https://www.vldb.org/pvldb/vol17/p3731-schulze.pdf
1 서론 (INTRODUCTION)
ClickHouse는 수조 행·수백 개 컬럼 테이블에 고성능 분석 쿼리를 실행하기 위해 설계된 컬럼 지향 OLAP 데이터베이스다.
1. 거대한 데이터와 높은 유입 속도로, 최신 데이터는 빠르게 적재하면서 과거 데이터는 백그라운드에서 집계·아카이브해 부담을 줄이는 것이다.
2 많은 동시 쿼리와 낮은 지연 시간으로, 프루닝 등으로 자주 쓰는 쿼리를 최적화하면서 CPU·메모리·디스크·네트워크 I/O를 공정하거나 우선순위 기반으로 나누는 것이다.
3 다양한 저장소·위치·포맷과의 통합으로, 어떤 시스템·위치·포맷이든 외부 데이터를 읽고 쓸 수 있을 만큼 개방적인 구조를 갖는 것이다.
4 쓰기 편한 SQL과 성능 분석 도구로, 표현력 있는 SQL 방언을 제공하면서 시스템과 개별 쿼리의 성능을 세밀하게 들여다볼 수 있게 하는 것이다.
5 산업 현장에서의 견고함과 배포 유연성으로, 노드 장애를 견딜 수 있는 데이터 복제를 제공하면서 다양한 하드웨어에서 네이티브 바이너리로 높은 성능을 내는 것이다.
2 ARCHITECTURE
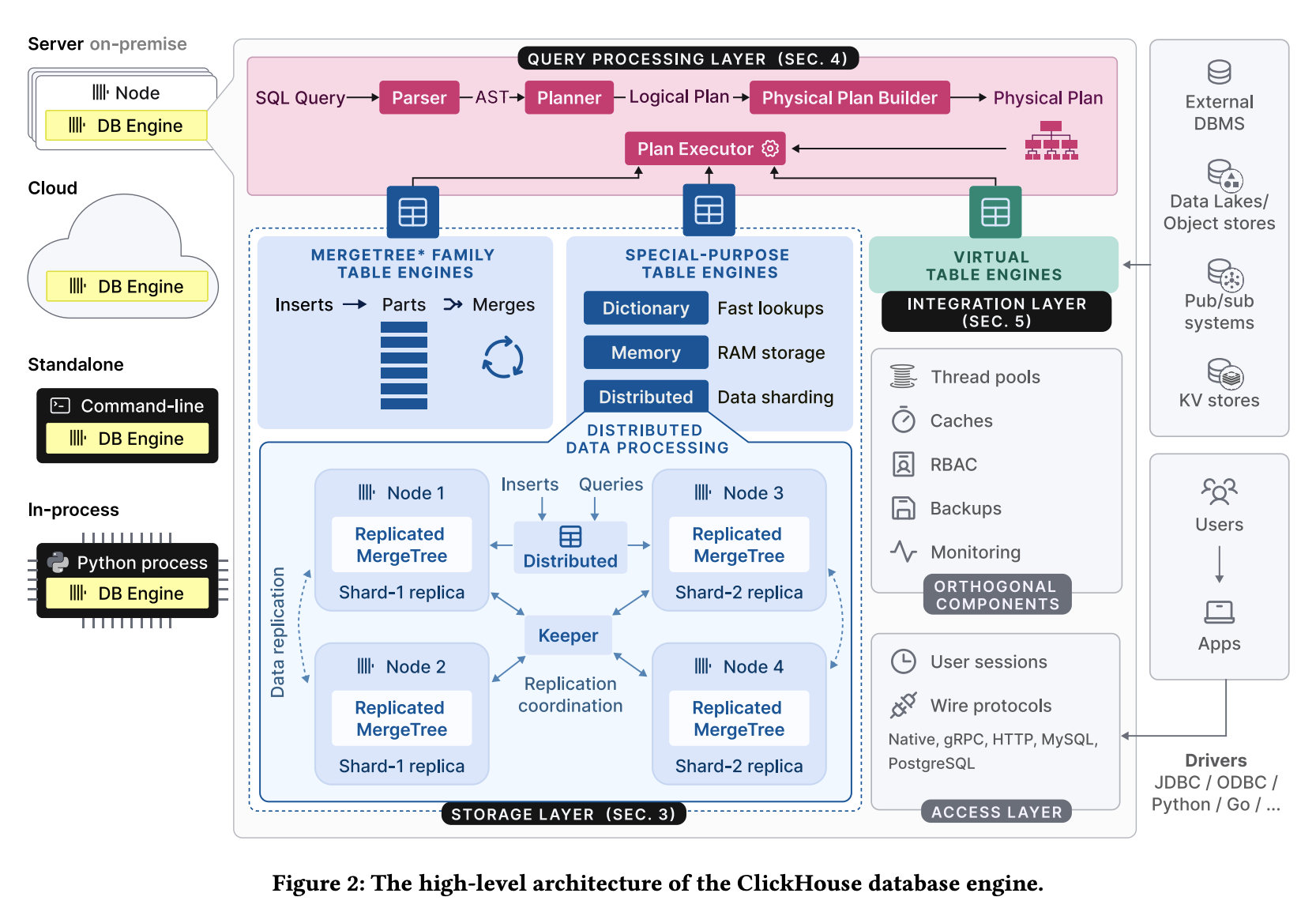
ClickHouse 엔진은 쿼리 처리 레이어, 스토리지 레이어, 통합 레이어와 이를 감싸는 액세스 레이어, 그리고 스레딩·캐시·RBAC·백업·모니터링 같은 수직 기능들로 구성되며, C++로 작성된 단일 정적 바이너리로 배포된다.
storage layer는 테이블 데이터의 **형식과 위치**를 캡슐화하는 다양한 테이블 엔진으로 구성되며, 크게 MergeTree 계열, 특수 목적 엔진, 가상(virtual) 엔진의 세 가지 범주로 나뉜다.
