해당 논문의 원문은 여기에서 볼수 있습니다.
https://arxiv.org/pdf/2312.10997.pdf
요약: LLG함께 RAG도 많은 발전이 이뤄졌다. 상황에 맞는 RAG를 선택하고 구축한다면, 더 좋은 품질의 LLM 결과를 얻을 수 있다.
Abstract
대규모 언어 모델(LLM)은 상당한 기능을 보여주지만 환각, 오래된 지식, 알수없는 추론 과정 등의 문제에 직면해 있습니다. 검색 증강 세대(RAG)는 모델의 정확성과 신뢰성을 향상시키고 지속적인 지식 업데이트 및 통합 지속적인 업데이트와 통합이 가능하여 유망한 솔루션으로 부상했습니다.
이 논문은 RAG 패러다임의 발전 과정을 자세히 살펴보며 ( Naive RAG, Advanced RAG, Modular RAG ) RAG 평가를 위한 메트릭과 벤치마크 모델과 최신 평가 프레임워크도 소개하며, 향후 연구 방향을 제시합니다.
introduction
Lewis가 2020년 중반에 소개한 RAG는 LLM 영역의 패러다임으로 자리 잡았습니다.
RAG는 LLM이 외부 데이터를 쿼리하여 관련 정보를 얻은 후 질문에 답하거나 텍스트를 생성하는 검색 단계를 포함합니다. 이 프로세스는 생성 단계에 정보를 제공할 뿐만 아니라 검색된 데이터에 근거한 응답을 보장하여 '환각'이라고 불리는 결과물의 정확성과 관련성을 크게 향상시킵니다.
LLM에서 RAG는 빠르게 채택되고 있으며 챗봇의 기능을 개선하고 실용적인 애플리케이션에 더욱 적합한 LLM의 중추적인 기술이 되었습니다.

RAG는 트랜스포머 아키텍처와 함께 사전 교육 모델(PTM)을 통한 추가적인 지식을 학습것에 중점이였지만, GPT 등장전까지는 크게 주목받지 못했다. chatGPT의 등장으로 RAG는 LLM을 최전선으로 끌어올리는 중추적인 순간이 되었습니다
Definition

위의 그림은 일반적인 RAG 애플리케이션 워크플로우를 보여줍니다. 이 시나리오에서는 사용자가 최근의 주요 사건(예: 갑작스러운 해고 및 복직)에 대해 ChatGPT에 문의합니다. 가장 유명하고 널리 활용되는 LLM인 ChatGPT는 사전 학습 데이터의 제약으로 인해 최근 사건에 대한 지식이 부족합니다. RAG는 외부에서 최신 문서를 검색하여 이러한 격차를 해소합니다. 이 예제에서는 문의 내용과 관련된 뉴스 기사를 선별하여 초기 질문과 함께 프롬프트에 통합되어 ChatGPT가 정보에 입각한 답변을 합성할 수 있도록 합니다. 이 예는 RAG 프로세스를 설명하며, 실시간 응답을 통해 모델의 응답을 향상시키는 기능을 보여줍니다.
RAG 워크플로우는 세 가지 주요 단계로 구성됩니다.
먼저, 말뭉치를 코퍼스를 개별 청크로 분할하고, 그 위에 인코더 모델을 사용해 벡터 인덱스를 구축합니다.
둘째, RAG는 쿼리 및 색인된 청크에 대한 벡터 유사성을 기반으로 청크를 식별하고 검색합니다.
마지막으로 모델은 검색된 청크에서 수집된 정보에 기반하여 정보를 바탕으로 응답을 합성합니다.
이러한 단계는 RAG 프로세스의 기본 프레임워크를 형성하며, 정보 검색 및 문맥 인식 생성 기능이 뒷받침되어야 합니다.
RAG Framework

navie RAG
Naive RAG는 색인, 검색 및 생성을 포함하는 전통적인 프로세스를 따릅니다.
indexing
인덱싱 프로세스는 원본 데이터를 정리하고 추출하는 데이터 인덱싱으로 시작하여 PDF, HTML, Word, 및 마크다운과 같은 다양한 파일 형식을 표준화된 일반 텍스트를 임베딩 모델을 통해 벡터 표현으로 변환됩니다. 인덱스는 이러한 텍스트 청크와 벡터 임베딩을 키-값 쌍으로 저장하여 효율적이고 확장 가능한 검색 기능을 제공합니다.
