벡터 임베딩으로 구현한 모델에 대한 "평가 지표 구성을 어떻게 할것인가" 글입니다.
1. 무엇을 측정할것인가?
해당 모델의 목표는 사용자가 임의의 질의를 했을때 설정된 알맞은 대답(답변 약 100개 중 하나)을 리턴하는 모델(faq 챗봇)입니다.
벡터 임베딩으로 텍스트를 벡터화 하고, 가장 유사한 벡터가 정답으로 간주되며 해당 값을 리턴하는 방식입니다.
설정된 여러개의 답변중 하나를 찾기 때문에 해당 모델은 다중 분류 성과 지표를 따라야 한다고 판단했습니다.
다중 분류 문제에서 일반적으로 사용되는 성과 지표는 혼동 행렬 (Confusion matrix)로 표현이 가능합니다.

- 정확도(Accuracy): 올바른 분류의 비율을 나타내는 지표입니다.
- F1 점수(F1 score): 정확도와 재현율의 조화 평균을 나타내는 지표입니다.
- ROC 곡선(ROC curve): True Positive Rate와 False Positive Rate의 관계를 나타내는 그래프입니다.
- AUC 점수(AUC score): ROC 곡선의 아래 부분의 면적을 나타내는 지표입니다.
이러한 지표는 모두 이진 분류에서 사용되는 지표와 동일합니다. 멀티 분류에서도 각 클래스에 대한 정확도, 재현율, F1 점수, ROC 곡선, AUC 점수를 계산할 수 있습니다.
꼭 정답율, 재현율, 정밀도가 높다고 해서 좋은 것은 아니며, 챗봇의 특정 요구 사항에 따라 가장 적합한 지표가 다릅니다. 예를 들어, 챗봇이 중요한 정보를 제공하는 경우 정확도가 가장 중요한 지표일 수 있습니다. 챗봇이 사용자의 질문을 이해하는 데 중점을 두는 경우 재현율이 가장 중요한 지표일 수 있습니다.
ROC AUC는 클래스 균형이 좋지 않은 경우에도 모델의 성능을 평가하는 데 유용한 지표입니다.
스팸 메일과 정상 메일을 분류하는 모델을 생각해 보겠습니다. 이 경우, 스팸 메일의 수는 정상 메일의 수보다 훨씬 적을 수 있습니다. 이 경우 정확도는 잘못된 지표가 될 수 있습니다. 왜냐하면 모델이 정상 메일을 모두 정확하게 분류하더라도 스팸 메일을 일부만 정확하게 분류하면 정확도는 높지만 실제로는 좋은 모델이 아닐 수 있기 때문입니다.
그러나 ROC AUC는 클래스 균형에 영향을 받지 않으므로, 스팸 메일을 잘 분류하는 모델이라면 ROC AUC가 높게 나타날 것입니다. 즉, ROC AUC가 높은 모델은 스팸 메일을 양성(원하는 결과)으로 정확하게 분류할 가능성이 높다는 것을 의미합니다.
recall, precision, fall-out등의 값은 threshold 값을 조작함에 따라 얼마든지 왜곡할 수 있기 때문에, threshold 값의 변화에 따라 변화하는 ROC 곡선의 면적을 계산함으로써 모델의 전반적인 성능을 확인할 때 사용합니다.
* 해당 모델은 벡터 임베딩을 코사인유사도로 정답을 찾는 방식으로 개발하였습니다.
정답율또한 코사인유사도로 측정하였습니다.
2. 테스트 데이터 셋 구성하기

정확도를 측정하기 위해 테스트 데이터셋을 구성합니다. 이 데이터셋은 질문(query)과 그에 대한 정확한 대답이 라벨로 제공되어야 합니다.
- LLM을 통해 적절한 답변을 생성합니다.
- 어노테이터(라벨링 직무)와 QA 를 통해 테스트 데이터를 가공 및 확인합니다.
충분한 테스트 셋 확보를 위해 LLM을 통해 먼저 1차 질문 생성 후 어노테이터분들이 데이터 확인 및 추가 데이터를 만들어주셨습니다.
답변 약 100개에 대한 테스트 질문 데이터 2000개를 만들어 해당 질문에 답변이 정확한지 확인하는 작업을 거쳤습니다.
물론 잘못된 질문도 있었기 때문에 계속해서 어노테이션 분들과 협의하여 수정 보안 했습니다.
- train 데이터가 바뀌게 되면 당연히 test 데이터도 바뀌게 됩니다. 해당 데이터들은 적절한 가공과 필터를 통해 지속적으로 관리되어야 합니다
LLM 데이터 평가에 쓰이는 데스트셋의 경우 다음과 같은 방법을 사용합니다.
질문 형태를 다양하게 하여 (단어 / 간결 / 문장)으로 여러 사용자 응답에 반응할수 있도록 테스트 셋을 구성합니다.