- MergeTree* 계열 테이블 엔진은 LSM 트리 아이디어를 기반으로 테이블을 정렬된 수평 파트들로 나눈 뒤 백그라운드에서 지속적으로 머지하고, 머지 과정에서 행을 집계하거나 오래된 행을 대체하는 방식 등으로 변형되는 방식을 엔진별로 달리한다.
- 특수 목적 테이블 엔진에는 주기적으로 내부/외부 소스에 쿼리해 결과를 캐시하는 인메모리 키-값 사전(dictionary)과 임시 테이블용 인메모리 엔진, 그리고 투명한 데이터 샤딩을 제공하는 Distributed 엔진 등이 포함된다.
- 가상 테이블 엔진은 PostgreSQL·MySQL 같은 관계형 DB, Kafka·RabbitMQ 같은 Pub/Sub 시스템, Redis 같은 키-값 저장소, Iceberg·DeltaLake·Hudi 같은 데이터레이크, S3·GCP 같은 오브젝트 스토리지와의 양방향 데이터 교환을 담당한다.
ClickHouse는 테이블을 샤딩 표현식에 따라 여러 노드의 독립적인 샤드들로 나누고, 클라이언트가 각 샤드를 직접 테이블처럼 다루거나 Distributed 엔진으로 전체를 하나의 글로벌 테이블처럼 볼 수 있게 함으로써, 단일 노드 용량을 넘는 대규모 데이터 처리와 읽기/쓰기 부하 분산을 동시에 지원한다.
각 샤드는 ReplicatedMergeTree* 엔진과 Raft 합의 알고리즘 기반 멀티 마스터 코디네이터(Keeper)를 통해 다수 노드에 복제되어, 설정한 복제본 수를 항상 유지함으로써 노드 장애에 대한 내결함성을 제공한다.
3. storage

MergeTree* 테이블은 여러 개의 변경 불가능한 파트(parts)로 구성되며, 각 INSERT가 하나의 파트를 만들고, 이 파트들은 필요한 메타데이터를 자체적으로 가지고 있다.