Retrieval
사용자가 질의를 하면 시스템은 인덱싱 단계에서 사용된 것과 동일한 인코딩 모델을 사용하여 입력된 문장을 벡터 표현으로 변환합니다. 그런 다음 쿼리 벡터와 색인된 말뭉치 내의 벡터화된 청크 간의 유사성 점수를 계산합니다. 시스템은 쿼리와 가장 높은 유사도를 보이는 상위 K개를 검색합니다.
생성
제시된 쿼리와 선택된 문서가 일관된 프롬프트로 합성되어 대규모 언어 모델이 응답을 구성하는 작업을 수행합니다. 답변에 대한 모델의 접근 방식은 작업별 기준에 따라 달라질 수 있으며, 제공된 문서에 포함된 정보로 응답을 제한할 수 있습니다. 대화가 진행 중인 경우 기존 대화 기록을 프롬프트에 통합하여 모델이 여러 차례에 걸친 대화 상호 작용에 효과적으로 참여할 수 있도록 할 수 있습니다.
navie RAG의 단점
검색 품질이 낮은 정밀도로 인해 품질이 낮을수 있으며, 환각의 잠재적 문제가 야기됩니다. 또한 리콜률이 낮으면 관련 청크를 모두 검색하지 못하여 종합적인 대응책을 마련하는 데 방해가 됩니다. 오래된 정보는 문제를 더욱 악화시켜 잠재적으로 부정확한 검색 결과를 초래할 수 있습니다. 응답 생성 품질은 모델이 제공된 컨텍스트에 근거하지 않은 답변을 생성하는 환각 문제와 질의와 관련 없는 컨텍스트 및 모델 출력의 잠재적 편향성 문제를 야기합니다.
검색된 구절의 컨텍스트를 현재와 관련 없는 일관성 없는 결과물로 이어질 수 있습니다. 검색된 답변이 여러개일 경우 중요도와 관련성을 파악해야 합니다. 또한, 글쓰기 스타일과 어조의 차이를 조정하여 일관성을 유지하는 것도 중요합니다.
Advanced RAG
Advanced RAG는 navie RAG의 단점을 보완하기 위해 개선된 기능으로 개발되었습니다. Advanced RAG는 사전 검색과 사후 검색 전략을 구현합니다. navie RAG에서 겪었던 색인 문제를 해결하기 위해, Advanced RAG는 슬라이딩 윈도우, 세분화된 세분화, 메타데이터와 같은 기술을 사용해 색인 방식을 개선했습니다. 또한 검색 프로세스를 최적화하기 위한 다양한 방법도 도입했습니다.
사전 검색 프로세스 데이터 색인 최적화: 데이터 색인 최적화의 목표는 색인되는 콘텐츠의 품질을 향상시키며 여기에는 데이터 품질 향상, 인덱스 구조 최적화, 메타데이터 추가, 정렬 최적화, 혼합 검색의 다섯 가지 기본 전략이 포함됩니다.
데이터 품질 향상은 텍스트 표준화, 일관성, 사실적 정확성, 풍부한 컨텍스트를 높여 RAG 시스템의 성능을 개선하는 것을 목표로 합니다. 여기에는 관련 없는 정보 제거, 엔티티 및 용어의 모호성 제거, 정확성 확인, 문맥 유지, 그리고 오래된 문서를 업데이트합니다.
인덱스 구조의 최적화에는 청크의 크기 조정이 포함됩니다. 청크의 크기를 조정하고, 여러 인덱스 경로에 걸쳐 쿼리하고 인덱스 경로를 쿼리하고, 그래프에서 정보를 통합하여 구조의 정보를 통합하여 그래프 데이터 인덱스의 노드 간의 관계를 활용하여 관련 컨텍스트를 구성합니다.
메타데이터 정보 추가에는 날짜 및 목적과 같은 참조된 메타데이터를 청크에 통합하는 작업이 포함됩니다. 필터링 목적으로, 그리고 챕터와 같은 메타데이터를 통합하고 및 참조의 하위 섹션과 같은 메타데이터를 통합하여 검색 효율성을 개선합니다.
