Abstract:
자연어 처리 분야에서 많은 관심을 받고 있는 Vector Embedding 기술이 챗봇 개발에 어떻게 적용되고 있는지에 대해 탐구합니다. 이 글에서는 챗봇이 대화 상대와의 의미 있는 상호 작용을 달성하기 위해 텍스트를 벡터 공간으로 변환하는 방법과 그것이 어떻게 챗봇의 성능 향상에 기여하는지에 대해 다룰 것입니다. 또한, 다양한 벡터 임베딩 기술과 그 활용 사례들을 살펴보며, 이를 통해 챗봇의 자연스러운 대화 능력 향상에 어떻게 기여할 수 있는지를 분석합니다.
1.1 벡터 임베딩이란?
챗봇의 가장 중요한 기능은 바로 사용자가 입력한 문장의 의미를 알아야 하는것입니다. 검색이라면 단순히 검색어가 일치한 것을 찾아내면 되지만 채팅이기 때문에 사용자의 문맥의 의미를 알아야 합니다.

사용자가 "코끼리 식당" 이라고 검색을 했다면 왼쪽이 맞을까? 오른쪽이 맞을까?
어떤것을 답변으로 하는 시스템을 구축했는가?

위의 검색어 및 시멘틱 검색을 위해서 임베딩이라는 기술이 발전하게 되었다.
임베딩이란 고차원 공간에서 단어나 이미지와 같은 데이터를 수학적으로 표현한 벡터 뭉치 이다.
예를 들면
안녕! => [0.19370053708553314, -0.3331463038921356, -0.8545711636543274, -0.8179842233657837 …]
이렇게 float의 배열로 표현하는것이다.
결국 특정한 공간(벡터)안에 문장을 수치화해서 표현하는것을 임베딩이라 한다.
1.2. 임베딩 == 숫자로 표현하기 좋은것!
임베딩은 대수학적으로 좋은 성질을 갖는다. 이 말은 어떠한것을 특정한 수로 나타낼수 있다는 것이다.
단어를 예를 들면
Man - king + Woman = Queen ( 남자에서 왕이 있는거리만큼 여자에서 떨어진것은?)
Korea - Seoul + Japan = Tokyo (한국에서 서울 만큼 일본에서 떨어진것은?)
즉 특정한 워드는 벡터를 통해 관계성을 알수 있다

