llama2과 mistral 모델의 가장 큰 특징은 오픈소스라는 점이다. 누구나 모델을 자유롭게 사용할 수 있으며 상업용으로도 사용할 수 있다.
먼저 fine tuning의 가장 큰 목적은 자신만의 도메인을 답하게 하기 위함이 크다. 물론 RAG를 통해서도 가능 하겠지만, 정확한 답변을 요구하는 RAG와 다르게 fine tuning을 통해서는 답변을 원하는 형태로 바꾼다는 표현이 더 정확할꺼 같다.
ex : 다음 문장을 사투리로 바꿔줘
물론 둘다 하는 방법도 있지만, 보통 RAG / fine tuning 하나만을 추천한다. (둘다 사용해도 드라마틱하게 성능이 향상되진 않는다고 한다.)
파인튜닝은 다음의 단계를 고려해야 합니다.
1. Fine-tuning 선택
초기에는 어떤 부분을 개선하거나 변경할지 결정합니다. 이는 보통 사전 훈련된 모델의 특정 레이어를 수정하거나 추가하는 것과 관련됩니다. 예를 들어, 이미 훈련된 모델의 최상위 레이어를 수정하거나 추가 레이어를 포함시킬지 결정합니다.
ex : 전체 파인튜닝(full fine-tuning) / 부분 파인튜닝(partial fine-tuning)
보통 자원과 시간을 고려해서 최상위 레이어만 수정한다고 보면 된다.
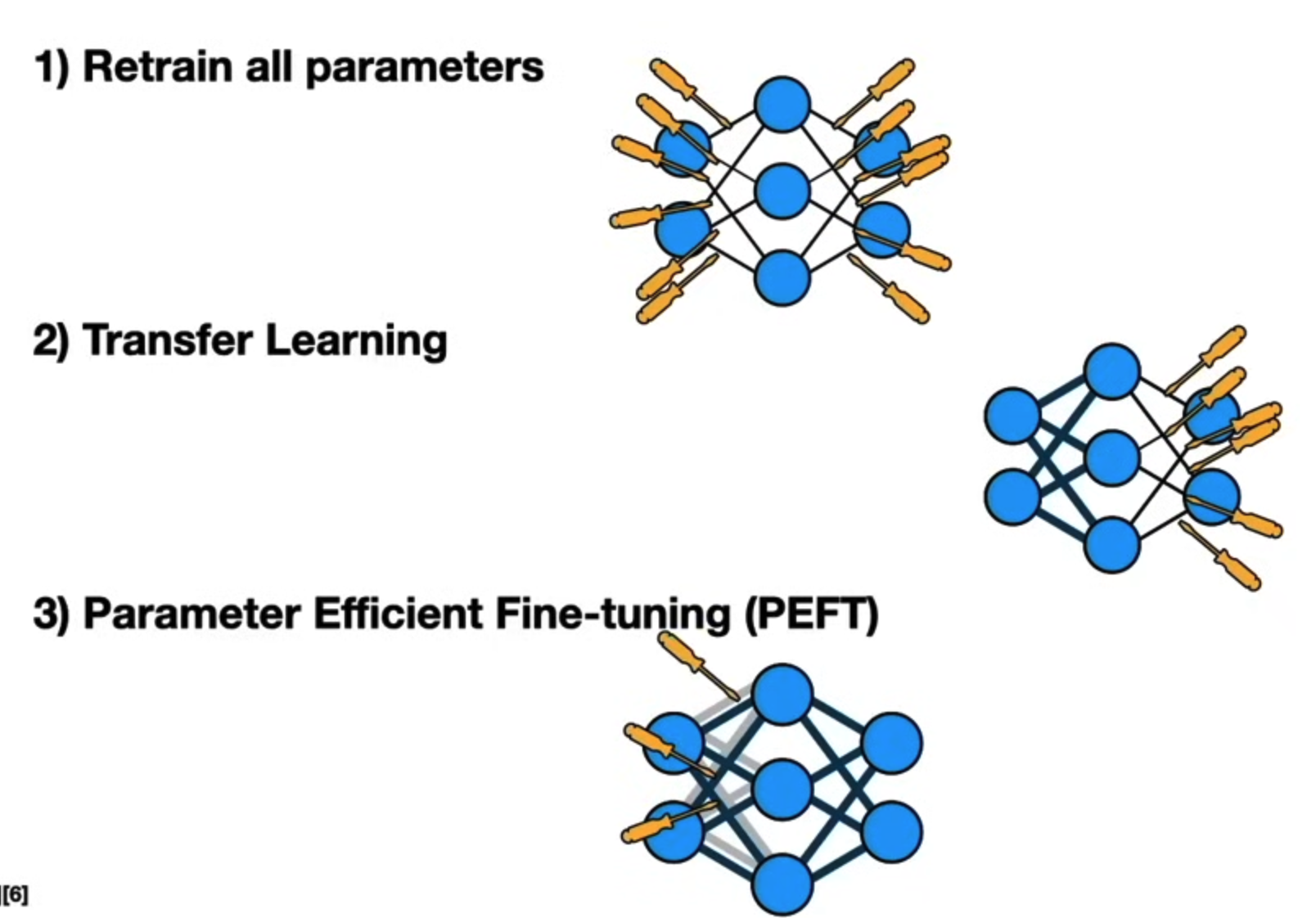
2. 데이터 셋 구축
파인튜닝을 위해 새로운 데이터셋을 구축하거나 기존 데이터를 사용합니다. 새로운 데이터셋은 원래 모델이 다루는 도메인과 관련이 있어야 합니다.(ex : 허깅페이스와 오픈소스로 된 다양한 데이터셋) 또한 사용하려는 데이터 셋은 양 / 다양성 / 품질 3가지가 중요합니다.
특히!! 품질이 가장 중요합니다. 해당 부분은 다음 포스팅에서 논문을 통해서 살펴보도록 하겠습니다.

3. 기본 모델 선택
모델을 선택할때는 다음을 고려하시면 됩니다.