정렬 최적화는 정렬 문제를 해결하고 "가상의 질문"을 도입하여 문서 간의 불균형을 해결합니다.
Retriveal
Retrival 단계에서는 쿼리와 청크 간의 유사성을 계산하여 적절한 문맥을 식별하는 데 중점을 둡니다. Advanced RAG에서는 임베딩 미세 조정(fine tuning)을 통해 RAG 시스템에서 검색된 콘텐츠의 관련성에 큰 영향을 미칩니다. 전문 도메인의 경우 도메인별 컨텍스트에서 검색 관련성을 높이기 위해 임베딩 모델을 사용자 정의하는 작업이 포함됩니다. 동적 임베딩은 각 단어에 대해 단일 벡터를 사용하는 정적 임베딩과 달리 단어가 사용되는 문맥에 맞게 조정됩니다. 예를 들어 BERT와 같은 트랜스포머 모델에서는 같은 단어라도 상황에 따라 주변 단어에 따라 다양한 임베딩을 가질 수 있습니다. OpenAI의 임베딩-ada-02 모델3 은 GPT와 같은 LLM의 원리를 기반으로 구축된 정교한 동적 임베딩 모델로 문맥 이해를 포착합니다. 하지만 문맥에 대한 민감도가 최신의 문맥에 대한 민감도는 떨어질 수 있습니다.
Post-Retrieval
Process 데이터베이스에서 중요한 컨텍스트를 검색한 후에는 이를 쿼리와 병합하여 LLM에 입력하는 것이 필수적입니다. 단순히 모든 관련 문서를 한 번에 LLM에 제시하면 컨텍스트 한도를 초과하고, 노이즈가 발생하며, 중요한 정보에 집중하는 데 방해가 될 수 있습니다. 검색된 콘텐츠의 추가 처리 검색된 콘텐츠의 순위 재조정에 대한 추가 처리가 필요합니다. 검색된 정보의 순위를 다시 지정하여 가장 관련성이 높은 콘텐츠를 프롬프트의 가장자리로 재배치하는 것은 핵심 전략입니다. LangChain5, HayStack 프레임워크에 구현되었습니다. 컨텍스트 창의 시작과 끝에 가장 좋은 문서를 번갈아 배치합니다. bge-rerank7 , LongLLMLingua 프레임워크에서는 관련 텍스트와 쿼리 간의 의미적 유사성을 다시 계산하여 쿼리 사이의 의미적 유사성을 계산하여 해석의 문제를 해결합니다.
검색된 문서의 노이즈는 RAG 성능에 부정적인 영향을 미칩니다. 후처리에서는 관련 없는 문맥을 압축하고, 중요한 단락을 강조하고, 전체 문맥을 줄여야 합니다. Recomp에서는 다양한 단위로 압축기를 훈련하여 이 문제를 해결합니다.
Modular RAG
Modular RAG 구조는 검색 모듈을 통합하여 유사도 검색을 위한 검색 모듈을 통합하고 retrieval에 미세 조정 접근 방식을 적용하는 등 다양한 방법을 통합합니다. RAG 모듈 활용 및 반복적 인 방법론을 통해 특정 문제를 해결하기 위해 개발되었습니다.
New Modules
검색 모듈 : 검색 엔진, 텍스트 데이터, 표 형식 데이터 및 지식 포함 그래프를 검색하기 위한 추가적인 말뭉치, LLM에서 생성된 코드와 생성된 코드, SQL 또는 Cypher와 같은 쿼리 언어, 기타 사용자 정의 도구를 사용하여 이루어집니다.
메모리 모듈 : 검색을 안내하기 위해 LLM의 메모리 기능을 활용합니다.
fusion : LLM을 사용하여 사용자 쿼리를 여러 가지 다양한 관점으로 확장하는 다중 쿼리 접근 방식
라우팅 : 상황에 따라 문서를 번갈아 가며 사용하거나 병합할 수 있습니다
predict : 검색된 콘텐츠의 중복 문제와 콘텐츠의 노이즈와 같은 일반적인 문제를 해결
navie naive / advence와 다르게 모듈 추가 또는 교체를 통해 검색-읽기 프로세스의 핵심 구조를 유지하면서 특정 기능을 강화하기 위해 추가 모듈을 통합하여 성능을 개선할 수 있습니다.
