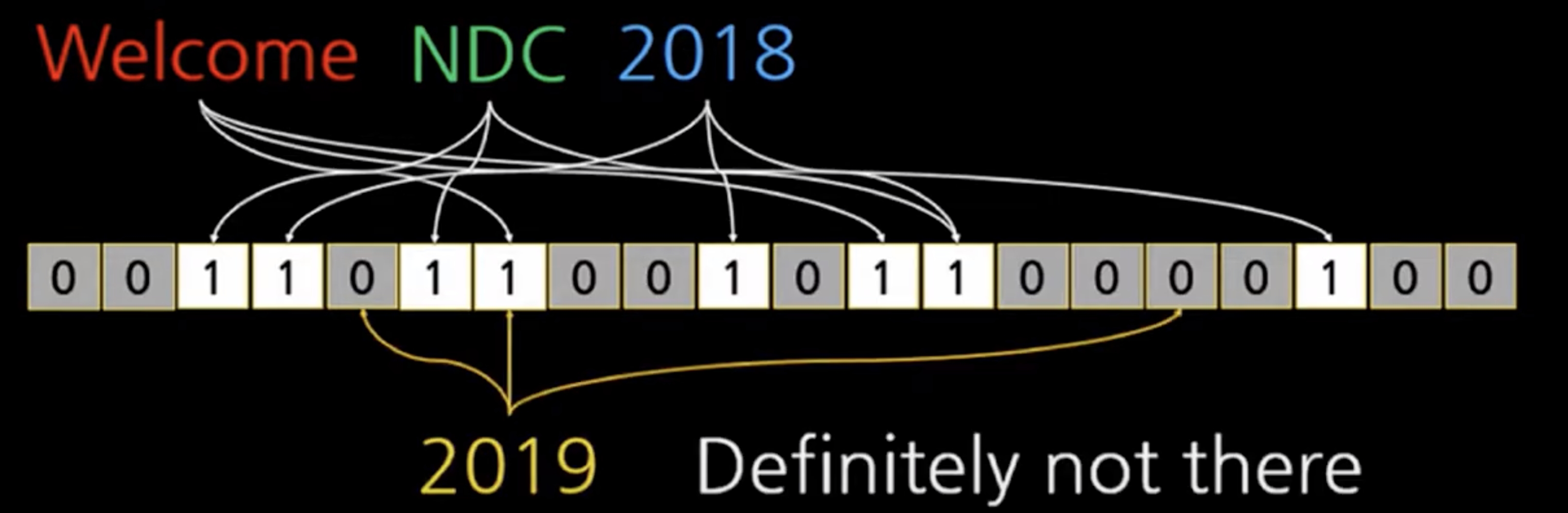
여기에서 "2019"가 있어요?라고 질의해보면 2019에 해당하는 비트가 0인 곳이 있으므로 2019는 저장되지 않음(100% 확신할 수 있기 때문에)
그런데 해시는 충돌이 일어날 수밖에 없기 때문에 "hello"를 해봤더니 비트가 1 임!!
이럴 땐 정말 hello가 있는지 확인해봐야 한다.
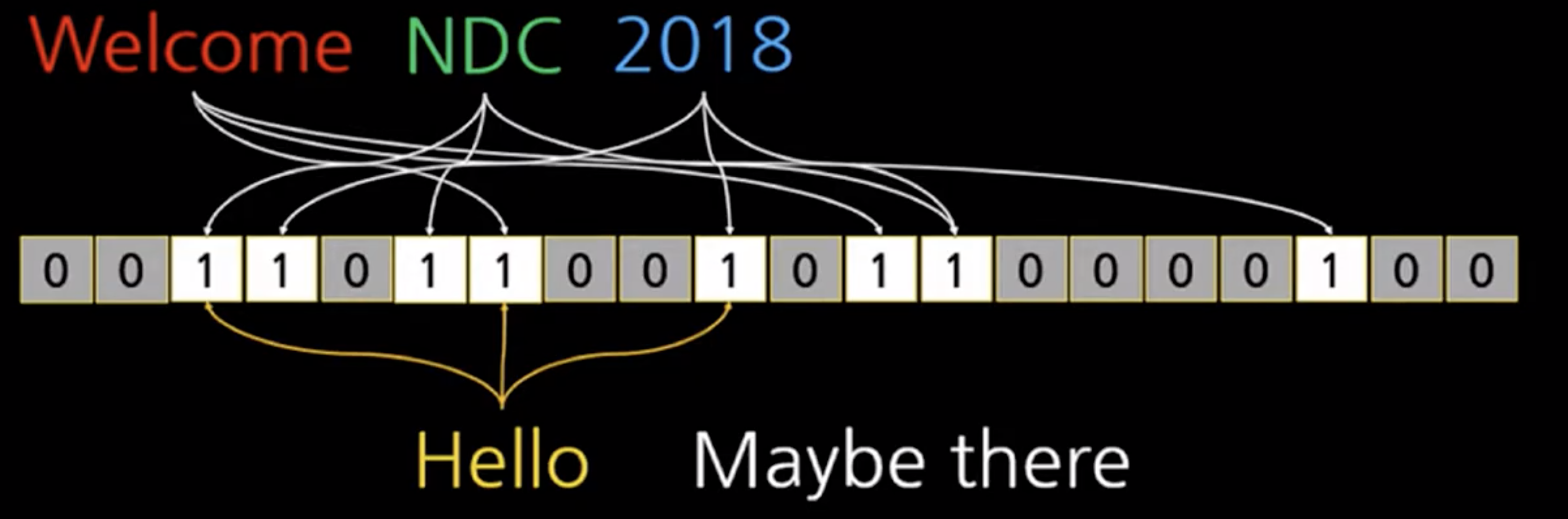
