스마일게이트에서 제공한 데이터를 기반으로 욕설분류 bert 모델을 만들었다. 기본 소스는 다음과 같다.
[위의 설명은 이전 포스팅인 https://uiandwe.tistory.com/1395 에 있다]
1.Triton Inference Server
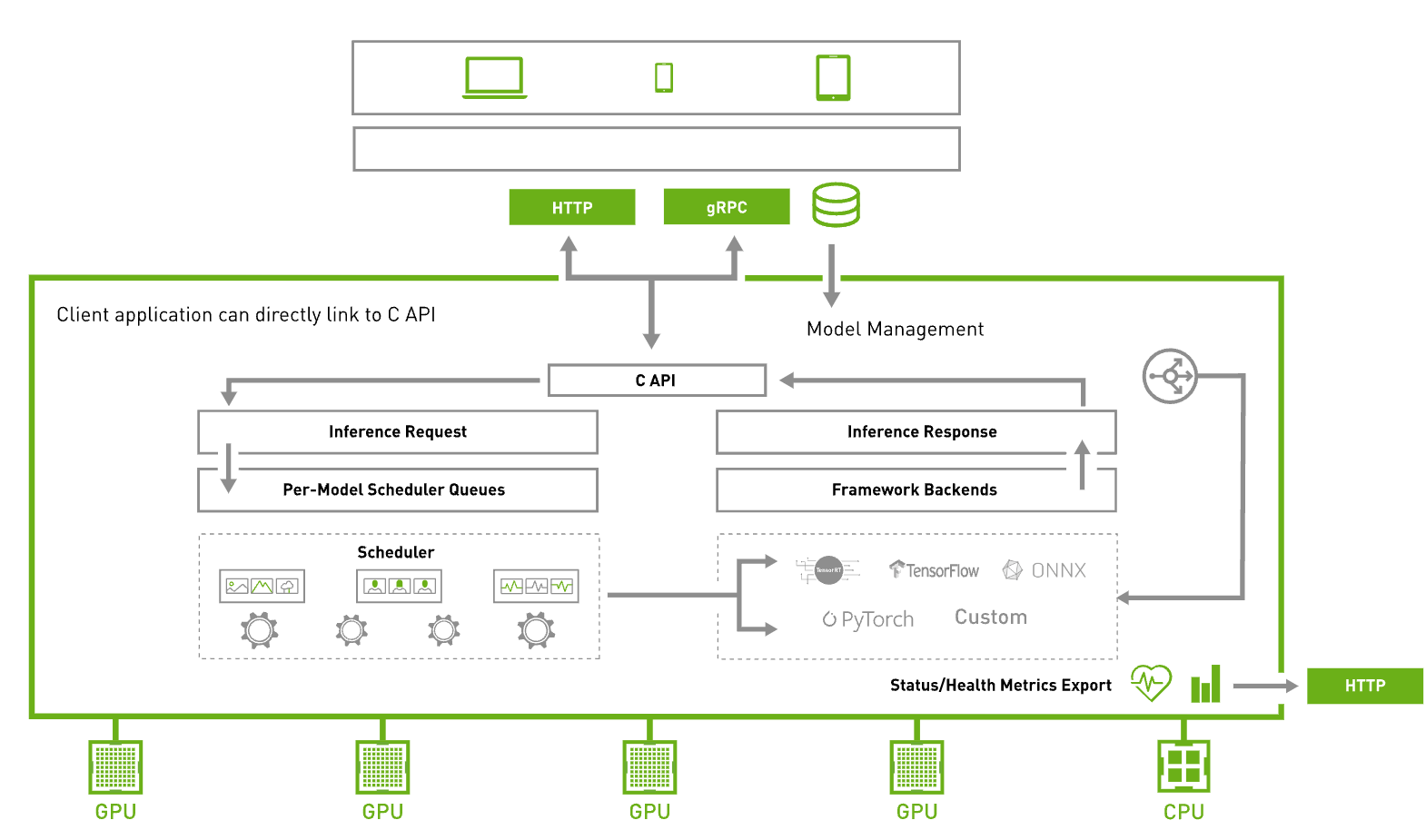
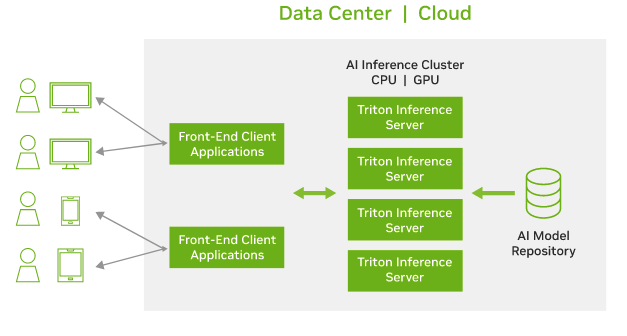
Triton Inference Server는 GPU 장비를 효과적으로 사용하면서 리소스 비용을 절약하기 위해 일종의 GPU전용 서버를 하나 만들어서 다양한 모델들을 서빙할수 있도록 돕는 추론 서버 역활을 맡은 고성능 추론에 최적화된 오픈소스 소프트웨어입니다. 다양한 모델 포맷을 지원하며, 특히 TensorRT를 사용한 고속 추론 기능을 제공합니다. C++ 기반으로 작성되어 Python보다 빠른 속도로 추론을 수행되며, 설정 파일로 모델를 정의하면 Triton Inference Server에서 쉽게 서빙할수 있습니다.
