요즘 한창 원티드를 기웃 거리고 있는 중, 추천 포지션과 기업들이 이상하게 나오는게 눈에 띄었다.
이력서에 넣지도 않은 프론트엔드 관련 jd의 합격 예측이 90%가 넘어가는거.


대체 왜? 라는 의문과 함께 한번 나만의 추천을 만들어볼까? 하는 마음에 시작하게 되었다.
1. 추천시스템?
서비스에는 다양한 종류의 콘텐츠 및 상품을 추천하는 서비스들이 있습니다. 기본적으로는 아이템기반과 유저 기반을 나눌수 있습니다.
유저기반 : 나와 비슷한 사람이 본 컨텐츠를 추천
아이템 : 내가 본 아이템과 비슷한 아이템 추천
이중에서 나는 다른 사람의 데이터는 알수 없으므로, 아이템 기반으로 가닥을 잡았습니다. 구축하려는 것은 Multi-stage recommendation system을 통해 범용 시스템을 개발해보려 합니다.
다양한 타입의 콘텐츠들을 하나의 피드로 구성하여 데이터화합니다. 예를 들어 [업무, 사용스킬, 인원수, 문화 등등] 이런 다양한 콘텐츠를 실시간으로 추천한 후 하나의 개인화 랭킹으로보여주는 겁니다.
(향후에는 사용자가 이미지도 해볼 계획이지만..이건 잘될지 모르겠.. 예를 들어 사무실 풍경이나, 이상한 사진을 올린 회사는 제외한다 이런식으로..)
2. What is a Multi-Stage Recommender System?
"Deep Neural Networks for YouTube Recommendations"는 2016년 ACM Conference on Recommender Systems에서 발표된 논문으로, YouTube의 추천 시스템에 사용되는 딥러닝 모델에 대해 설명합니다. 이 논문은 대규모 비디오 추천 시스템의 설계와 구현에 관한 내용을 다룹니다.
첫 번째 Stage: Candidate Generation 알고리즘을 활용하여 수백만 개에 달하는 문서들 중 실제로 유저에게 추천할 만한 몇 백 개 정도의 후보군을 추출하는 작업을 합니다.
두 번째 Stage: Ranking 에 앞서 추출된 후보군들을 유저가 좋아할 만한 순서로 랭킹을 적용하는 작업을 합니다.
일반적으로 검색, 추천 등의 ML Problem에선 이진 분류일 경우 Precision(정밀도), Recall(재현율) 이 두 가지 지표를, 연속형 데이터일 경우에는 평균 제곱 오차(Mean Squared Error, MSE)와 같은 회귀 평가지표를 사용합니다.
3. 간단한 추천 구현 (워밍업)
전체적인 로직은 다음과 같습니다.
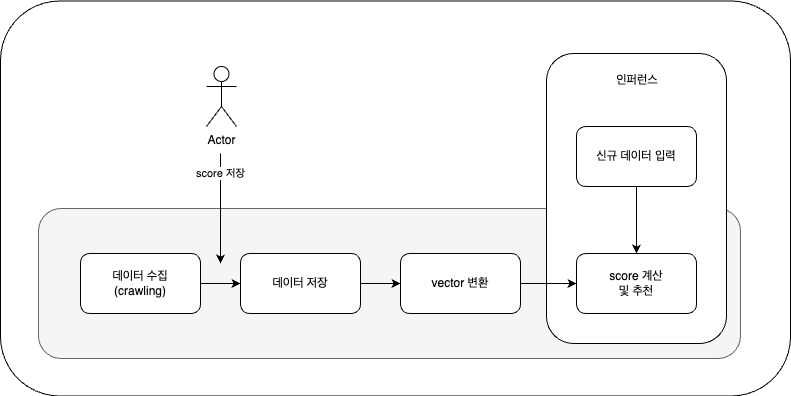
1. 데이터 수집 : wanted에서 데이터를 수집해 옵니다. (크롤링)
2. 수집된 내용을 사용자 평가 (기본 데이터로 쓰임)
3. 데이터 저장 : 이미지 수집된 내용은 제외 시켜야 하므로 따로 저장합니다.
4. vertor로 변환 : 수집된 내용중 특정 칼럼을 기반으로 벡터화를 합니다.
5. score 계산 : 벡터를 기준으로 score를 예측합니다.
1. 데이터 수집
원티드 로직을 잠깐 살펴 보면 리액트와 서버로 나뉘어 , API 통신을 하고 있는 구조였습니다. API만 알수 있다면 간단하게 데이터를 가져올수 있었습니다.