또한 데이터가 많이 들어갈수록 많은 비트가 1이 되므로, 충돌이 많이 발생하게 된다. (conference는 없지만 1로 되어 있다)
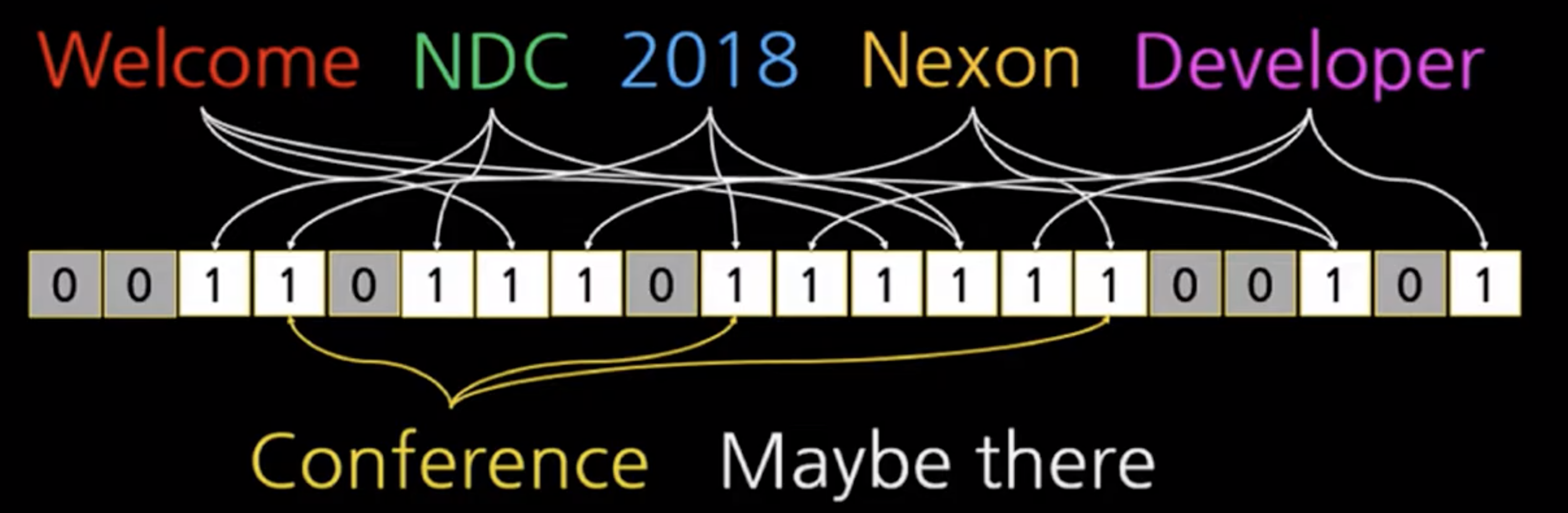
장점!
적은 메모리로 데이터가 있는지 없는지 확인 가능하다.
단점!
하지만 확률적 자료구조 == 있을 수도 있고, 없을 수도 있어요!!
하지만 삭제가 불가능 (삭제하려는 키값이 정말 비트의 값인지 알 수 없음)
이런 걸 어디에 써요?