파트 수를 줄이기 위해 백그라운드 머지 작업이 여러 작은 파트를 최대 크기(기본 150GB)에 이를 때까지 정렬 기준(프라이머리 키)에 따라 k-way 머지 소트로 합치고, 사용이 끝난 원본 파트는 비활성 처리 후 삭제된다.
동기(insert) 모드에서는 각 INSERT가 바로 파트를 만들기 때문에 클라이언트는 머지 오버헤드를 줄이기 위해 한 번에 수만 건(예: 2만 행) 정도씩 벌크 삽입하는 것이 권장되지만, 실시간 분석이 필요하면 이런 지연이 문제 될 수 있다. 이를 위해 비동기(insert) 모드에서는 여러 INSERT에서 들어오는 행들을 테이블별 버퍼에 모아두었다가, 버퍼 크기가 임계값을 넘거나 타임아웃이 되면 한 번에 새로운 파트를 만든다.
ClickHouse는 전통적인 LSM 트리처럼 레벨 구조를 두지 않고 모든 파트를 동일하게 취급해 레벨에 관계없이 자유롭게 머지하지만, 그 대신 묘비(tombstone)에 의존하지 않는 별도의 UPDATE/DELETE 메커니즘과, WAL 대신 디스크에 직접 쓰는 방식을 사용한다.
하나의 파트는 디스크 상에서 디렉터리 하나에 대응되고 기본적으로 컬럼마다 하나의 파일을 가지며, 10MB보다 작은 작은 파트는 I/O 지역성을 위해 여러 컬럼을 하나의 파일에 연속으로 저장한다. 각 블록은 기본적으로 LZ4로 압축되고, 필요에 따라 Gorilla·FPC 같은 특수 부동소수점 코덱이나 델타 인코딩 후 압축 된다.
압축된 상태에서도 특정 granule(clickhouse에서 ㅆ느느 데이터 묶음 단위)에 빠르게 접근할 수 있도록, 각 컬럼마다 “granule ID → 해당 그라뉼이 들어 있는 압축 블록의 오프셋과 블록 내부의 위치”를 매핑하는 인덱스를 별도로 저장한다.
컬럼은 LowCardinality(T)를 사용해 값들을 정수 ID로 치환하는 딕셔너리 인코딩으로 저장 공간을 줄일 수 있고, Nullable(T)를 사용하면 NULL 여부를 나타내는 비트맵을 추가해 NULL 표현을 효율적으로 처리한다. 테이블은 임의의 표현식 기반으로 범위·해시·라운드로빈 파티셔닝을 할 수 있으며, 각 파티션마다 파티셔닝 표현식의 최소·최대 값을 저장해 파티션 프루닝을 가능하게 하고, 필요하면 HyperLogLog나 t-digest 같은 고급 통계 정보를 만들어 카디널리티 추정을 지원한다.

3.2 Data Pruning
페타바이트급 데이터를 매번 전체 스캔하는 것은 비싸기 때문에, ClickHouse는 대부분의 행을 건너뛸 수 있게 해주는 세 가지 데이터 프루닝 기법을 제공
첫 번째. 프라이머리 키 인덱스로, 각 파트 내 행을 프라이머리 키로 정렬하고 각 그라뉼의 첫 행 키값을 그라뉼 ID에 매핑하는 희소 인덱스를 메모리에 두어, 자주 필터링되는 컬럼에 대한 동등·범위 조건을 순차 스캔 대신 이진 탐색으로 처리. 이런 로컬 정렬과 인덱스 구조는 필요한 그라뉼만 읽게 해 쿼리를 빠르게 할 뿐 아니라, 머지 연산이나 정렬 기반 집계, 정렬 연산 제거 같은 쿼리 최적화에도 활용된다.
두 번째는 테이블 프로젝션으로, 같은 행을 다른 프라이머리 키로 정렬한 “보조 버전”을 만들어 메인 테이블 키와 다른 컬럼으로 필터링하는 쿼리를 빨리 처리하는 대신, insert / merge / storage 공간 오버헤드를 감수한다.