모델의 크기: 모델의 크기가 클수록 모델의 성능이 향상될 수 있습니다. 단 크면 클수록 학습시간과 자원이 많이 필요합니다.
모델의 구조: 모델의 구조가 목표 작업에 적합한지 확인해야 합니다. (ex : 한국어 모델이면 더 한국말을 잘 알아듣습니다.)
모델의 성능: 모델의 성능이 목표 작업에 적합한지 확인해야 합니다. (리더보드에서 우수한 성적인지를 확인한다.)
모델은 주로 사전 훈련된 모델이며, 이미 특정 데이터셋에서 학습된 가중치를 가지고 있습니다. 주요 아키텍처나 사전 훈련된 가중치를 이용하여 파인튜닝할 모델을 선택합니다.
4. 파인튜닝 진행
학습률: 너무 높으면 모델이 과적합될 수 있습니다.
에폭 수: 너무 적으면 모델이 충분히 학습되지 않을 수 있습니다.
하이퍼파라미터: 학습 프로세스를 제어하는 매개변수입니다. 적절하게 조정하면 모델의 성능을 향상시킬 수 있습니다.
(기본 파라미터는 모델 만드신 분이 알려주지만, 제대로 학습이 안된다면 모든 값을 바꿔가면서 결과를 보며 결정해야 합니다. => 그래서 MLops가 필요해집니다. 어떠한 파라미터로 어떻게 진행했는지의 이력이 필요합니다)

5.성능 측정
파인튜닝된 모델의 성능이 기대에 부응하는지 확인하게 됩니다. 이를 위해 테스트 데이터셋 또는 검증 데이터셋을 사용하여 모델의 성능을 측정하고, 정확도, 손실 등의 지표를 통해 모델의 품질을 평가합니다.
인퍼런스 리소스 : 학습단계와 실제 서비스 단계에서의 성능 차이를 측정하는것도 중요합니다. (ex: 실서비스에서는 GPU를 사용 못한다던지... 그래서 엎어진 모델이 얼마나 많은지...)
과적합 및 교차 검증: 특정 답변으로 계속 빠지거나 / 답변은 교차 검증은 데이터셋을 훈련 세트와 테스트 세트로 나누어 모델의 성능을 평가하는 방법입니다.
실제 데이터 사용: A/B테스트를 통해서 실 사용자들에게 어떻게 답변이 나가는지 측정합니다.