- 캐시에 데이터가 있는지 없는지 적은 메모리로 빠르게 확인 가능!!
2. count-min sketch
- 어떤 그룹의 값의 빈도를 알 수 있다. 적은 메모리로!!
알파벳으로 된 리스트가 있고, 동일한 알파벳이 몇 개 있는지 알고 싶다고 한다면.
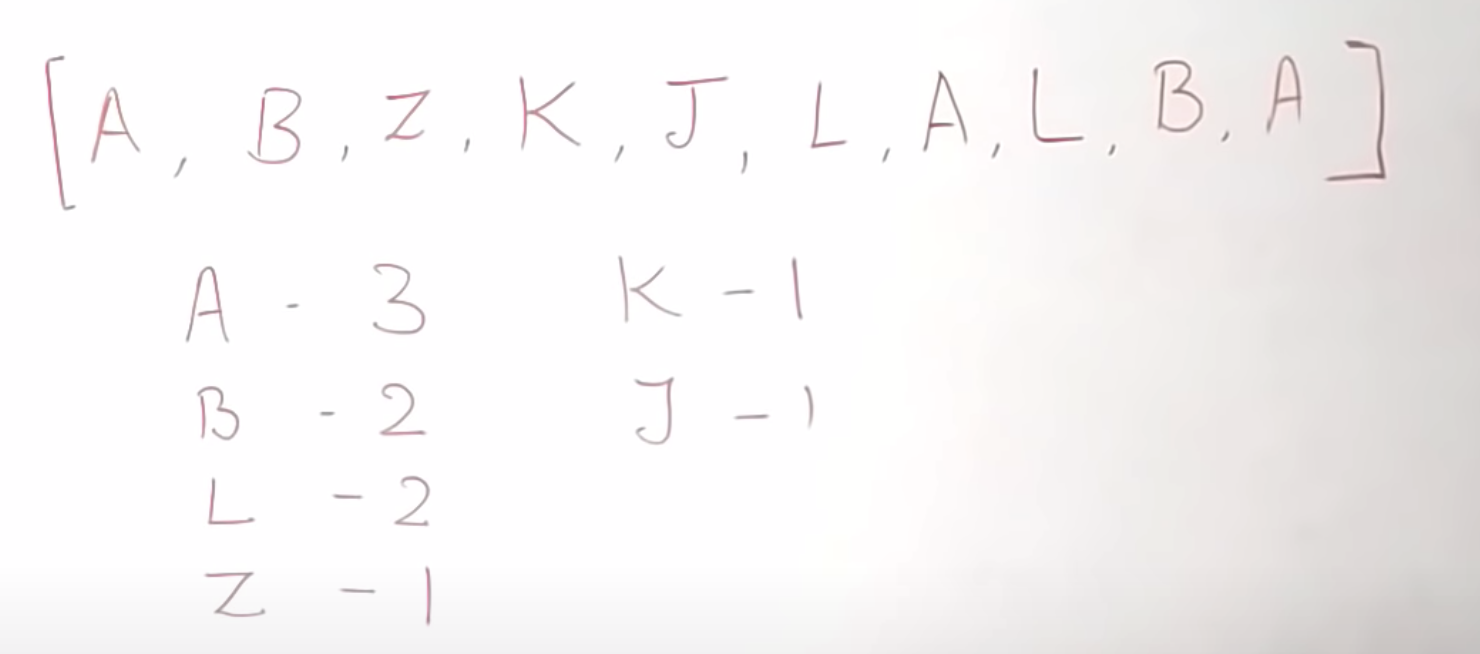
이런 걸 카운팅 하기 위해선 일반적으로 해쉬를 써야 한다. 하지만 엄청나게 데이터가 많다면, 메모리와 I/O가 낭비된다.