세 번째는 스키핑 인덱스로, 여러 그라뉼을 묶은 블록마다 작은 메타데이터를 저장해 그 블록 전체를 스캔에서 건너뛸 수 있게 하는 가벼운 구조다. (figure 4 참고) 스키핑 인덱스에는 느슨하게 정렬된 데이터에 잘 맞는 min-max 인덱스, 국소 카디널리티가 낮은 데이터에 적합한 set 인덱스, 텍스트 검색용으로 행·토큰·n-그램에 대한 Bloom 필터 인덱스가 있으며, Bloom은 범위나 부정 조건에는 사용할 수 없다는 제약이 있다.
3.3 Merge-time Data Transformation
BI나 모니터링처럼 데이터가 계속 많이 들어오는 경우를 위해, ClickHouse는 merge 시점에 집계·aggregating 같은 변환을 계속 돌려서 과거 데이터 양을 줄이되 INSERT 성능은 유지하도록 설계했다. 다만 머지 시점 변환만으로는 테이블에 오래된 값이나 아직 집계되지 않은 값이 잠시 섞여 있을 수 있고, 이런 값을 모두 반영한 결과가 필요하면 SELECT ... FINAL로 쿼리 시점에 강제로 머지/정리된 상태를 보장받을 수 있다.
Replacing merge는 같은 프라이머리 키를 가진 튜플들 중에서 가장 최근 파트(또는 지정한 버전 컬럼 기준)의 것만 남기고 나머지는 지워서, 자주 바뀌는 데이터에 대한 “머지 시점 UPDATE” 또는 중복 삽입 제거 용도로 쓴다.
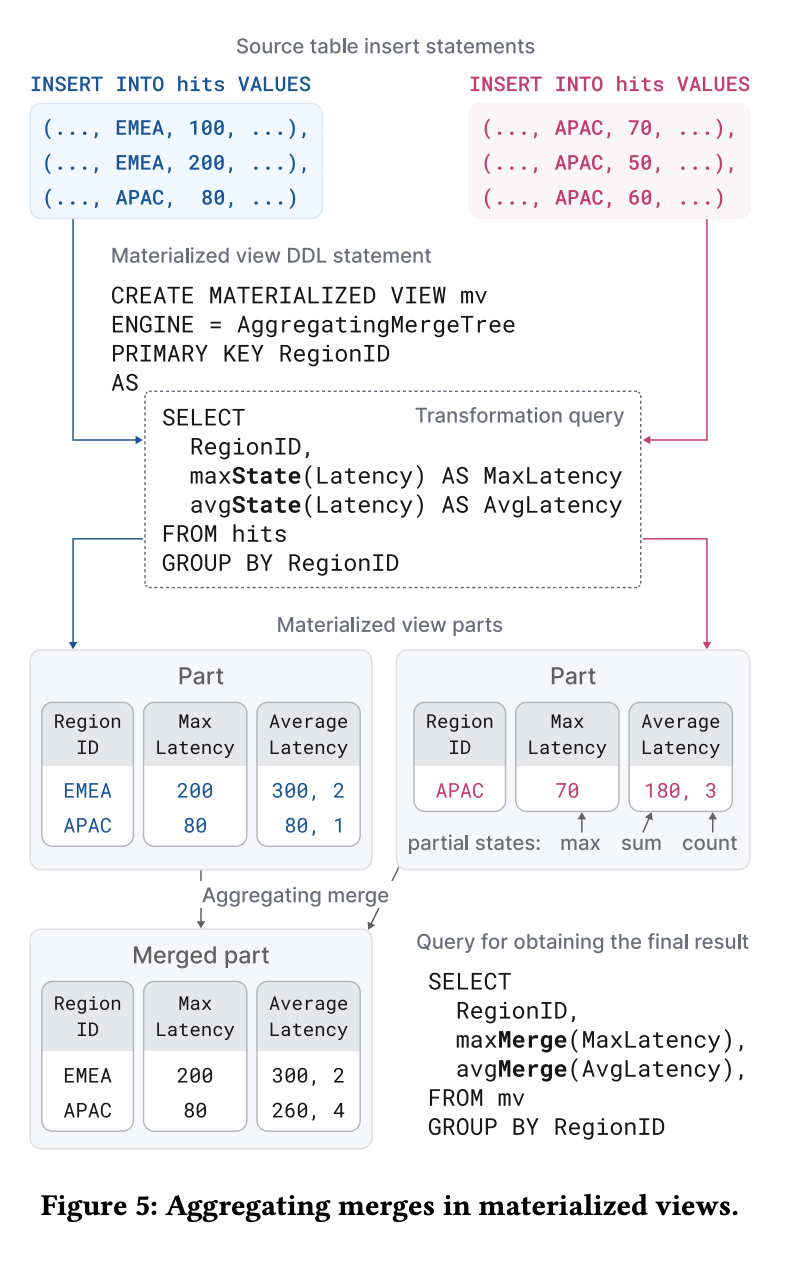
Aggregating merge는 프라이머리 키가 같은 행들을 하나의 집계된 행으로 합치는데, 키 컬럼들은 sum, count 같은 집계의 부분 상태(partial aggregation state)를 들고 있고, 머지 과정에서 이 부분 상태들끼리 계속 합쳐진다. 이런 Aggregating merge는 보통 원본 테이블 위에 쿼리 결과를 점진적으로 쌓는 materialized views에 사용되며, ClickHouse는 전체를 주기적으로 리프레시하는 대신 새로운 파트가 원본 테이블에 들어올 때마다 그 부분만 변환 쿼리를 돌려서 뷰를 “증분 업데이트” 한다.
materialized views에서는 avg-State, max-State처럼 -State 확장 집계 함수로 부분 상태를 저장하고, 나중에 쿼리 시 avg-Merge, max-Merge로 이 상태들을 최종 값으로 합쳐서 결과를 만든다.