1.3 임베딩의 역사와 발전
초기의 임베딩은 one-hot 인코딩과 같은 형태로 발전했습니다.
원-핫 인코딩은 단어 집합의 크기를 벡터의 차원으로 하고, 표현하고 싶은 단어의 인덱스에 1의 값을 부여하고, 다른 인덱스에는 0을 부여하는 단어의 벡터 표현 방식입니다.
아래를 보시면 빠르게 이해가 가는데, 특정 단어에 대해서 한문장에 개수를 기록하는 방식이라 보시면 됩니다.
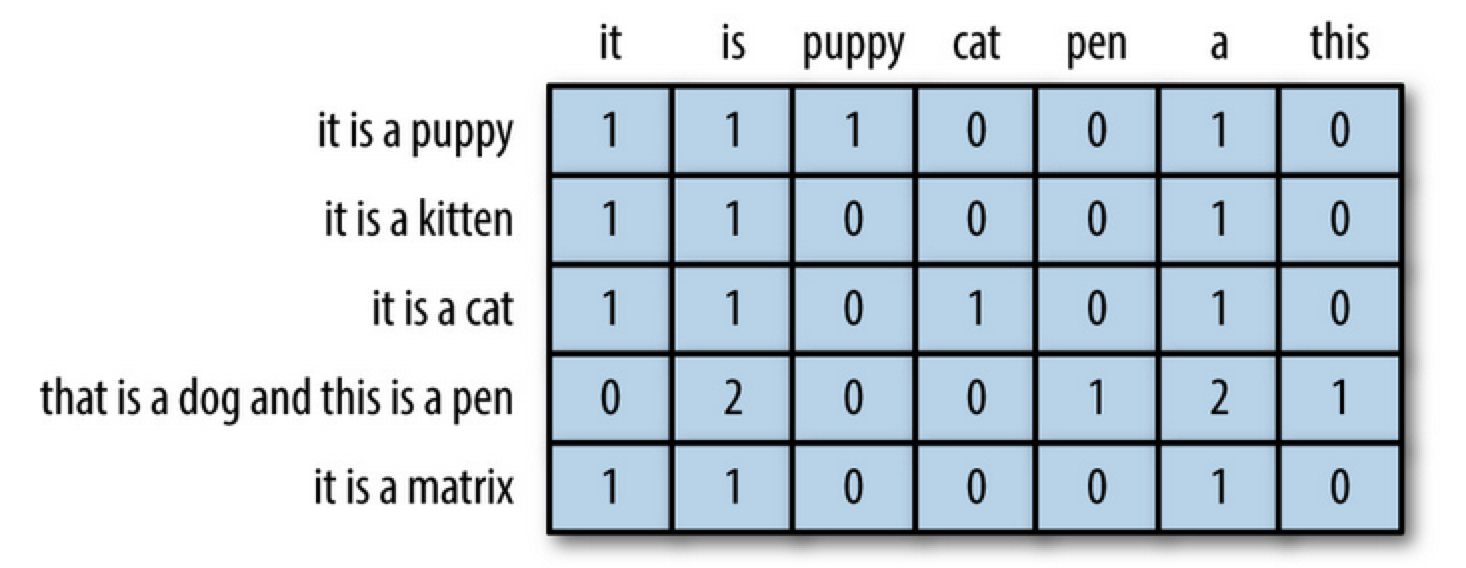
이러한 표현 방식은 단어의 개수가 늘어날 수록, 벡터를 저장하기 위해 필요한 공간이 계속 늘어난다는 단점이 있습니다. 다른 표현으로는 벡터의 차원이 늘어난다고 표현합니다. 원 핫 벡터는 단어 집합의 크기가 곧 벡터의 차원 수가 됩니다. 결국 너무 많은 차원을 표현하게 되므로 저장공간과 벡터상의 의미를 잃게 되었습니다.
두번째는 TF-IDF(단어 빈도-역 문서 빈도) 입니다.
아래 그림을 보시면 빠르게 이해가 가실겁니다.
tf : 해당 단어에 대해서 몇개가 있는가?
idf : 전체 문장에서 해당 단어가 몇문장에 들어있는가?
tf-idf는 특정 문서에서 자주 등장하는 단어는 그 문서 내에서 중요한 단어로 판단합니다. 첫번째 문장에서 king를 한 번 언급했지만, 문서2에서는 king를 두 번 언급했기 때문에 문서2에서의 king이 더욱 중요한 단어라고 판단하는 것입니다.

One-hot Encoding / tf-idf 는 사람이 이해할수 있는 벡터를 가진 값이였다면 Learned Embedding (LLM)의 경우 사람이 보고 이해하기는 어려운 특성을 지닙니다.
그러나 One-hot Encoding / tf-idf 방식에 비해 embedding vector의 차원이 매우 낮고, embedding vector 내 모든 원소를 밀도 있게 활용하고 있어서 AI 모델이 이를 보다 효과적으로 핸들링할 수 있다는 장점이 있습니다.