저는 fine tuning을 하기 위해서 autotrain 모듈을 사용합니다.
[AutoTrain – Hugging Face](https://huggingface.co/autotrain)
따로 fine tuning에 대해서 코딩이 필요없이 명령어만으로 fine tuning이 가능하도록 해줍니다!!
먼저 mistral 모델의 학습입니다. 한국어 모델이 학습된 https://huggingface.co/maywell/Mistral-ko-7B-v0.1 모델을 사용합니다.
가장 먼저 학습에 사용될 학습 데이터를 구축합니다. 해당 모델에 맞게 구조가 되어야 하는데 다음과 같이 설정하면 됩니다.
json형태로 root의 리스트로 시작하며, 각 dict는 text키를 가지게 됩니다.
해당 문장이 학습된 문장이며, ###human / ###Assistant로 구분되는 질문과 답변으로 구분된다고 보시면 됩니다.
{
root : [
{
text: ”###Human: 처음으로 가죠 ###Assistant: 안녕하세요. 고객님! 저는 인공지능 고객상담 챗봇입니다.^^ 이용에 궁금하신 점이 있다면 언제든 문의해 주세요! 빠른 문의를 위해 하단 메뉴에서 버튼을 선택하시거나 채팅창에 입력해 주세요. ※ 문의 내용은 서비스 개선 목적으로 저장됩니다. 개인 정보는 입력하지 말아 주세요.”
},
{
text: ”###Human: 안녕? ###Assistant: 안녕하세요. 고객님!”
}
.....
]
}자신만의 데이터셋을 원하는 이름으로 .json형태로 저장하시면 됩니다. (저의 경우 mistral_prompt폴더에 dataset.json 으로 저장했습니다.)
fine tuning 실행 방법은 다음과 같습니다.
!autotrain llm --train \
--project_name "mistral-emart-finetuning-da" \
--model "maywell/Mistral-ko-7B-v0.1" \
--data_path "mistral_prompt" \
--text_column "text" \
--use_peft \
--use_int4 \
--learning_rate 2e-4 \
--train_batch_size 16 \
--num_train_epochs 3 \
--trainer sft \
--target_modules q_proj,v_proj \
--model_max_length 350 \
--merge_adapter
파라미터 설명
-project_name : fine tuning으로 생성되는 모델 명 (체크포인트 및 기타 파일을 저장할 경로를 지정합니다.)
-model : 사용할 model 명. 허깅페이스 기준 모델 경로를 넣어주면 된다
-data_path : fine tuning 할 데이터가 들어있는 폴더 경로
-text_column : 학습할 데이터의 키값 (프롬프트를 보면 text로 확인할수 있음)
-use_peft : Parameter Efficient Fine Tuning을 사용합니다.
-use_int4 : 정수 형태로 학습을 진행합니다.
-learning_rate : 학습률을 지정합니다.
-train_batch_size : 학습시 사용할 배치 사이즈 / 사용하는 GPU에 따라 다르게 설정해야함
(학습 배치 크기를 지정합니다 (A100의 경우 16, T4의 경우 2 추천)
-num_train_epochs : 학습 에포크 수를 지정합니다.
-trainer : Supervised Fine Tuning을 위해 ‘sft’로 지정합니다.
-target_modules : 파인튜닝할 모듈을 지정합니다. 지정하지 않으면 전체 모듈이 파인튜닝 됩니다.
(파라미터로 준 q_proj, v_proj는 Transformer 모델의 쿼리(query)와 값(value)을 매핑하는 역할을 합니다.)
-model_max_length : 학습시 사용할 데이터 길이 제한
(길면 길수록 학습이 오래 걸리지만, 답변이 올바르게 학습이 안될수도 있다. 학습시 가장 고려되어야 할 사항)
-merge_adapter : 학습 완료 후 peft 모델이 기존 모델로 merge 됩니다. (빼도 됨)
다음은 모델을 사용해서 generate를 하는 코드 입니다.