3.6 Data Replication
데이터 복제는 노드 장애 대비 고가용성뿐 아니라 로드 밸런싱과 무중단 업그레이드를 위해 필요하며, ClickHouse에서는 “테이블 상태(파츠 집합 + 메타데이터)”를 여러 노드에 맞춰주는 방식으로 이를 구현한다.
테이블 상태는 INSERT(새 part 추가), MERGE(새 part 추가 + 기존 part 삭제), MUTATION·DDL(part 추가/삭제 + 메타데이터 변경)의 세 가지 연산으로 변하며, 각 연산은 먼저 특정 노드에서 로컬로 수행된 뒤 전역 복제 로그에 상태 전이로 기록된다.
복제 로그는 보통 세 개 정도의 ClickHouse Keeper 프로세스가 Raft 합의 알고리즘으로 관리하는 분산 코디네이션 레이어 위에 저장되어, 클러스터 모든 노드가 동일한 로그를 기준으로 상태를 맞추게 한다.
각 노드는 처음에는 동일한 로그 위치를 가리키고 있다가, 한 노드에서 INSERT·MERGE·MUTATION·DDL이 발생하면 그 기록이 복제 로그에 쌓이고, 다른 노드들은 이 로그를 비동기적으로 재생하면서 테이블 상태를 최신으로 수렴시켜 결과적으로 최종적(eventual) 일관성을 갖게 된다.
3.7 ACID Compliance
ClickHouse는 동시 읽기·쓰기 성능을 최대화하기 위해 락(latch)을 최소화하고, 쿼리 시작 시점에 관련 테이블들의 파트 전체에 대한 스냅샷을 잡아 그 스냅샷 기준으로만 쿼리를 실행하며, 쿼리 동안 해당 파트들의 참조 카운트를 올려 수정·삭제를 막는 방식의MVCC 스냅샷 격리를 사용한다. 이 구조 때문에, 스냅샷을 잡는 바로 그 시점에 동시에 일어난 쓰기들이 서로 다른 하나의 파트만 건드리는 예외적인 경우를 빼면 일반적인 SQL 문장은 완전한 ACID 트랜잭션으로 보장되지는 않는다. 실제로 ClickHouse의 많은 쓰기 중심 분석·의사결정 용도는 전원 장애 시 “아주 최근에 들어온 일부 데이터가 날아갈 수 있는” 정도는 감내하기 때문에, ClickHouse는 기본적으로 새 파트를 디스크에 즉시 fsync하지 않고 커널이 배치해서 쓰게 내버려 두어 원자성/내구성 일부를 희생하는 대신 쓰기 성능을 높이는 선택을 한다.