리스트 API와 jd의 상세 데이터 API 두가지를 사용하여 데이터를 수집합니다.
import requests
import json
import pandas as pd
def get_jd_list(offset):
url = f"https://www.wanted.co.kr/api/chaos/navigation/v1/results?&job_group_id=518&country=kr&job_sort=job.recommend_order&years=-1&locations=all&limit=20&offset={offset}"
print(url)
response = requests.get(url)
if response.status_code == 200:
return response.json()
raise Exception(str(response))
def get_jd_detail(response_data):
l = []
for d in response_data['data']:
job_id = d['id']
detail_url = f"https://www.wanted.co.kr/api/chaos/jobs/v2/{job_id}/details"
# print(detail_url)
detail_res = requests.get(detail_url)
detail_data = detail_res.json()
jd = detail_data['job']
temp = {
'jd_id': jd['detail']['id'],
'company_name': jd['company']['name'],
'status': jd['status'],
'due_time': jd['due_time'],
'position': jd['detail']['position'],
'intro': jd['detail']['intro'],
'main_tasks': jd['detail']['main_tasks'],
'requirements': jd['detail']['requirements'],
'preferred_points': jd['detail']['preferred_points'],
'benefits': jd['detail']['benefits'],
'rate': jd['company']['application_response_stats']['rate'],
'target_count': jd['company']['application_response_stats']['target_count'],
'address_district': jd['address']['district'],
'category_tag': ",".join([tag['text'] for tag in jd['category_tag']['child_tags']]),
'skill_tag': ",".join([tag['text'] for tag in jd['skill_tags']]),
'url': detail_url
}
l.append(temp)
return l
df = pd.DataFrame(
columns=['jd_id', 'company_name', 'status', 'due_time', 'position', 'intro', 'main_tasks', 'requirements',
'preferred_points', 'benefits', 'rate', 'target_count', 'address_district', 'category_tag', 'skill_tag',
'url'])
for i in range(5):
response_data = get_jd_list(i * 20)
l = get_jd_detail(response_data)
df2 = pd.DataFrame(l)
df = pd.merge(df, df2, how='outer')
df.to_csv("data.csv")
샘플 데이터는 100개의 데이터로 직접 score를 기입했습니다. 해당 데이터는 추천을 하기 위한 기초 데이터로 쓰입니다.
2. 데이터 전처리
사용자가 측정한 score 데이터가 포함된 CSV 파일을 읽고 결측값을 처리합니다. 데이터 전처리를 위해 텍스트 데이터를 정리하고, 불용어를 제거하며, 소문자로 변환하고 특수문자를 제거합니다. 이를 통해 데이터를 일관된 형식으로 변환하여 분석의 정확성을 높입니다.
# CSV 파일 읽기
file_path = 'data.csv'
data = pd.read_csv(file_path)
# 결측값 처리
data = data.fillna('')
KoNLPy의 Okt 형태소 분석기를 사용하여 한글 텍스트를 형태소 단위로 분리하고, 이를 통해 각 칼럼의 텍스트 데이터를 전처리합니다.
from konlpy.tag import Okt
# 텍스트 데이터 전처리 함수
def preprocess_text(text):
# 소문자 변환
text = text.lower()
okt = Okt()
tokens = okt.morphs(text) # 형태소 분석을 통해 토큰화
text = ' '.join(tokens)
# 특수문자 제거
text = ''.join(e for e in text if e.isalnum() or e.isspace())
return text
# 주요 칼럼에 대해 전처리 수행
data['position'] = data['position'].apply(preprocess_text)
data['main_tasks'] = data['main_tasks'].apply(preprocess_text)
data['requirements'] = data['requirements'].apply(preprocess_text)
data['category_tag'] = data['category_tag'].apply(preprocess_text)
data['skill_tag'] = data['skill_tag'].apply(preprocess_text)
3. TF-IDF 벡터화
각 칼럼의 텍스트 데이터를 TF-IDF(Vectorizer)를 통해 벡터화하여 수치화된 표현으로 변환합니다.