stream은 앞서 알파벳의 리스트이다. 똑같이 알파벳을 카운팅 한다고 해보자.
그리고 4개의 해시 함수를 이용해서 이미 알파벳의 테이블이 만들어져 있다. (왼쪽 빨간색)
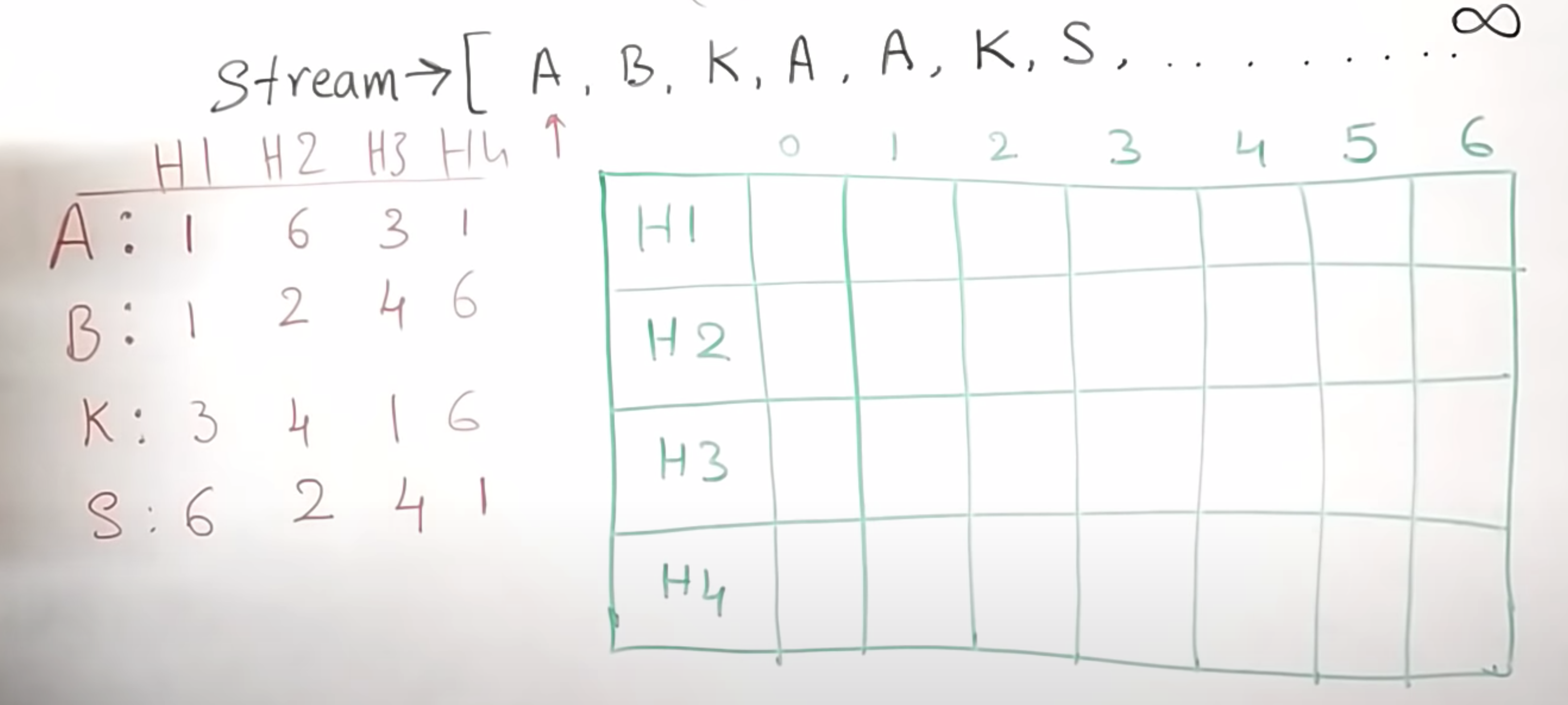
A의 경우엔 각각의 해시를 통과하면
hash1(A) → 1
hash2(A) → 6
hash3(A) → 3
hash4(A) → 1의 값이 나온다.
이것을 해당 해시함수에 나온 값에 맞게 테이블에 표시해보면 다음과 같다.