4 QUERY PROCESSING LAYER
ClickHouse는 SQL 쿼리를 물리 연산자 그래프로 바꾸고, 소스 연산자가 다양한 포맷의 입력을 읽고 싱크 연산자가 원하는 포맷으로 결과를 내보내는 구조를 사용한다. 쿼리 컴파일 시점에 물리 연산자 계획은 설정된 최대 워커 스레드 수(기본은 코어 수)와 테이블 크기에 따라 서로 겹치지 않는 범위를 처리하는 여러 개의 실행 lane으로 설정된다. 각 lane은 처리할 데이터를 서로 다른 범위로 쪼개 병렬 연산자들이 동시에 돌 수 있게 해주며, 병렬성을 최대한 살리기 위해 lane들은 가능한 한 늦게 합쳐진다.
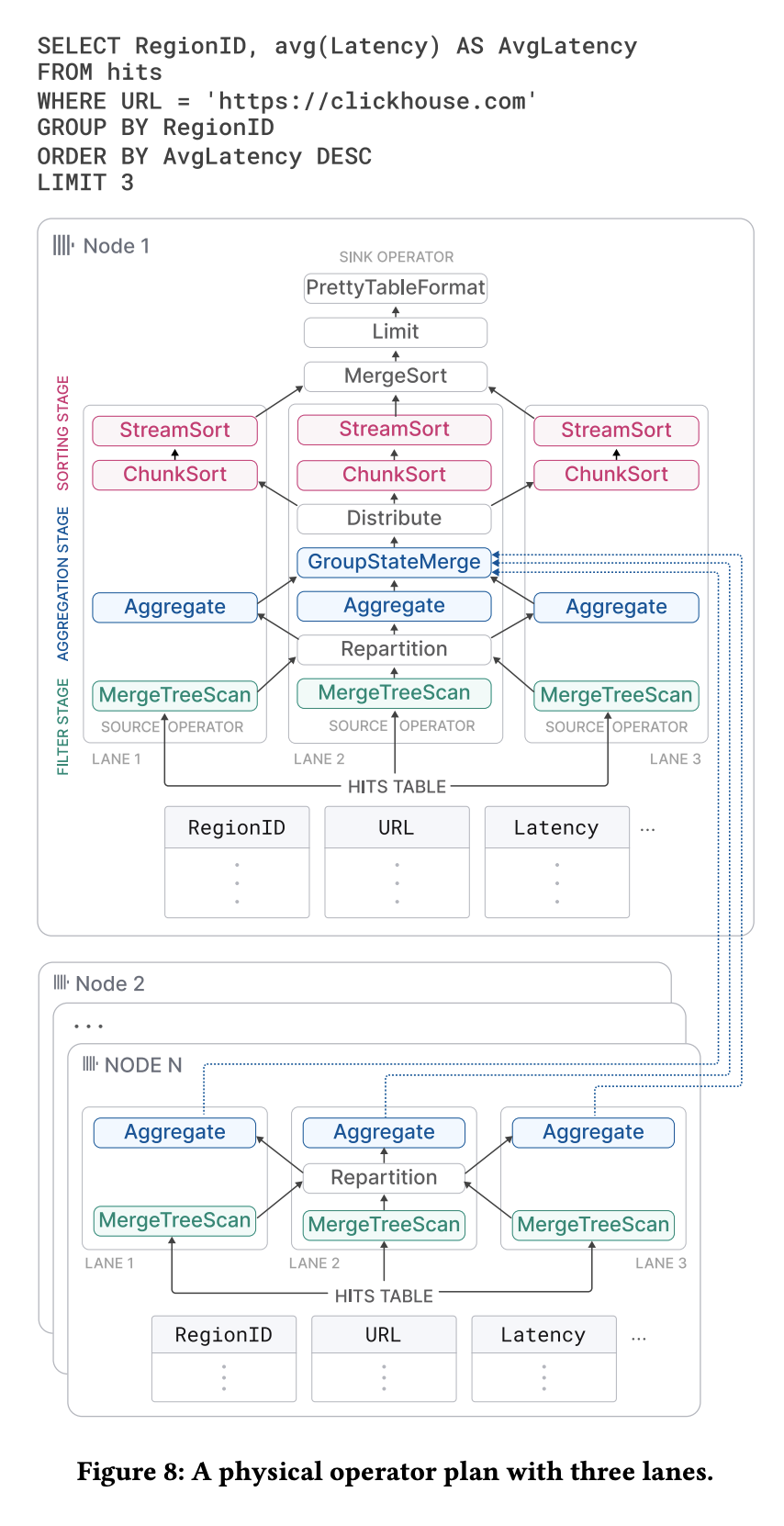
예시 쿼리에서 첫 번째 단계는 소스 테이블을 세 구간으로 나누어 동시에 필터링하고, Repartition 연산자가 결과 청크를 다음 단계의 스레드들 사이에 골고루 분배해 작업량을 균등하게 만든다. 두 번째 단계에서는 필터를 통과한 행들을 RegionID로 그룹핑하고, Aggregate 연산자가 그룹별 sum과 count 같은 평균 계산용 부분 집계 상태를 유지하다가 GroupStateMerge 연산자가 이것들을 전역 집계 결과로 합친다.
GroupStateMerge는 파이프라인 브레이커 역할을 해서, 이 전역 집계가 모두 끝나야만 다음 단계(정렬 단계)가 시작될 수 있다. 세 번째 단계에서는 Distribute 연산자가 결과 그룹을 세 개의 균등한 파티션으로 나누고, 각 파티션을 AvgLatency 기준으로 ChunkSort → StreamSort → MergeSort 순서의 3단계 정렬로 정렬해 최종 결과를 만든다.