1.4 언제 / 어디에 사용 가능할까?
임베딩 기술은 다양하게 사용 가능합니다. 정확히는 숫자로 표현 가능하고 / 검색하고 싶은 모든것에 사용이 가능합니다.
대표적으로는
비정형 데이터 탐색 - 텍스트 / 이미지 / 오디오 / 비디오 / 센서 값 등등
질문 답변 / 시맨틱 검색 / 추천 / 검색 결과 순위 재지정
예제 1
음악 스트리밍 앱에서 노래의 템포, 장르, 사용된 악기와 같은 음악적 특징을 포착하는 임베딩을 사용하여 벡터로 표현될 수 있습니다. 좋아하는 트랙과 유사한 노래를 검색하면 앱의 벡터 데이터베이스가 임베딩을 비교하여 선호도와 밀접하게 일치하는 노래를 찾습니다.
예제 2
이미지를 업로드하면 비슷한 얼굴을 찾아서 보여주는 서비스 입니다.
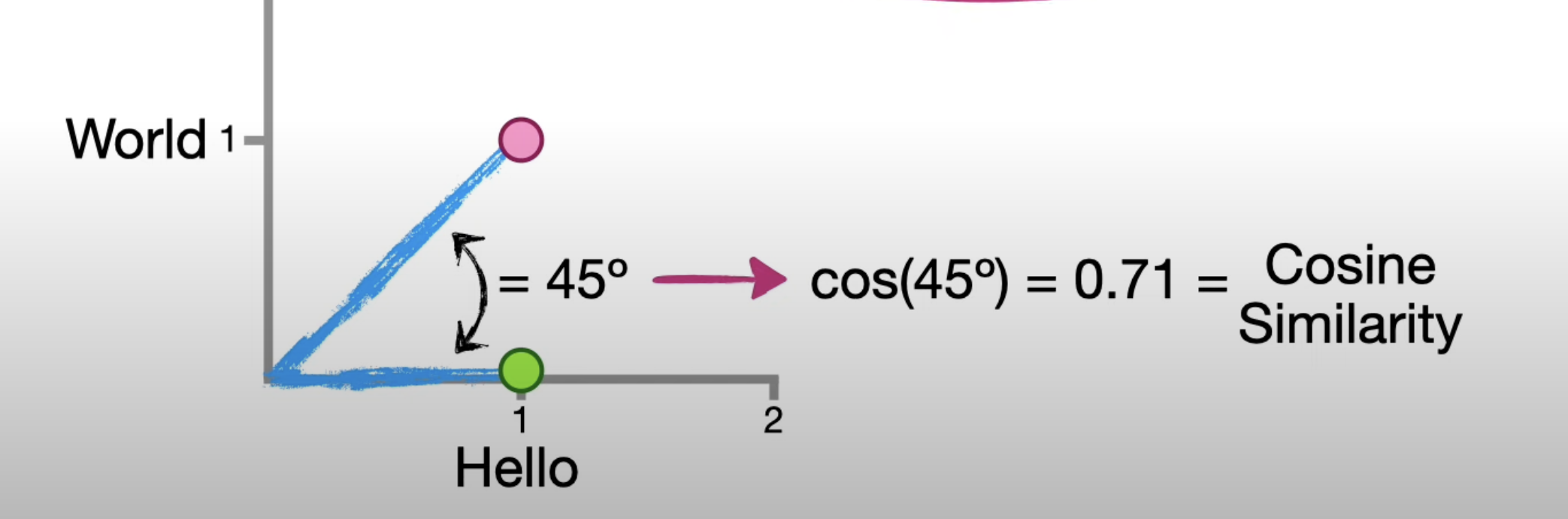
1.5 어떻게 비교가 될까?
코사인 유사도 (Cosine Similarity) == 다차원 공간 안에 있는 두 벡터가 얼마나 비슷한지 1 에서 -1 사이의 숫자로 계산해주는 방법 ( 유사한가를 숫자로 출력)
두 벡터의 방향이 완전히 동일한 경우에는 1의 값을 가지며, 90°의 각을 이루면 0, 180°로 반대의 방향을 가지면 -1의 값을 갖게 됩니다. 즉, 코사인 유사도는 -1 이상 1 이하의 값을 가지며 값이 1에 가까울수록 유사도가 높다고 판단할 수 있습니다. 이는 두 벡터가 가리키는 방향이 얼마나 유사한가를 의미합니다.
코사인 유사도는 두 벡터의 내적을 두 벡터의 L2 norm (즉, 유클리드 거리 (피타고라스 거리)) 의 곱으로 나눈 값으로
수식으로 표현하면 다음과 같다.

https://ko.wikipedia.org/wiki/%EC%BD%94%EC%82%AC%EC%9D%B8_%EC%9C%A0%EC%82%AC%EB%8F%84
코사인 유사도 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 코사인 유사도(― 類似度, 영어: cosine similarity)는 내적공간의 두 벡터간 각도의 코사인값을 이용하여 측정된 벡터간의 유사한 정도를 의미한다. 각도가 0°일 때
ko.wikipedia.org
이를 파이썬 코드로 구현하면 다음과 같다.
import numpy as np
def cosine_similarity(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * (np.linalg.norm(b)))
a = [1, 2, 3]
b = [3, 2, 3]
print(cosine_similarity(a, b))
# 0.9116846116771036
간단하게는 scipy의 함수를 쓰면 된다.
from scipy.spatial.distance import cosine
print(cosine(a, b)) # 코사인 거리
print(1 - cosine(a, b)) # 유사도
# 0.08831538832289643
# 0.9116846116771036
결국 이 유사도를 활용해서 추천시스템을 개발할 수 있게 됩니다.
1.6 벡터(차원)는 무엇을 의미하는가?
딥러닝은 다음과같이 그림으로 나타낼수 있습니다. 가장 중요한 output 레이어가 결국 벡터를 결정하게 됩니다.


