https://arxiv.org/pdf/2212.10496.pdf
결론 요약 : LLM에게 가상 문서(응답)를 생성하도록 지시한 후 이를 사용하여 유사한 문서를 찾으면 zero-shot dense retrieval 에서 검색 성능이 향상됩니다.
Abstract
고밀도 검색은 여러 작업과 언어에서 효과적이고 효율적인 것으로 나타났지만, 관련성 레이블이 없는 경우 검색 시스템을 구축하는 것은 여전히 어렵습니다. Hypothetical Document Embeddings(HyDE)을 통해 피벗할 것을 제안합니다. 쿼리가 주어지면 HyDE는 먼저 제로 샷으로 명령어 추종 언어 모델에 가상의 문서를 생성하도록 지시합니다.
벡터를 통해 말뭉치 임베딩 공간에서 벡터 유사성을 기반으로 유사한 실제 문서가 검색되는 이웃을 식별합니다. 이 두 번째 단계에서는 생성된 문서를 실제 말뭉치에 근거하여 인코더의 고밀도 병목 현상을 통해 잘못된 세부 정보를 걸러냅니다. 실험 결과 HyDE는 Contriever보다 훨씬 뛰어난 성능을 보였으며 미세 조정된 검색에 필적하는 강력한 성능을 보여주었습니다.
Introduction
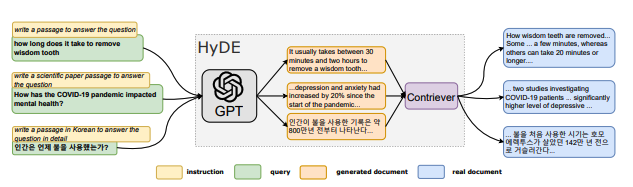
HyDE 모델의 그림으로 문서 스니펫(재사용가능한 부분)이 표시되어 있습니다. HyDE는 모델을 변경하지 않고 모든 유형의 쿼리를 처리합니다. 가상의 문서 임베딩(HyDE)을 통해 밀도 높은 검색을 수행합니다. 생성모델의 결과와 대조하여 문서 간 유사성 작업의 수행하는 두 가지 작업으로 진행됩니다.
첫번째, 생성 모델에 쿼리를 입력하고 "질문에 답하는 문서, 즉 가상의 문서를 작성"합니다. 생성된 문서는 실제 문서가 아니며 문서에 오류가 있을 수 있지만 관련성 있는 문서와 같은 예시를 제공합니다.
두 번째, 인코더를 사용하여 첫번째 문서를 벡터로 인코딩합니다. 이 벡터를 사용하여 말뭉치 임베딩에 대해 검색하여 가장 유사한 실제 문서가 반환됩니다.
HyDE
HyDE는 문서와 문서의 유사성 검색을 위해 전용 임베딩 공간에서 검색을 수행함으로써 앞서 언급한 할루시네이션 문제를 피할 수 있습니다.

정밀도 지향 지표와 recall 지표에서 볼수 있듯이 HyDE는 BM25를 큰 차이로 능가하며 미세 조정된 모델과 비교해도 좋은 성능을 발휘합니다.
참고사항
https://medium.com/papers-i-found/e11-hypothetical-document-embedding-hyde-acee7e56bd08
https://community.openai.com/t/hyde-based-semantic-search-enabled-on-the-openai-forum/361207
'ML > LLM' 카테고리의 다른 글
| [dacon] 도배 하자 질의 응답 처리 : 한솔데코 시즌2 AI 경진대회 (4) | 2024.02.28 |
|---|---|
| [논문리뷰] Retrieval-Augmented Generation for Large Language Models: A Survey (1) | 2024.02.19 |
| [논문리뷰] Lost in the Middle: Models Use Long Contexts (2) | 2024.02.13 |
| 3. 벡터 임베딩를 활용한 성과 지표 (다중 분류 문제) (1) | 2024.01.29 |
| 2-1. vector embedding 구현하기 (with faiss) (3) | 2024.01.04 |