각 연산자는 need-chunk, ready, done 세 상태를 오가는 상태 머신으로 모델링되며, 워커 스레드가 연산자 그래프를 돌아다니면서 입력 청크를 넣고(output 비우고) 상태 전이들을 수행한다.
4.4 Holistic Performance Optimization
Query optimization는 AST 단계에서 상수 폴딩·공통 부분식 제거·OR → IN 변환 등을 하고, 논리 플랜 단계에서 필터 푸시다운·정렬/함수 순서 조정 등을 한 뒤, 물리 플랜 단계에서 MergeTree의 정렬 특성을 이용해 ORDER BY·GROUP BY가 프라이머리 키 프리픽스일 때 디스크 순서로 읽으면서 정렬 연산을 없애거나, 해시 집계 대신 메모리를 덜 쓰는 sort aggregation을 사용하는 식으로 최적화한다.
Query compilation은 가상 함수 호출을 줄이고 레지스터·캐시 활용과 분기 예측을 개선하며, 자주 반복되는 표현식·집계·다중 정렬키 연산에 대해서만 컴파일을 트리거해 캐싱해두고 재사용한다.
프라이머리 키 인덱스 평가에서는 WHERE 조건의 일부가 프라이머리 키 프리픽스를 이룰 때 키 범위를 사전식으로 스캔하며 삼값 논리로 “전부 참/전부 거짓/섞임”을 판단해 섞인 구간만 재귀적으로 쪼개고, 함수의 단조성이나 역함수(프리이미지)를 이용해 toYear(k) = 2024 같은 조건을 k BETWEEN '2024-01-01' AND '2024-12-31' 식의 범위 비교로 바꿔서 인덱스를 더 잘 쓰게 만든다.
Data skipping은 프루닝용 데이터 구조들을 활용하면서, 여러 컬럼 필터를 “추정 선택도가 높은 순서”로 차례대로 적용해 한 단계에서라도 매칭이 없는 청크는 바로 버림으로써 읽는 데이터와 연산량을 점점 줄이고, 이런 순차 평가가 이득이 되는 경우(강한 필터가 있을 때)에만 쓰고 그렇지 않으면 병렬 평가로 둔다.