from sklearn.feature_extraction.text import TfidfVectorizer
# TF-IDF 벡터화
tfidf_vectorizer = TfidfVectorizer()
# 각 칼럼에 대해 TF-IDF 수행
tfidf_position = tfidf_vectorizer.fit_transform(data['position'])
tfidf_main_tasks = tfidf_vectorizer.fit_transform(data['main_tasks'])
tfidf_requirements = tfidf_vectorizer.fit_transform(data['requirements'])
tfidf_category_tag = tfidf_vectorizer.fit_transform(data['category_tag'])
tfidf_skill_tag = tfidf_vectorizer.fit_transform(data['skill_tag'])
# TF-IDF 벡터 결합
tfidf_combined = np.hstack((tfidf_position.toarray(), tfidf_main_tasks.toarray(), tfidf_requirements.toarray(),
tfidf_category_tag.toarray(), tfidf_skill_tag.toarray()))
4. 유사도 계산
각 항목 간의 유사도를 계산하기 위해 코사인 유사도를 사용합니다.
from sklearn.metrics.pairwise import cosine_similarity
# 코사인 유사도 계산
cosine_similarities = cosine_similarity(tfidf_combined)
5. 추천 시스템 구현
특정 항목(포지션, 주요업무, 주요스킬, 태그[인원수, 투자 등등]) 항목을 추천하는 함수를 구현합니다. 입력 데이터와 기존 데이터 간의 유사도를 계산하고, 가장 유사한 항목들의 score 평균을 계산하여 추천 점수를 제공합니다.
def calculate_score(new_data):
# 결측값 처리 및 텍스트 전처리
for column in ['position', 'main_tasks', 'requirements', 'category_tag', 'skill_tag']:
new_data[column] = preprocess_text(new_data[column])
# 기존 데이터와 입력 데이터를 합침
combined_data = pd.concat([data, pd.DataFrame([new_data])], ignore_index=True)
# TF-IDF 벡터화
tfidf_vectorizer = TfidfVectorizer()
# 각 칼럼에 대해 TF-IDF 수행
tfidf_position = tfidf_vectorizer.fit_transform(combined_data['position'])
tfidf_main_tasks = tfidf_vectorizer.fit_transform(combined_data['main_tasks'])
tfidf_requirements = tfidf_vectorizer.fit_transform(combined_data['requirements'])
tfidf_category_tag = tfidf_vectorizer.fit_transform(combined_data['category_tag'])
tfidf_skill_tag = tfidf_vectorizer.fit_transform(combined_data['skill_tag'])
# TF-IDF 벡터 결합
tfidf_combined = np.hstack(
(tfidf_position.toarray(), tfidf_main_tasks.toarray(), tfidf_requirements.toarray(),
tfidf_category_tag.toarray(), tfidf_skill_tag.toarray()))
# 코사인 유사도 계산
cosine_similarities = cosine_similarity(tfidf_combined)
# 입력 데이터 (마지막 행)와 기존 데이터 간의 유사도 추출
new_data_similarities = cosine_similarities[-1][:-1]
# 가장 유사한 항목들의 score 평균 계산
top_similar_indices = new_data_similarities.argsort()[-5:][::-1] # 상위 5개의 유사한 항목 선택
top_scores = data.iloc[top_similar_indices]['score']
# score 평균 계산
calculated_score = top_scores.mean()
return calculated_score
# 새로운 입력 데이터 예시
new_data = {
'Id': 123456,
'company_id': 99999,
'name': 'New Company',
'due_time': '2024-12-31',
'position': 'Frontend (React / Angular) 개발자(5년 이상)',
'intro': """[업무 방식]
• code review 를 통해 더 좋은 코드를 작성하고 지식을 나누며 성장하고자 합니다.
• tech spec 를 작성하여 제품의 개발 방향을 함께 고민하고 최선의 방법을 찾고자 노력합니다.
• 회고 문화를 통해 지나온 발자취를 되돌아 보고 개선점을 찾고자 노력합니다.""",
'main_tasks': """• 사용자와 연동되는 모든 내/외부 서비스
• React 혹은 React Native를 활용하여 앱/웹 서비스를 개발*
• 프론트엔드 서비스 전반에 걸친 공용 컴포넌트 개발
• 생산성 향상을 위해 개발 환경 개선""",
'requirements': """• React 혹은 React Native 개발 및 운영 경험이 최소 2년 이상 개발 경험이 있으신 분
• HTML, CSS, JavaScript에 대한 깊은 이해가 있으신 분
• 프로젝트의 한 사이클(서비스 설계부터 구축, 출시까지)을 경험해보신 분*
• JavasScript(ES6 이상), CSS, HTML에 대한 이해가 깊은 분
• Javascript, React, Webpack, Babel, redux, recoil, react-query""",
'preferred_points': """• Typescript 경험
• 모듈 번들러를 사용하시는 분
• 서버 사이드 렌더링(SSR) 개발 경험
• 어드민, 관리자 페이지, 통계, 그래프 개발하고 운영 경험*""",
'rate': 80.0,
'target_count': 100,
'address': 'Seoul',
'Memo': 'Flexible working hours',
'category_tag': '프론트엔드 개발자',
'skill_tag': 'React,CSS,HTML,JavaScript,TypeScript,SSRS,React Native'
}
# 입력 데이터를 DataFrame으로 변환
new_data_df = pd.DataFrame([new_data])
# score 계산
calculated_score = calculate_score(new_data_df.iloc[0])
print(calculated_score)
위의 데이터에 대한 score 예측값은 4.2가 나왔습니다. 프론트 관련 jd이기 때문에 얼추 맞은 값이 나왔습니다. (프론트의 경우 저는 보통 score값은 2이하를 줬습니다.)