HyDE는 생성된 답변이 직접 쿼리보다 임베딩 공간에서 임베딩 공간에 더 가깝다는 믿음으로 작동합니다.
HyDE는 LLM을 사용하여 쿼리에 대한 응답으로 가상의 문서(답변)를 생성합니다. 쿼리에 대한 응답으로 가상의 문서(답변)를 생성하고, 이 문서를 임베딩 결과를 사용해 가상의 문서와 유사한 실제 문서를 검색합니다. 이 접근 방식은 답변에서 다른 답변으로의 임베딩 유사성에 초점을 맞춥니다
하지만 언어 모델이 주제에 익숙하지 않은 경우 바람직한 결과를 일관되게 생성하지 못할 수 있으며, 잠재적으로 더 많은 오류를 발생시킬 수 있습니다.
Retrieval
Enhancing Semantic Representations
Chunk optimization : 모델 / 도메인마다 최적의 블럭 크기에 따라 성능 특성이 나타난다. 하지만 ‘최고의 단위’는 없다. 상황에 따라 맞게 조정해야 한다.
Fine-tuning Embedding Models : 도메인에 맞는 fine tuning을 통해 성능 향상 가능, 정확히는 임베딩이 최적값에 맞춰질수 있다.
Aligning Queries and Documents
쿼리 재작성 쿼리와 문서의 의미를 일치시키기 위한 기본적인 접근 방식입니다. LLM을 활용하여 원본 쿼리와 추가 지침을 결합하여 문서를 생성합니다. HyDE는 텍스트 단서를 사용하여 쿼리 벡터를 구성하여 필수 패턴을 포착하는 '가상' 문서를 생성합니다.
다중 쿼리 검색 방법은 LLM을 사용하여 여러 검색 쿼리를 동시에 생성하고 실행하여 여러 하위 문제가 있는 복잡한 문제를 해결하는 데 유리합니다.
Generation
RAG의 중요한 구성 요소 중 Generation는 검색된 정보를 일관성 있고 유창한 텍스트로 변환하는 부분입니다. 기존 언어 모델과 달리 RAG의 제너레이터는 검색된 데이터를 통합하여 정확도와 관련성을 향상시킴으로써 차별화됩니다. RAG에서 생성기의 입력은 일반적인 문맥 정보뿐만 아니라 리트리버를 통해 얻은 관련 텍스트 세그먼트도 포함합니다. 이러한 포괄적인 입력을 통해 생성기는 질문의 맥락을 깊이 있게 이해할 수 있으므로 보다 유익하고 맥락에 맞는 답변을 생성할 수 있습니다.
Post-retrieval with Frozen LLM
대규모 모델에는 문맥 길이의 제한과 중복 정보에 대한 민감성 등의 문제가 여전히 남아 있습니다. 이러한 문제를 해결하기 위해 일부 연구에서는 post-retrieval(검색 후 처리)에 초점을 맞추고 있습니다. post-retrieval에는 대규모 문서 데이터베이스에서 검색기가 검색한 관련 정보를 처리, 필터링, 최적화하는 작업이 포함됩니다. 주요 목표는 검색 결과의 품질을 향상시켜 사용자 요구 사항이나 후속 작업에 더 가깝게 정렬하는 것입니다. 검색 단계에서 얻은 문서를 Information compression(정보 압축)과 result rerank(결과 재순위)이 있습니다.
Information compression(정보 압축)는 방대한 지식 기반에서 관련 정보를 검색하는 데 탁월하지만, 검색 문서 내의 상당한 양의 정보를 관리하는 것은 어려운 과제입니다. 이 문제를 해결하기 위해 대규모 언어 모델의 컨텍스트 길이를 확장하는 것을 목표로 하고 있습니다. 그러나 현재의 대규모 모델은 여전히 문맥의 한계로 인해 어려움을 겪고 있습니다.
정보 압축은 노이즈를 줄이고, 문맥 길이 제한을 해결하며, 생성 효과를 향상시키는 데 중요한 역할을 합니다.
PRCA는 문맥 추출 단계에서는 입력 텍스트 input이 주어지면 입력 문서에서 압축된 문맥을 나타내는 출력 시퀀스 extracted를 생성합니다.