해시 테이블 최적화는 ClickHouse는 해시 함수·셀 타입·리사이즈 정책 등을 조합한 30개 이상의 해시 테이블 변형 중에서 키 타입·예상 카디널리티 등에 맞는 걸 연산자별로 골라 쓰고, 2계층 파티셔닝, 문자열 길이별 특화 테이블, 직접 인덱싱 lookup table, 해시 내장 값, 예측 기반 초기 크기, slab 위에 여러 해시맵 할당, 버전 카운터로 O(1) 초기화, CPU prefetch 같은 마이크로 최적화까지 적용한다.
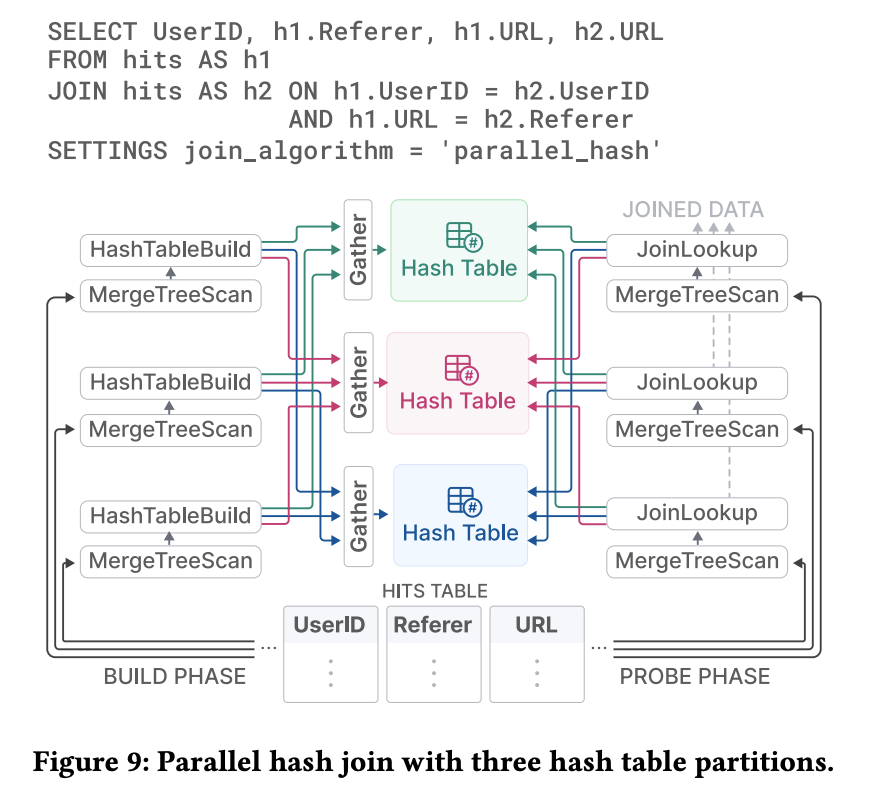
조인 최적화 측면에서 ClickHouse는 이제 SQL의 모든 조인 타입과 해시/정렬 병합/인덱스 조인 알고리즘을 제공하며, 특히 해시 조인에서는 전역 해시 테이블 대신 파티션된 해시 테이블과 non-blocking shared partition 알고리즘을 써서 빌드/프로브를 여러 lane으로 나누고 각 튜플에 두 번의 해시 계산을 더 하는 대신 파티션별로 락 경쟁을 줄여 병렬성을 높인다.
'Database > DB' 카테고리의 다른 글
| Trino로 서로 다른 DB 조인하기 (MySQL ↔ PostgreSQL) (0) | 2025.09.06 |
|---|---|
| MySQL id 범위 조건 하나로 10분 → 2분 (0) | 2025.09.04 |
| [논문] Presto: SQL on Everything / A Decade of SQL Analytics at Meta / History-based Query Optimizer (2) | 2025.08.27 |
| 3. MySQL CDC 데이터를 Debezium을 통해 Pub/Sub으로 전송하기 (1) | 2025.08.17 |
| 2. mysql master - slave Replication (2) | 2025.08.16 |