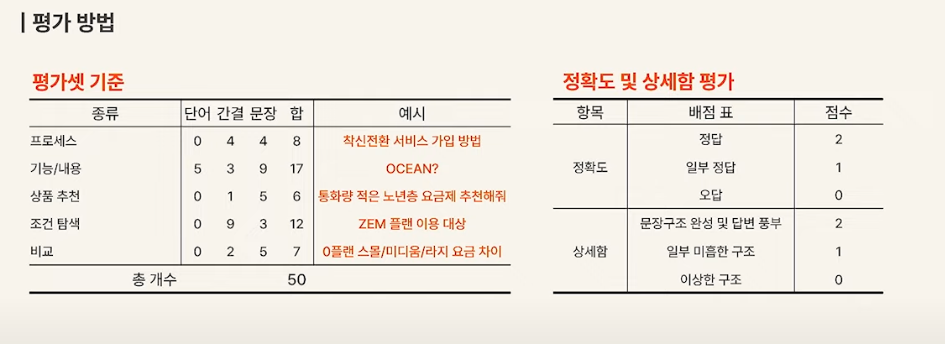
추가 고려사항
* 라벨링의 중요성 : 테스트 데이터셋을 구성할 때, 정확한 라벨링이 중요합니다. 높은 품질의 라벨링이 정확도 측정에 영향을 미칩니다.
* 유사도 임계값(Treshold): 일정 유사도 이상으로 판단하는 임계값 설정이 필요할 수 있습니다.
* 오분류 분석: 모델이 어떤 유형의 오분류를 가장 많이 하는지 분석하여 모델 개선에 활용할 수 있습니다.
3. 목표치 설정하기
먼저 faq는 사용자의 질문에 정확한 답변을 해야 하므로, 정답율을 가장 높은 목표로 설정했습니다.
최종 모든 지표를 90%이상으로 설정하고 진행중에 있습니다. (계속 수정보안해 나가야할 목표입니다.)
4. 정확도, 재현율, F1 점수, ROC, AUC 구하기
벡터 임베딩을 통해 간단하게 FAQ를 구현했다면, 먼저 정확도 평가를 해야 합니다.
정확도는 가장 일반적인 평가 방법입니다. 질문과 답변의 벡터를 각각 계산한 후, 두 벡터의 유사도를 측정합니다. 유사도가 가장 높은 답변과 테스트셋의 답변이 맞다면 정답으로 간주합니다.
정확도 / 재현율 / F1점수 / ROC AUC는 사이킷런의 함수를 사용하면 간단하게 구할수 있습니다.
다음의 3가지 클래스에 대한 분류를 진행할때의 혼동행렬을 구하는 코드 예시 입니다. (3가지 이므로, 0, 1, 2로 기록됩니다.)
from sklearn.metrics import confusion_matrix
y_score = [0, 0, 2, 2, 0, 2]
y_test = [2, 0, 2, 2, 0, 1]
confusion_matrix(y_test, y_score)
#array([[2, 0, 0],
# [0, 0, 1],
# [1, 0, 2]])예측값이 혼동행렬에서는 가로가 되는데, y_pred에는 0인값이 3개 있으므로, 0번째 값을 모두 더하면 3이 됩니다. 그중 0을 맞춘것이 두번, 예측은 0로 했지만 실제값은 2이므로, 아래와 같이 되었습니다.
[[2]]
[[0]]
[[1]]
저의 경우 100개의 분류가 있어서 아래와 같이 표현되었습니다.
array([[19, 0, 0, ..., 0, 0, 0],
[ 1, 17, 0, ..., 0, 0, 0],
[ 0, 0, 12, ..., 0, 0, 0],
...,
[ 0, 0, 0, ..., 20, 0, 0],
[ 0, 0, 0, ..., 0, 16, 0],
[ 3, 0, 0, ..., 0, 0, 15]])
앞써 말씀드린 정확도 / F-1 점수는 다음과 같습니다.
(f1_score 함수는 이진분류에는 잘 나오나 멀티분류에서는 라벨별로만 보여준다... classification_report 함수를 추천한다)
# 정확도
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_score)
# 0.7733142037302726
from sklearn.metrics import classification_report
print(classification_report(y_test, y_score))
precision recall f1-score support
0 0.24 0.95 0.38 20
1 0.94 0.89 0.92 19
2 0.57 0.67 0.62 18
3 0.72 0.72 0.72 18
4 1.00 0.71 0.83 14
5 0.85 0.89 0.87 19
6 0.94 0.84 0.89 19
7 0.41 0.79 0.54 19
8 0.80 0.57 0.67 7
9 0.37 0.56 0.44 18
10 0.92 0.92 0.92 12
11 0.83 0.88 0.86 17
12 0.67 0.93 0.78 15
13 0.89 1.00 0.94 17
14 1.00 0.45 0.62 11
.....