또한 모델의 답변 정확도를 높이기 위해 문서 수를 줄이는 것을 목표로 삼아 다른 접근 방식을 취했습니다. LLM과 소규모 언어 모델(SLM)의 강점을 결합한 "filter-ranker" 패러다임을 제안합니다. LLM에 식별한 까다로운 샘플을 재배열하도록 지시하면 다양한 정보 추출 작업에서 상당한 개선 효과를 얻을 수 있습니다.
Reranking 은 retrieval에서 검색된 문서 집합을 최적화하는 데 핵심적인 역할을 합니다. 언어 모델은 추가 컨텍스트가 도입될 때 성능 저하 문제에 직면하는데, reranking은 이 문제를 효과적으로 해결합니다. 핵심 개념은 문서 레코드를 재배열하여 가장 관련성이 높은 항목의 우선순위를 맨 위에 두어 총 문서 수를 제한하는 것입니다. 이렇게 하면 검색 중 컨텍스트 확장 문제를 해결할 뿐만 아니라 검색 효율성과 응답성을 향상시킵니다.
Contextual compression(문맥 압축)은 보다 정확한 검색 정보를 제공하기 위해 재정렬 프로세스에 통합됩니다. 이 방법은 개별 문서의 내용을 줄이고 전체 문서를 필터링하는 것을 수반하며 검색 결과에서 가장 관련성이 높은 정보 표시 관련성 높은 콘텐츠를 보다 집중적이고 정확하게 표시하는 것입니다.
Augmentation in RAG

pre-training stage
검색 기반 전략을 통해 임베딩, 사전 학습, 미세 조정을 통해 구조화되고 해석 가능한 방법을 채택하여 검색 후 데이터를 예측한 답변을 채택합니다 또한 효율적인 벡터 검색 도구를 활용하여 텍스트 조각의 문맥적으로 의미 있는 표현을 계산하여 질문-답변 및 도메인 적응과 같은 영역에서 우수한 성능을 보여줍니다.
fine-tuning stage
RAG와 미세 조정를 결합하면 보다 구체적인 시나리오의 요구를 충족시킬 수 있습니다. 미세 조정을 통해 쿼리와 문서 간의 차이를 조정하여 검색기의 출력이 시나리오에 더 적합하도록 보장합니다. 시맨틱 표현의 품질 향상과 특정 검색에 맞는 문맥으로 미세 조정하여 검색에 대한 성능을 향상 시킵니다.
미세 조정의 장점에도 불구하고 RAG 미세 조정을 위한 특수 데이터 세트가 필요하고 상당한 컴퓨팅 리소스가 필요하다는 등의 한계가 있습니다.
inference stage
naive RAG의 한계를 극복하기 위해 추론 중에 맥락적으로 풍부한 정보를 주입합니다. retrieval에 자연어 텍스트의 정교한 교환을 활용하여 컨텍스트를 풍부하게 함으로써 생성 결과를 개선합니다.
ITERRETGEN은 반복적으로 정보를 검색함으로써 "검색 강화 생성"과 "생성 강화 검색"을 번갈아 가며 순환하는 프로세스에서 검색과 생성을 병합합니다.
Augmentation Source

RAG 모델는 데이터 소스 선택에 따라 크게 영향을 받습니다. 다양한 수준의 지식과 차원에는 각기 다른 처리 기술이 필요합니다. 이러한 데이터는 비정형 데이터, 정형 데이터, LLM에서 생성된 콘텐츠로 분류됩니다.