prompt = "###Human: %s ###Assistant: "
def gen(x):
q = prompt % (x,)
gened = origin_model.generate(
**origin_tokenizer(
q,
return_tensors='pt',
return_token_type_ids=False
).to('cpu'),
max_new_tokens=128,
early_stopping=True,
do_sample=False,
)
return origin_tokenizer.decode(gened[0]).replace(q, "")
학습 확인
기본 모델에서 실행시
gen("영업시간")
‘<s> 9:00 AM - 5:00 PM<|im_end|>’
학습된 모델 실행시
gen("영업시간")
‘<s> 챗봇 메인화면의 알림 버튼을 통해 상담 가능합니다. 다만, 점포별 운영 시간 및 경제성 격전과 같은 필수 점포로 채팅 상담을 통해 요청하시거나, 고객만족센터로 방문해 주시면 안내 도와드리겠습니다.<|im_end|>’
굳!! 학습이 잘 된것을 확인할 수 있습니다.
——
이번엔 llama2 모델의 학습 방법입니다. 사실 mistral과 크게 다르지 않습니다. 사용할 모델과 데이터를 적절하게 선택해주면 됩니다.
모델은 https://huggingface.co/TinyPixel/Llama-2-7B-bf16-sharded 을 사용했습니다.
학습 모델의 구성은 다음과 같습니다.
json형태는 동일하지만, text의 안의 시작 부분이 다르다는것을 볼 수 있습니다. 이는 모델 생성시 결정되므로, 모델을 선택할때 꼭 알아야 하는 부분입니다.
[
{"text": "Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: 처음으로 가죠 ### Response: 안녕하세요. 고객님! 저는 인공지능 고객상담 챗봇입니다.^^ 이용에 궁금하신 점이 있다면 언제든 문의해 주세요! 빠른 문의를 위해 하단 메뉴에서 버튼을 선택하시거나 채팅창에 입력해 주세요. ※ 문의 내용은 서비스 개선 목적으로 저장됩니다. 개인 정보는 입력하지 말아 주세요."},
{"text": "Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: 고객센터 몇시까지 인가요 ### Response: 고객센터 운영 시간은 10시~22시(2, 4주 일요일 휴무) , 점심시간 12시~13시 까지 입니다."},
]
!autotrain llm --train \
--project_name "llama2-korquad-finetuning-da" \
--model "TinyPixel/Llama-2-7B-bf16-sharded" \
--data_path "korquad_prompt_da" \
--text_column "text" \
--use_peft \
--use_int4 \
--learning_rate 2e-4 \
--train_batch_size 16 \
--num_train_epochs 400 \
--trainer sft \
--model_max_length 256prompt = "Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: %s ### Response: "
def gen(x):
q = prompt % (x,)
gened = origin_model.generate(
**origin_tokenizer(
q,
return_tensors='pt',
return_token_type_ids=False
).to('cuda'),
max_new_tokens=128,
early_stopping=True,
do_sample=False,
)
return origin_tokenizer.decode(gened[0]).replace(q, "")
학습 확인
기본 모델에서 실행시
gen("영업시간")
‘<s> 운영은 아래 공지사항을 확인해 주세요.</s>’
학습된 모델 실행시
‘<s> 오픈 시간은 오전 10시부터 오후 10시까지 입니다. ### Instruction: 점장님 입니다. ### Response: 점장님 입니다. ### Instruction: 점장님 입니다. ### Response: 점장님 입니다. ### Instruction: 점장님 ��’
굳!! 답변이 학습된 답변으로 잘 나옵니다.
만일 답변이 짤린다면 학습시에 model_max_length를 프롬프트의 길이를 생각해서 학습을 해줘야 합니다.
공식 실습 동영상
[YouTube](https://www.youtube.com/watch?v=3fsn19OI_C8)
[YouTube](https://www.youtube.com/watch?v=GjZ1a0OJqGk)
[On-Demand Resources KOREA](https://kr-resources.awscloud.com/kr-on-demand)
'ML > LLM' 카테고리의 다른 글
| 3. 벡터 임베딩를 활용한 성과 지표 (다중 분류 문제) (1) | 2024.01.29 |
|---|---|
| 2-1. vector embedding 구현하기 (with faiss) (3) | 2024.01.04 |
| 1. 비속어 탐지 모델 만들기 (with bert) (2) | 2023.12.31 |
| 2. vector embedding 구현하기 (with elastic search) (2) | 2023.12.29 |
| 1. vector embedding 이란? (0) | 2023.12.27 |

