https://arxiv.org/pdf/2307.03172.pdf
요약 : 컨텍스트의 앞과 뒤에 중요한 문맥이 있다면 잘 알아듣는다. 중간에 있다면 품질이 떨어진다.

Abstract
최근의 언어 모델에는 긴 문맥 입력시 얼마나 잘 동작하는지 알려진 바가 거의 없습니다. 이 논문은 다중 문서 질문 답변과 키-값 검색에 대한 두 가지 작업에 대한 언어 모델의 성능을 분석합니다.
특히나 문맥 정보의 위치 변경시 현재 언어 모델이 긴 입력 컨텍스트에서 정보를 제대로 활용하지 못한다는 것을 나타냅니다. 특히 중요한 정보가 문맥의 시작 또는 입력 컨텍스트의 끝에서 발생하며, 모델이 관련 정보에 액세스해야 할 때 혹은 긴 컨텍스트에 대해서 성능이 크게 저하됩니다.
Introduction
언어 모델은 대화형 인터페이스, 검색 및 요약, 공동 작성 등 다양한 수행을 하며 프롬프트를 통해 다운스트림 작업을 수행합니다. 처리할 모든 관련 작업 사양과 데이터는 텍스트 입력 컨텍스트로 형식화되며, 모델은 생성된 텍스트 완성하여 반환합니다.

검색 결과 그래프에서 보이듯이 입력 컨텍스트의 맨 처음 또는 끝에 있는 관련 정보를 더 잘 사용합니다. 중간에 위치한 정보는 성능이 크게 저하됩니다.
연구 결과에 따르면 언어 모델에 긴 문맥을 제시하면 모델에 더 많은 정보를 제공함으로써 다운스트림 작업을 수행하는 데 도움이 될 수 있지만, 모델이 추론해야 하는 콘텐츠의 양이 증가하여 정확도가 떨어질 수 있습니다. 쿼리에 답변하기 위해 Wikipedia에서 검색 시 모델 성능이 포화되어 추가 문서를 효과적으로 사용하지 못한다는 것을 발견했습니다. [검색된 문서의 20개 대신 50개를 사용하면 성능이 약간만 향상됩니다.]
Multi-Document Question Answering
실험 설정 다중 문서 질문 답변 작업(Multi-Document Question Answering)에서 모델은 답변할 질문과 문서 중 하나의 문서에 답변이 포함된 k개의 문서를 제공합니다.
입력 컨텍스트 내에서 관련 정보의 위치를 조절하기 위해 문서의 순서와 답변이 포함된 문서의 위치를 변경합니다. 이 작업에서 입력 컨텍스트 길이를 조절하며 검색된 문서의 수를 늘리거나 줄입니다.