77 0.94 0.85 0.89 20
78 0.62 0.95 0.75 19
79 0.89 0.89 0.89 19
80 0.94 0.85 0.89 20
81 1.00 0.38 0.55 16
82 1.00 1.00 1.00 18
83 0.93 0.93 0.93 14
84 0.95 1.00 0.98 20
85 0.89 1.00 0.94 16
86 1.00 0.75 0.86 20
accuracy 0.77 1394
macro avg 0.80 0.74 0.75 1394
weighted avg 0.83 0.77 0.78 1394macro avg : 클래스별로 정밀도, 재현율, F1-score를 평균한 값입니다. 위의 경우 macro avg는 0.74로, 평균적으로 좋은 모델임을 의미합니다.
weighted avg : 클래스의 빈도에 따라 가중치를 부여하여 정밀도, 재현율, F1-score를 평균한 값입니다. 위의 경우 weighted avg는 0.78로, 전체적으로 좋은 모델임을 의미합니다.
물론, 모델의 성능을 평가하는 데는 다양한 지표가 사용될 수 있습니다. 따라서 위의 지표만으로 모델의 성능을 단정적으로 평가할 수는 없습니다.
ROC와 AUC는 roc_curve()를 통해 구할수 있습니다.
최종 스코어는 아래와 같습니다. 아직 만족할만한 성능은 아니지만, 사용은 가능한 수준으로 보입니다.
roc_auc_score: 0.7713850310218184
해당 스코어를 라벨별 그래프로 나타내면 아래 같습니다. (데이터가 많으면 많을수록 곡선의 모양이 됩니다.)
- 특정 라벨의 성능이 떨어지는것을 볼수 있다. 해당 라벨의 데이터를 추가해서 추가적인 학습이 필요해 보인다.
- 특정 라벨은 성능이 너무 좋은것을 볼수 있습니다. 과적합된게 아닌지 확인하기 위해 데이터를 추가 후 테스트가 필요해 보입니다.
# ROC & AUC
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(y_test[:, i], y_score[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
plt.figure(figsize=(15, 15))
for idx, i in enumerate(range(n_classes)):
# plt.subplot(idx)
plt.plot(fpr[i], tpr[i], label='ROC curve (area = %0.2f)' % roc_auc[i])
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Class %0.0f' % idx)
plt.legend(loc="lower right")
plt.show()
5. 앞으로의 할일
- 모델 버전 관리 : 모델의 다양한 버전을 추적하고, 각 버전에 대한 결과를 기록합니다.
- 모델 모니터링 : 테스트 모델의 성능 지표를 한눈에 볼수 있도록 모니터링을 구축합니다.
- 실시간 모델 성능 모니터링 : 실제 서빙중인 모델의 성능 모니터링을 구축합니다. 예측 결과의 품질, 모델의 응답 시간 등을 감시하여 이상 현상을 식별하고 조치를 취할 수 있도록 도와줍니다.
- 이상 탐지 : 모델의 예측 결과가 기대치와 다를 때 이를 탐지하고, 이상으로 판단되는 경우 알림을 보내는 시스템을 구축합니다.
- 주기적인 모델 재평가 : 새로운 데이터나 변화된 환경에 맞게 모델을 주기적으로 평가하고, 필요에 따라 모델을 재학습시킵니다.
- 로그 기록과 문서화 : 모델의 학습 과정, 하이퍼파라미터, 튜닝 결과, 평가 결과 등을 기록하고 문서화하여 추후 분석과 비교에 활용합니다.
끝!!
99. 번외 (LLM에서의 성과 지표)


답변에 대한것으로 다음 모델을 파인튜닝을 준비함
예를 들어 답변에 과정이나 비교가 없다면 해당 하는 데이터셋을 보안하여 학습을 진행한다.

참조
https://moons08.github.io/datascience/classification_score_roc_auc/
[LLM] LLM 텍스트 요약 평가 관련 + 논문 리뷰
최근 LLM 모델을 활용한 요약이 BART나 T5 등 기존의 생성 요약 모델을 파인튜닝한 것보다, 심지어 사람이 요약한 것보다 더 좋다는 연구 결과가 나왔습니다. 그런데 이런 요약 모델의 성능 평가는
didi-universe.tistory.com
https://lgresearch.ai/blog/view?seq=313
Large Language Models에서 복잡한 질의응답의 Few-shot 효율성을 높이기 위한 PromptRank 접근법 - LG AI Resear
www.lgresearch.ai
http://journal.dcs.or.kr/xml/24875/24875.pdf
https://www.youtube.com/watch?v=WWaPGDS7ZQs
'ML > LLM' 카테고리의 다른 글
| [논문리뷰] Precise Zero-Shot Dense Retrieval without Relevance Labels (HyDE) (0) | 2024.02.14 |
|---|---|
| [논문리뷰] Lost in the Middle: Models Use Long Contexts (2) | 2024.02.13 |
| 2-1. vector embedding 구현하기 (with faiss) (3) | 2024.01.04 |
| 1. 비속어 탐지 모델 만들기 (with bert) (2) | 2023.12.31 |
| 2. vector embedding 구현하기 (with elastic search) (2) | 2023.12.29 |