Triton을 통해 TensorRT, TensorFlow, PyTorch, ONNX, OpenVINO, Python, RAPIDS FIL 등을 포함한 다양한 딥 러닝 및 머신 러닝 프레임워크에서 AI 모델을 배포할 수 있습니다. Triton 추론 서버는 실시간, 일괄 처리, 앙상블, 오디오/비디오 스트리밍 등 다양한 쿼리 유형에 최적화된 성능을 제공합니다.
기능 및 통합
Docker 컨테이너 형태로 제공되는 Triton은 Kubernetes와 통합되어 오케스트레이션, 메트릭 수집, 오토스케일링을 지원합니다. 또한 Kubeflow 및 KServe와 통합되어 전체 AI 워크플로우를 지원하고, Prometheus 메트릭을 내보내어 GPU 활용도, 지연 시간, 메모리 사용량, 추론 처리량 등을 모니터링할 수 있습니다. 표준 HTTP/gRPC 인터페이스를 통해 로드 밸런서 같은 다른 애플리케이션과 쉽게 연결할 수 있으며, 서버를 확장하여 다양한 모델에서 증가하는 추론 부하를 효율적으로 처리할 수 있습니다.
모델 제어 및 이기종 클러스터 지원
Triton은 모델 제어 API를 통해 수십 개에서 수백 개의 모델을 제공할 수 있습니다. GPU 또는 CPU 메모리에 맞게 모델을 로드하거나 언로드할 수 있으며, 이기종 클러스터에서 GPU와 CPU를 모두 활용할 수 있습니다. 이를 통해 플랫폼 전반에서 추론을 표준화하고, 동적 확장을 통해 최대 부하를 처리할 수 있습니다.
Triton Inference Server를 사용하면 복잡한 추론 코드를 작성하지 않고도 고성능 추론을 쉽게 구현할 수 있으며, 다양한 통합 기능을 통해 AI 워크플로우를 효율적으로 관리할 수 있습니다.
2. triton 실습
앞서 말씀드렸듯이 욕설분류 bert 모델을 만들고, 해당 모델을 triton에 실행하는 실습입니다.
해당 bert모델을 생성하는 소스는 아래에 첨부하였습니다.
아래는 해당 model을 파일로 저장하기 위한 코드 입니다. 생성된 model.pt 파일을 triton서버에서 인식하여, 추론한다고 보시면 됩니다.
from transformers import BertForSequenceClassification, AutoTokenizer
import torch
# 모델과 토크나이저 로드
model_name = 'beomi/kcbert-base'
tokenizer = AutoTokenizer.from_pretrained(model_name)
texts = ["욕설 테스트"]
encoding = tokenizer(texts, padding=True, truncation=True, return_tensors="pt")
# input_ids와 attention_mask 추출
input_ids = encoding['input_ids']
attention_mask = encoding['attention_mask']
# 모델 래핑
class WrappedModel(torch.nn.Module):
def __init__(self, model):
super(WrappedModel, self).__init__()
self.model = model
def forward(self, input_ids, attention_mask):
outputs = self.model(input_ids=input_ids, attention_mask=attention_mask)
# 필요한 출력만 선택
return outputs.logits
# 래핑된 모델 생성
wrapped_model = WrappedModel(model2)
input_ids = encoded_input["input_ids"].to(device)
attention_mask = encoded_input["attention_mask"].to(device)
cpu_traced = torch.jit.trace(wrapped_model, (input_ids, attention_mask))
torch.jit.save(cpu_traced, "model.pt")
GPU서버에 model.pt를 저장할 리포지토리를 지정하고, model.pt 파일을 옮겨 줍니다. (디렉토리 경로는 다음과 같습니다.)