보통 LLM에서는 부분에 따라 다음과 연관되어 있습니다. (모델마다 학습마다 다를수 있지만 보통의 경향은 다음과 같습니다.)
- 아래쪽 레이어 (입력 임베딩에 가까운 쪽): 기초적인 언어본능에 대한 능력과 연관됨 (띄어쓰기라던가, 동사 형용사 같은 관계)
- 중간 부분 레이어 : 논리적 추론 능력
- 맨 위쪽 (출력에 가까운쪽) 레이어: 구체적인 사실에 대한 지식에 연관성이 깊음
예를 들어
6 레이어 1번째 뉴런 : 형용사
7 레이어 1번째 뉴런 : 주어
7 레이어 2번째 뉴런 : 동사
7 레이어 54번째 뉴런 : 감정
각각의 뉴런이 무엇을 나타내는지는 아무도 알수 없습니다. 단지 "특정 단어 뜻을 나타내는게 아닌 문장 전체를 포함하는 뜻을 나타낸다"라고 보면 됩니다.

자세한 사항은 해당 논문을 보시면 됩니다.
TinyStories: How Small Can Language Models Be and Still Speak Coherent English?
https://arxiv.org/abs/2305.07759
TinyStories: How Small Can Language Models Be and Still Speak Coherent English?
Language models (LMs) are powerful tools for natural language processing, but they often struggle to produce coherent and fluent text when they are small. Models with around 125M parameters such as GPT-Neo (small) or GPT-2 (small) can rarely generate coher
arxiv.org
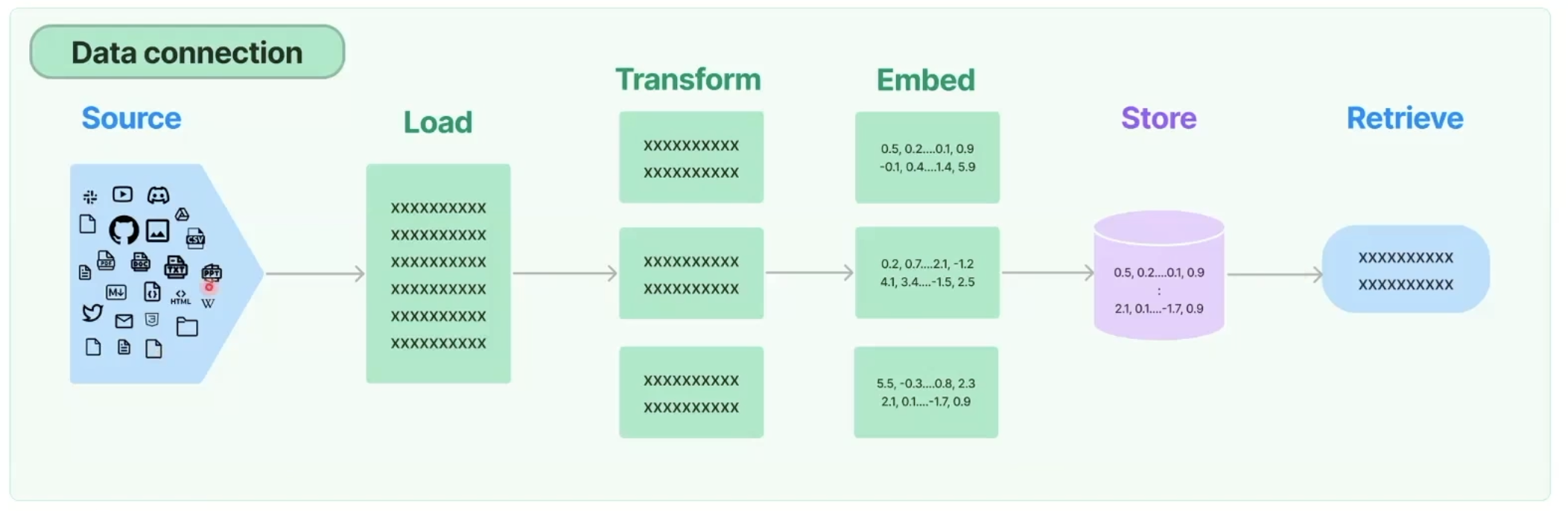
2. vector DB
Vector 데이터를 저장하고 sementic search를 할 수 있는 Database 입니다.
기존 데이터베이스도 vector를 저장하고 sementic search를 할 수 있지만, 저장된 모든 데이터의 vector와 query embedding의 vector와의 similarity를 연산해야 하기 때문에 너무 많은 연산으로 답변이 느려지게 됩니다. (기존 디비의 방식은 특정 키워드를 활용한 인덱스를 통한 서치 방식이기 때문에 항상 풀스캐닝하는건 비효율적입니다.)
유명한 벡터 DB에는 Pinecone / FAISS / Milvus / Weaviate 등등이 있습니다.
하지만 문제는 대부분 SAAS형태의 서비스라는것과 대용량 디비에는 그만한 비용이 들어갑니다. (SAAS는 관리측면에서의 이점이 있지만 데이터가 외부로 유출되기 때문에 문제가 됩니다.)
2.1 제가 선택한건 elastic search