Evaluation Aspects
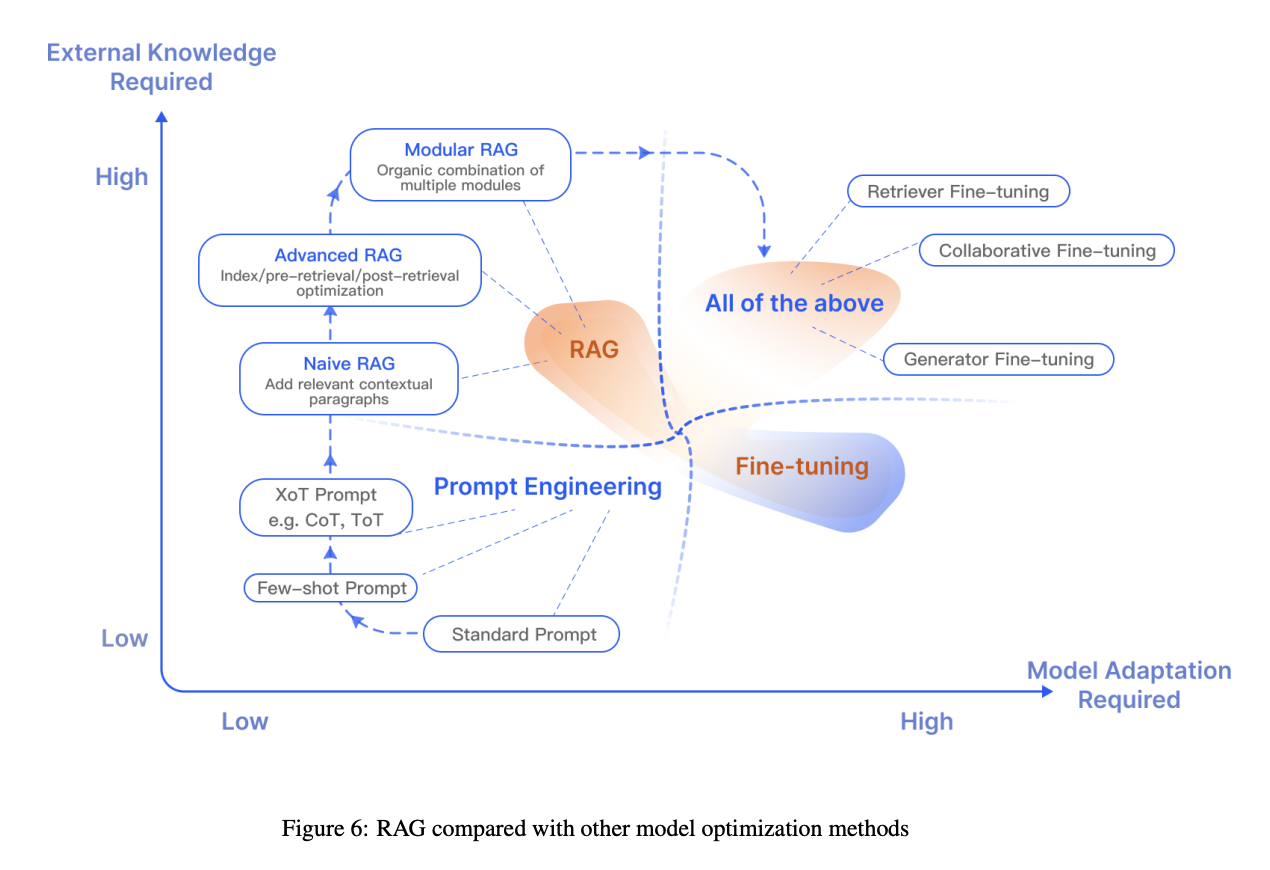
LLM 최적화는 LLM의 보급률이 증가함에 따라 상당한 주목을 받고 있습니다. 프롬프트 엔지니어링, FT(미세 조정), RAG와 같은 기술은 figure 6에 표현된 것처럼 각각 뚜렷한 특징을 가지고 있습니다.
프롬프트 엔지니어링은 모델의 고유한 기능을 활용하지만, LLM을 최적화하려면 종종 RAG와 FT 방법을 모두 적용해야 하는 경우가 많습니다. RAG와 FT 중 어떤 방법을 선택할지는 시나리오의 특정 요구 사항과 각 접근 방식의 고유한 속성을 기반으로 해야 합니다.