지정된 구조대로 리포지토리를 지정하면 Inference Server 구동 시 config.pbtxt 파일을 참조하여 경로를 참조해서 모델을 불러 옵니다.
model_repository
|
+-- kor_unsmile
|
+-- config.pbtxt
+-- 1
|
+-- model.pt
triotin 설정파일인 config.pbtxt 파일 내용을 작성합니다.
이 파일은 바라볼 model.pt의 폴더명(여기서는 kor_unsmile), 모델의 input 및 output 값의 데이터 타입과 차원을 정의하는 역할을 합니다. 참고로 모델의 data_type과 형태가 정확히 일치해야만 triton server가 실행됩니다. (에러시 메시지로 표기됩니다.)
name: "kor_unsmile"
platform: "pytorch_libtorch"
input [
{
name: "input_ids"
data_type: TYPE_INT64
dims: [1, 256]
},
{
name: "attention_mask"
data_type: TYPE_INT64
dims: [1, 256]
}
]
output {
name: "logits"
data_type: TYPE_FP32
dims: [1, 10]
}
GPU triton inference server start
docker run --rm --gpus all -p 8000:8000 -p 8001:8001 -p 8002:8002 \
-v model_repository:/models nvcr.io/nvidia/tritonserver:23.01-py3 \
tritonserver --model-repository=/models
여기서 8000 포트는 http, 8001 포트는 grpc, 8002 포트는 metric (측정) 을 위해 사용됩니다.
모델이 정상적으로 로드되면 container log 에서 확인할 수 있습니다.

마지막으로 실제 인퍼런스 코드 입니다.
코드를 보시면 triton이 실행된 docker를 호출 (localhost:8000) 하여 해당 모델의 결과값을 가져온다고 보시면 됩니다.
import torch
import time
from scipy.special import softmax
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import tritonclient.http as httpclient
from tritonclient.utils import triton_to_np_dtype
import numpy as np
model_name = 'beomi/kcbert-base'
tokenizer = AutoTokenizer.from_pretrained(model_name)
input_name = ['input_ids', 'attention_mask']
output_name = 'logits'
def run_inference(sentence):
triton_client = httpclient.InferenceServerClient(url="localhost:8000")
data_type = np.int64
desired_dims = (1, 256)
inputs = tokenizer(sentence, max_length=256, padding='max_length', return_tensors='pt')
input_ids = inputs['input_ids'].numpy()
input_ids = np.reshape(input_ids, desired_dims)
input_ids = input_ids.astype(data_type)
mask = inputs['attention_mask'].numpy()
mask = np.reshape(mask, desired_dims)
mask = mask.astype(data_type)
parms1 = httpclient.InferInput(input_name[0], desired_dims, 'INT64')
parms1.set_data_from_numpy(input_ids, binary_data=False)
parms2 = httpclient.InferInput(input_name[1], desired_dims, 'INT64')
parms2.set_data_from_numpy(mask, binary_data=False)
output = httpclient.InferRequestedOutput(output_name)
response = triton_client.infer(model_name="kor_unsmile", inputs=[parms1, parms2], outputs=[output])
logits = response.as_numpy('logits')
scores = softmax(logits, axis=1)
max_index = np.argmax(scores)
return max_index, scores
sentence = "빨리 죽으세요"
result, scores = run_inference(sentence)
unsmile_labels = ["여성/가족","남성","성소수자","인종/국적","연령","지역","종교","기타 혐오","악플/욕설","clean"]
print(result, unsmile_labels[result], scores)
해당 코드의 결과값입니다. 정상적으로 출력된것을 확인할수 있습니다.

끗
참고사항
https://hyojupark.github.io/triton/deploying-transformers-model-to-triton/
'ML > MLops' 카테고리의 다른 글
| [개인프로젝트] 나만의 추천시스템 만들기 (2) (1) | 2024.06.20 |
|---|---|
| [개인프로젝트] 나만의 추천시스템 만들기 (1) (0) | 2024.06.17 |
| ml를 쉽게 쓰기 위한 프론트 작업 (0) | 2024.05.03 |
| [system design] 이벤트 추천 시스템 (1) | 2024.03.22 |
| [system design] 이미지 검색 서비스 (3) | 2024.03.19 |