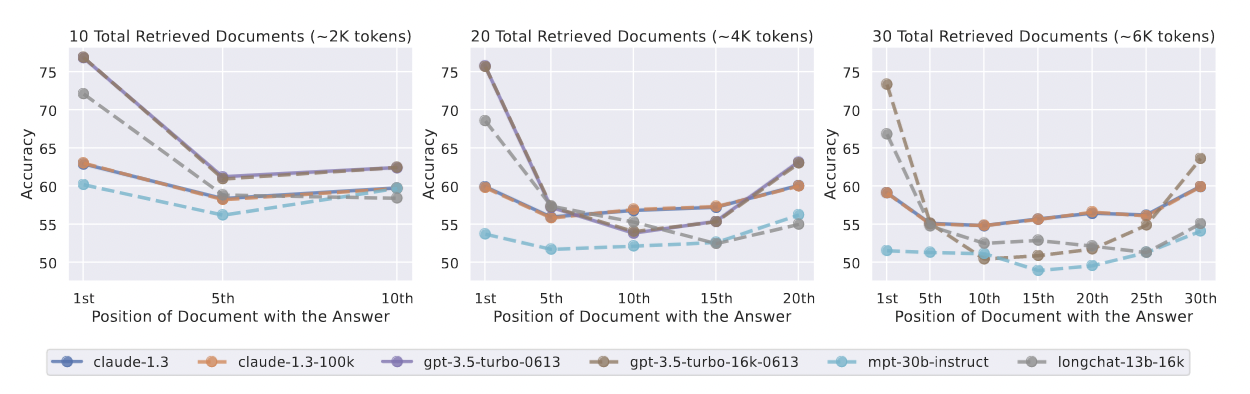
관련 정보가 컨텍스트의 맨 처음이나 끝에 있을 때 성능이 가장 높고, 모델이 입력 컨텍스트의 중간에 있는 정보를 추론해야 할 때 성능이 급격히 저하됩니다.
관련 정보가 입력 컨텍스트의 시작 또는 끝에서 발생할 때 모델 성능이 가장 높습니다. 입력 컨텍스트에서 관련 정보의 위치를 변경하면 모델 성능이 크게 저하됩니다.
모델은 컨텍스트의 맨 처음(우선 편향)과 맨 끝(최근 편향)에 있는 관련 정보를 훨씬 더 잘 사용하며, 입력 컨텍스트의 중간에 있는 정보를 사용하도록 강요하면 성능이 저하되는 것을 볼 수 있습니다. 예를 들어, GPT-3.5-Turbo를 사용하여 다중 문서 QA 성능은 20% 이상 떨어질 수 있으며, 최악의 경우 20개 및 30개 문서 설정에서의 성능은 입력 문서가 없는 성능보다 낮습니다. 이러한 결과는 현재 모델이 다운스트림 작업을 요청할 때 전체 컨텍스트 창을 효과적으로 추론할 수 없음을 나타냅니다.
언어 모델이 견고하지 않은 이유와 위치 변경에 대한 정보에 강하지 않은 이유는 무엇일까요?
query-aware contextualization
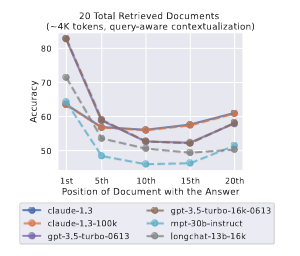
인코더-디코더 모델은 양방향 인코더를 사용하여 입력 컨텍스트를 맥락화합니다. 쿼리를 데이터 앞뒤에 배치하여 문서(또는 키-값 쌍)의 쿼리 인식 맥락화를 가능하게 한다면 디코더 전용 모델을 개선할 수 있을까요?
query-aware contextualization(쿼리 인식 문맥화)가 키-값 검색 작업의 성능을 크게 향상시키는 것으로 나타났습니다. 예를 들어 쿼리 인식 문맥화가 적용된 GPT-3.5-Turbo(16K)는 300개의 키-값 쌍으로 평가할 때 완벽한 성능을 달성합니다. 반면 쿼리 인식 문맥화가 없는 경우 최악의 성능은 45.6%입니다.
하지만 다중 문서 질문 답변 작업의 성능 추세에 미치는 영향은 미미하며, 관련 정보가 입력 문맥의 맨 처음에 위치할 때 성능이 약간 향상되지만 다른 설정에서는 성능이 저하됩니다.
Effect of Instruction Fine-Tuning
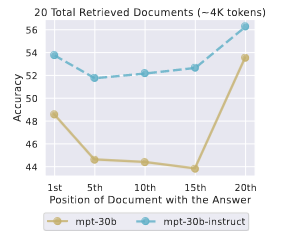
MPT-30B-Instruct의 다중 문서 QA 성능을 기본 모델인 MPT-30B와 비교했습니다. 두 모델 모두의 성능 곡선은 U자형이며, 여기서 성능은 입력 컨텍스트의 시작 또는 끝에서 관련 정보가 발생할 때 훨씬 더 높습니다.
MPT-30B-Instruct의 절대 성능은 MPT-30B보다 균일하게 높지만, 전반적인 성능 추세는 비슷합니다. 또한 미세 조정을 통해 최악의 경우 성능 격차가 기본 모델 최고 성능과 기본 모델의 최고 성능과 최악의 성능 격차가 약 4%로 줄어들었습니다.
컨텍스트 문서가 많을수록 더 좋은가요?
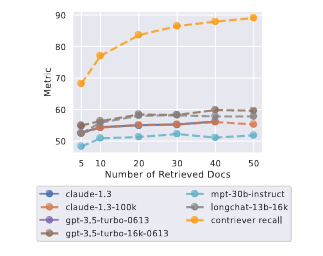
검색된 문서 수에 따른 모델 성능표 입니다. 모델 성능은 문서가 추가된다고 해서 성능이 높아지지 않았습니다.
검색된 문서를 20개 이상 사용하면 리더 성능이 약간만 향상되는 반면 입력 컨텍스트 길이는 크게 증가합니다. 이러한 결과는 입력 컨텍스트의 시작 또는 끝에 있는 정보를 검색하고, 검색된 문서의 효과적인 rerank시 모델이 더 효과적입니다.
결론
정보의 위치를 변경할 때 언어 모델 성능이 크게 저하되는 것으로 나타났는데, 이는 모델이 긴 입력 문맥에서 정보에 안정적으로 액세스하고 사용하는 데 어려움을 겪는다는 것을 의미합니다. 특히, 모델이 긴 입력 문맥의 중간에 정보를 사용해야 할 때 성능이 가장 저하되는 경우가 많았습니다.
'ML > LLM' 카테고리의 다른 글
| [논문리뷰] Retrieval-Augmented Generation for Large Language Models: A Survey (1) | 2024.02.19 |
|---|---|
| [논문리뷰] Precise Zero-Shot Dense Retrieval without Relevance Labels (HyDE) (0) | 2024.02.14 |
| 3. 벡터 임베딩를 활용한 성과 지표 (다중 분류 문제) (1) | 2024.01.29 |
| 2-1. vector embedding 구현하기 (with faiss) (1) | 2024.01.04 |
| 1. 비속어 탐지 모델 만들기 (with bert) (2) | 2023.12.31 |