RAG vs Fine-tuning
RAG는 특정 쿼리에 적합한 맞춤형 정보 검색을 위한 교과서를 모델에 제공하는 것과 같습니다. 반면 FT는 시간이 지남에 따라 지식을 내면화하는 학생과 같아서 특정 구조, 스타일 또는 형식을 복제하는 데 더 적합합니다. FT는 기본 모델 지식을 강화하고, 출력을 조정하고, 복잡한 지침을 가르침으로써 모델 성능과 효율성을 향상시킬 수 있습니다. 하지만 새로운 지식을 통합하거나 새로운 사용 사례를 빠르게 반복하는 데는 적합하지 않습니다.
| RAG | Fine-tuning | |
| Knowledge updates | 재교육할 필요 없이 정보를 최신 상태로 유지할 수 있어 동적인 데이터 환경에 적합합니다. | 정적 데이터 저장, 재교육 필요 지식 및 데이터 업데이트가 필요합니다. |
| 외부 지식 | 외부 리소스 활용에 좋습니다. 특히 문서or 정형/비정형 데이터베이스에 액세스하는데 적합합니다. | pretrning을 통해 외부에서 습득한 지식을 대규모 언어 모델에 맞게 조정하는 데 활용할 수 있습니다. |
| 데이터 처리 | 최소한의 데이터 처리만 합니다. | 고품질 데이터 세트 생성에 따라 다르며, 데이터 세트가 제한적일 경우 성능이 크게 향상되지 않을 수 있습니다. |
| Model Customization | 정보 검색과 외부 지식 통합에 중점을 두지만 모델 행동이나 output 스타일을 사용자 지정할 수 있습니다. | 특정 어조나 용어에 따라 글쓰기 스타일 또는 특정 도메인 지식을 조정할 수 있습니다. |
| Computational Resources | 데이터베이스와 관련된 검색 전략 및 기술을 지원하기 위한 컴퓨팅 리소스에 의존하며 외부 데이터 소스 통합 및 업데이트의 유지 관리가 필요합니다. | 고품질 훈련 데이터 세트의 준비 및 미세 조정의 목표에 따라 그에 맞는 컴퓨팅 리소스 제공이 필요합니다. |
| Reducing Hallucinations | 각 답변은 검색된 증거를 기반으로 진행되어 환각이 덜 발생합니다. | 특정 도메인 데이터를 기반으로 모델을 훈련하여 모델을 훈련하여 환각을 줄이는 데 도움되지만 익숙하지 않은 문제에 직면했을 때 환각이 나타날 수 있습니다. |
| 윤리 및 개인정보 보호 문제 | 사용하는 외부 데이터베이스에서 텍스트 저장 및 검색 할 때 발생합니다. | 정의된 사전 세트에 따라 발생할수 있습니다. |
Future Prospects
RAG 기술의 상당한 진전에도 불구하고, 몇 가지 연구가 필요합니다:
컨텍스트 길이: RAG의 효율성은 대형 언어 모델(LLM)의 컨텍스트 크기에 의해 제한됩니다. 밸런싱 너무 짧아 정보가 불충분할 위험이 있는 창과 너무 길어 정보가 희석될 위험이 있는 창 사이의 균형을 맞추는 것이 중요합니다.
product ready RAG : 검색 효율성을 높이고, 대규모 지식 베이스에서 문서 검색 효율성 향상, 대규모 지식 베이스에서의 리콜 개선, 데이터 보안 보장하는 등 데이터 보안을 보장해야 합니다.

Conclusion
언어 모델의 파라미터화된 지식과 외부 지식 기반의 광범위한 비정형 파라미터화 데이터를 통합하여 LLM의 기능을 향상시키는 데 있어 RAG이 중요했습니다
advenced RAG 패러다임은 naive RAG 방식을 뛰어넘어 쿼리 재작성, 청크 재순위 지정, 신속한 요약 등 정교한 아키텍처 요소를 통합하여 뛰어난 성능을 발휘했습니다.
RAG 기술의 발전에도 불구하고 견고성과 확장된 컨텍스트를 관리하는 능력을 개선해야 합니다.
'ML > LLM' 카테고리의 다른 글
| [논문리뷰] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (0) | 2024.03.26 |
|---|---|
| [dacon] 도배 하자 질의 응답 처리 : 한솔데코 시즌2 AI 경진대회 (4) | 2024.02.28 |
| [논문리뷰] Precise Zero-Shot Dense Retrieval without Relevance Labels (HyDE) (0) | 2024.02.14 |
| [논문리뷰] Lost in the Middle: Models Use Long Contexts (2) | 2024.02.13 |
| 3. 벡터 임베딩를 활용한 성과 지표 (다중 분류 문제) (1) | 2024.01.29 |