다음번 값은 B이다.
hash1(B) → 1 / hash2(B) → 2 / hash3(B) → 4 / hash4(B) → 6의 값이 나온다. 값을 추가한다.

자 이제! 모든 값을 테이블에 추가한 후
지금까지의 A가 몇 개 있었는지 count를 보고 싶다면 다시 A를 해쉬 함수에 넣었을 때 표기한 해당하는 테이블의 개수를 가져온다.
앞서 A의 값은 hash1(A) → 1 / hash2(A) → 6 / hash3(A) → 3 / hash4(A) → 1의 위치이므로

[4, 3, 3, 4]가 되었고, 이름처럼 이 중에서 min 값은 3이므로 A는 3번 있다는 결론이 된다!!!! (물론 근삿값이다)
count min sketch의 오차율은 다음과 같이 표기된다. (무슨 말인지 모르겠다..)
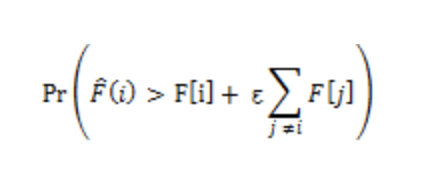
중요한 것은 해시 함수의 개수에 따라 오차율이 변경되며

해당 표기하는 테이블의 크기에 따라서도 오차율이 변동된다.
이런 걸 어디에 써요?
- 여러 디비에서의 카디날 리티를 구할 때
- 엄청나게 큰 데이터에서의 unique 데이터를 구할 때
- spark / redis의 대용량 그룹별 count 시 사용
- 추천 시스템 - 그룹 유사도에 사용 가능 (카디날 리티를 구하면 되기 때문에)
3. HyperLogLog (줄여서 HLL)
- 엄청나게 많은 개수의 추정치를 위해서 사용
hash는 랜덤 한 비트를 생성한 것과 같다!!
랜덤 하게 생성한 값이 커질수록 희귀한 확률이 된다

즉 비트의 값은 카디날 리티(집합의 크기)의 추정치 확률이 될 수 있다!
대략적인 방법은 다음과 같다
- 아래의 값은 어떠한 값들을 hash후 2진수로 표현한 리스트이다.

2. 위의 리스트의 "마지막 2자리"를 기준으로 "4개의 값"으로 나누려고 한다.
00 → R , 01 → G , 10 →B , 11 → Y로 구분하였다.

3. 2자리 이전의 0의 count와 거기에 +1을 더한 값으로 한다면
R : 0+1
G : 2 + 1
B : 5 + 1
Y : 6 + 1 이 된다.

4. 위의 값들은 각 그룹별 카디날 리티 추정 (2^n)으로 표현이 가능하다.

5. 2^r이 너무 거친 추정 방식이기 때문에 여러 hash를 더 사용 + 조화 평균을 구한다.
조화 평균 (최솟값과 최댓값을 뺀 평균값) == 극단의 값은 평균을 해칠 수 있으므로
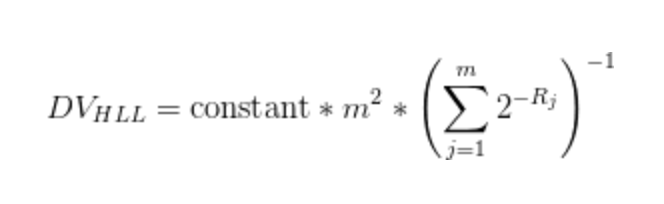
- 대용량에서의 분석 시 사용
- 10억 개의 데이터에서 2% 정확도
- 메모리 1.5kb로 가능!!
- 분산처리환경(순서가 바뀌어도, 숫자가 늘어나도)에서도 사용 가능
- 레디스 및 각종 언어에서 모두 지원
- 대표적으로 디비의 카디날 리티 검색에 사용
HLL은 사실 아래의 절차를 통해 구한다.

HLL은 어디에 쓰여요?
- 예를 들어 이번 달 몇 건이 들어왔는지 카운팅해야 하는데 10억 건이 넘는다? ← 디비 검색만으로 뻗음
- 이걸 정확히 세기 위해서 하둡/스팍을 사용한다? ← 돈이 많이 듬
- 비용 절감 + 속도 빠름 + 하지만 오차율 있음 == HLL
끝!
참고사항
https://www.youtube.com/watch?v=yoVmf-9fW1c&ab_channel=NDC
http://mkseo.pe.kr/blog/?p=2561
https://cprayer.github.io/posts/probabilistic-data-structures-link/
https://tmdahr1245.tistory.com/123
https://tmdahr1245.tistory.com/119?category=907674
https://meetup.toast.com/posts/192
https://www.slideshare.net/charsyam2/bloomfilter-82589241
https://d2.naver.com/helloworld/711301
https://stackoverflow.com/questions/12327004/how-does-the-hyperloglog-algorithm-work
https://www.youtube.com/watch?v=eV1haPUt0NU&ab_channel=TechDummiesNarendraL
'server > system design' 카테고리의 다른 글
| 9. netflix (0) | 2022.02.13 |
|---|---|
| 8. 메신져 (slack // facebook messenger // whatapp // kakaotalk) (0) | 2021.10.04 |
| 7. UBER // 쏘카 // lyft // 카카오택시 (1) | 2021.08.09 |
| 6. tinder (0) | 2021.08.01 |
| 5. dropbox // google drive (0) | 2021.07.30 |



