시간대 필터만 있는 쿼리와 id 조건을 함께 건 쿼리의 실행 시간이 극적으로 달랐습니다. 같은 테이블에서 같은 시간 범위를 조회했지만, 전자는 10분이 넘었고 후자는 2분도 걸리지 않았습니다.
문제 상황
두 쿼리는 선택 컬럼과 시간 범위가 동일합니다. 차이는 id 조건의 유무입니다.
-- A 조건
explain
SELECT
id, user_id, lotto_round_id, lottery_numbers, created_at
FROM lotto_lotteries
WHERE created_at >= '2025-05-22 00:00:00'
AND created_at < '2025-05-22 04:00:00';
-- B 조건
explain
SELECT
id, user_id, lotto_round_id, lottery_numbers, created_at
FROM lotto_lotteries
id > 392432840
AND created_at >= '2025-05-22 00:00:00'
AND created_at < '2025-05-22 04:00:00'
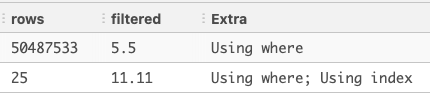
당연히 created_at에도 인덱스가 있고, id+created_at 복합 인덱스도 걸려 있다
데이터가 더 적지만(A : 40만건 vs B : 5천만 건), 실제 쿼리의 시간 차이는 엄청나게 난다.
- A: 10분 이상
- B: 2분 미만
핵심 원인
InnoDB는 클러스터형 PK 인덱스를 사용합니다. 즉, PK(id) 순서대로 데이터가 물리적으로 정렬됩니다.
- id > ...가 있으면 옵티마이저는 정확한 시작 지점을 PK 트리에서 찾고, 이후는 순차 스캔으로 달립니다. 디스크 접근이 선형적이라 유리합니다.
- created_at만 있으면, 인덱스가 있더라도 실제 행을 확인하기 위해 더 많은 랜덤 접근이 섞입니다. 특히 사용 중인 보조 인덱스의 선두 컬럼이 created_at이 아니면 더 비효율적입니다.
간단히 말해, B는 “딱 거기부터” 읽고, A는 “대략 그 근처를 넓게” 읽습니다.
B. id 조건이 있을 때
- 접근 경로: PRIMARY(PK) range scan
- 시작점: id > 392432840에서 곧바로 시작
- Extra: 보통 Using where 정도
- 특성: 순차적 I/O, 필요 구간만 빠르게 통과
A. id 조건이 없을 때
- 접근 경로: 시간대 필터 기준 보조 인덱스 range scan
- Extra: Using index condition; Using where가 자주 보임
- Using index condition은 Index Condition Pushdown(ICP). 인덱스 단계에서 일부 필터(created_at 등)를 미리 거르지만, 완전 판정은 테이블 레벨에서 해야 해서 랜덤 접근이 늘 수 있음.
- 특성: 인덱스 범위가 넓고, 테이블 확인이 많이 섞여 느림
추가로, 현장에서 종종 보이는 비효율 한 가지:
- 보조 인덱스가 (lotto_round_id, created_at)처럼 created_at이 선두가 아닐 때, created_at BETWEEN ... 조건은 두 번째 키라서 스캔 범위를 크게 줄이지 못합니다. 이 경우 EXPLAIN에
Index range scan on ... using idx_aull_on_lrid_created_at
같은 문구와 함께 Using index condition이 붙는 모습을 보게 됩니다.
결국
- 클러스터형 PK와 물리 정렬
InnoDB는 PK 기준으로 페이지가 정렬됩니다. 시작점이 명확하면 앞으로 쭉 읽으면 됩니다. - 랜덤 I/O vs 순차 I/O
시간 조건만 있는 경우, 보조 인덱스 → 테이블을 오가며 산발적 접근이 생기기 쉽습니다. 반면 PK 범위는 순차 접근 위주라 훨씬 유리합니다. - 스캔 범위의 명시성
id > ...는 옵티마이저에 “여기서부터만 보면 된다”는 강력한 힌트가 됩니다
최적화 체크리스트
- 읽기 시작점을 쿼리에 추가
가능하다면 시간 범위에 더해 id > anchor 같은 증분 앵커를 두세요. 페이징에도 같은 원리로 적용됩니다.
단, id와 created_at의 상관성이 아주 느슨한 데이터라면 필터 누락이 없도록 반드시 created_at 조건을 함께 둡니다. - 인덱스 선두 컬럼을 조건과 맞춰라
시간대 기준 조회가 빈번하다면 created_at이 선두인 보조 인덱스를 고려합니다. 예)- (created_at) 또는 (created_at, id)
- (created_at, lotto_round_id) 처럼 공선택 조건을 선두로
선두가 lotto_round_id이고 created_at이 뒤에 있는 형태는 시간 범위 조회에 불리합니다.
- 커버링 인덱스는 신중히
MySQL은 INCLUDE를 지원하지 않아 커버링 인덱스를 만들려면 키에 컬럼을 다 올려야 합니다. 쓰기 비용과 인덱스 크기가 커지므로,- 선택 컬럼을 줄일 수 있을 때만
- 정말 자주, 정말 빨라야 할 경로에만 고려합니다.
- 파티셔닝/샤딩도 옵션
대용량에서 시간대 조회가 절대적으로 많다면 created_at RANGE 파티셔닝으로 파티션 프루닝을 얻을 수 있습니다. 운영 복잡도와 이득을 저울질하세요. - 측정은 EXPLAIN이 아니라 EXPLAIN ANALYZE로
실제 읽은 row 수, 루프 횟수, 실제 시간 분포를 보고 판단합니다. 필요하면 OPTIMIZER_TRACE로 선택 경로를 확인합니다. - 버퍼 풀과 I/O 환경 점검
같은 계획이라도 버퍼 풀 적중률, 스토리지 종류(SSD/NVMe), 병렬 백그라운드 작업에 따라 체감이 크게 달라집니다.
'Database > DB' 카테고리의 다른 글
| ClickHouse - Lightning Fast Analytics for Everyone (0) | 2025.11.16 |
|---|---|
| Trino로 서로 다른 DB 조인하기 (MySQL ↔ PostgreSQL) (0) | 2025.09.06 |
| [논문] Presto: SQL on Everything / A Decade of SQL Analytics at Meta / History-based Query Optimizer (2) | 2025.08.27 |
| 3. MySQL CDC 데이터를 Debezium을 통해 Pub/Sub으로 전송하기 (1) | 2025.08.17 |
| 2. mysql master - slave Replication (2) | 2025.08.16 |