우리가 검색 엔진으로 많이 사용하고 있는 elastic search에서도 벡터 검색을 지원합니다.
기본적으로 근사 최근접 이웃(ANN) 알고리즘 제공해주며 가장 저렴 + 가장 빠름 + 검증된 엔진 입니다. (사실 온프람환경에서 직접 구현한다면 당연히 더 비싸질수 있습니다!!)
aws opensearch로 지원중 (aws 커스텀 elastic search) 으로 손쉽게 사용 가능합니다.
주의할점!!
elastic search에서 지원하는 차원의 수는 최대 2048입니다. 즉, LLM에서 임베딩된 길이가 2048 이상인 경우엔 해당 모델은 elastic search에서 사용할수 없습니다.
저의 경우 4096 차원을 가진 모델로 테스트 하려 했지만 아래와 같은 에러메시지와 함께 실행되지 않았습니다.
BadRequestError(400, 'mapper_parsing_exception', 'The number of dimensions for field [question_embedding] should be in the range [1, 2048] but was [4096]')
추가로 앞으로도 차원의 수는 늘릴 계획이 없어 보입니다. (검색 엔진인 루씬 개발자들 사이에서는 차원이 많을수록 검색 속도와 정확성에 관련되어서 회의적으로 보입니다. )
https://github.com/apache/lucene/pull/874
LUCENE-10471 Increse max dims for vectors to 2048 by mayya-sharipova · Pull Request #874 · apache/lucene
Increase the maximum number of dims for KNN vectors to 2048. The current maximum allowed number of dimensions is equal to 1024. But we see in practice a number of models that produce vectors with >...
github.com
3. LLM 모델 선택
저는 임베딩에 사용할 LLM을 선택시에 다음을 기준으로 삼았습니다.
1. text -> vector embedding 되는지 확인 (실험 서버에서 돌아가나?)
2. text -> vector embedding 변환 및 테스트
- 실제 몇개의 샘플로 테스트를 해보면 특정 모델은 유사도가 이상하게 나올때가 있다 == 해당 도메인을 모델이 알수 없는 경우가 있다
- 한글을 지원하지 않는 경우 성능이 크게 떨어진다.
3. 벡터 디비에 저장
4. 성능 테스트
일반적인 LLM들은 해당 문장들을 학습되지 않은 상태(특정 도메일을 모르는 상태)에서는 좋은 임베딩결과를 기대하기 어렵습니다.
그럼에도 불구하고 좋은 성능이 나오면 가장 베스트 겠지만, 그럴일은 없습니다.....그렇기 때문에 최대한 많은 모델을 테스트 해야 합니다.
또한 사이즈가 큰 모델이 좋지 않을때도 있습니다. 오히려 작은 모델에서 더 좋은 성능이 나오기도 합니다.
마지막으로 테스트시 더 큰 모델을 사용하면 더 많은 계산 능력이 필요하므로 모든 데이터를 처리하는 데 더 많은 시간이 소요가 됩니다.
인퍼런스로 제공시 가용할 수 있는 자원을 생각하면서 모델을 선택해야 합니다.
다음 글에서는 실제 vector embedding 구현을 간단한 실습을 해보도록 하겠습니다.
아래는 코사인 유사도를 활용 영상입니다.
https://www.youtube.com/watch?v=UgnolyhTz-w
참고자료
https://kr-resources.awscloud.com/kr-on-demand/kr-fy23-q4-genai-session-01-deck
RAG 고급 개요
RAG 애플리케이션 설계 시 실질적인 고려 사항 (Chunking, Retrieval, HyDE, Rank-Fusion, Hybird 등) 발표자: 장동진 AIML SA, AWS
kr-resources.awscloud.com
'ML > LLM' 카테고리의 다른 글
| 3. 벡터 임베딩를 활용한 성과 지표 (다중 분류 문제) (1) | 2024.01.29 |
|---|---|
| 2-1. vector embedding 구현하기 (with faiss) (1) | 2024.01.04 |
| 1. 비속어 탐지 모델 만들기 (with bert) (2) | 2023.12.31 |
| 2. vector embedding 구현하기 (with elastic search) (2) | 2023.12.29 |
| llama2 / mistral fine tuning (with autotrain) (1) | 2023.12.26 |