# 새로운 입력 데이터 예시
new_data = {
'Id': 123456,
'company_id': 99999,
'name': 'New Company',
'due_time': '2024-12-31',
'position': '코박(Cobak) 백엔드 개발자[3년 이상] (Python, Django)',
'intro': """[코박팀의 백앤드 개발자는 이런 다양한 서비스에 맞게 안정된 서비스를 사용자에게 제공하는 일을 하고 있습니다.
우리 코박팀의 모든 의사소통은 Slack을 통해 이뤄지고 있으며, 사용하는 기술은 Python, Django, AWS, Redis, MySQL, NGINX, Elasticsearch, Blockchain 등이 있습니다.
최근 블록체인 및 암호화폐에 대해 전 세계적 폭발적 관심으로 코박의 사용자 수는 계속해서 증가하고 있으며 차별화된 서비스 제공 및 글로벌 시장 진출을 위해 더욱 고도화된 플랫폼을 준비중에 있습니다.
당사의 비젼있는 발걸음에 함께할 개발자를 모십니다""",
'requirements': """• API 개발 및 유지보수
• 서비스 및 인프라의 안정성, 확장성, 효율성 개선
• 신규 서비스 구축 참여 및 유지보수""",
'main_tasks': """• 백엔드 개발 경력 3년 이상이신 분
• Python / Django 프레임 워크 사용 경력이 있으신 분
• 백엔드 구축을 진행해본 경험이 있으신 분
• AWS 사용 경험 혹은 그에 준하는 클라우드 인프라 운영 경험이 있으신 분""",
'preferred_points': """• Git에 대한 이해 및 소스 코드 관리 경험이 있으신 분
• DB성능 최적화(인텍싱, 정규화, 퀴리 등) 및 ORM 최적화 경험이 있으신 분
• 대량 트래픽 대비 언어, 인프라, DB 최적화 경험이 있으신 분
• 블록체인 지갑 개발 경험이 있으신 분
• 가상자산 및 블록체인에 대한 이해도가 높으신 분""",
'rate': 80.0,
'target_count': 100,
'address': 'Seoul',
'Memo': 'Flexible working hours',
'category_tag': '서버 개발자,파이썬 개발자,블록체인 플랫폼 엔지니어',
'skill_tag': 'Android,Django,React,VueJS,C#,Python,MVVM,C,C++,jQuery,API,HTML5,CSS3,SASS,MFC,Flutter'
}
# 입력 데이터를 DataFrame으로 변환
new_data_df = pd.DataFrame([new_data])
# score 계산
calculated_score = calculate_score(new_data_df.iloc[0])
print(calculated_score)위의 데이터에 대한 score 예측값은 7.24가 나왔습니다. 벡엔드 이면서 python이 들어가면 높은 점수를 주겠지만, 블록체인 이라면 6이하를 줬습니다.
6. 평가지표
정밀도와 재현율은 이진 분류 문제에서 사용되는 지표이므로, 실제 관심도 값이 0에서 10 사이의 연속형 데이터일 경우에는 적합하지 않습니다. 대신, 평균 제곱 오차(Mean Squared Error, MSE)와 같은 회귀 평가지표를 사용하는 것이 적합합니다.
from sklearn.metrics import mean_squared_error, r2_score
# 추천 시스템 구현
def recommend_items(item_id, num_recommendations=5):
# 특정 항목의 유사도 추출
sim_scores = list(enumerate(cosine_similarities[item_id]))
# 유사도 점수를 기준으로 정렬
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
# 가장 유사한 항목 선택
sim_scores = sim_scores[1:num_recommendations + 1]
# 추천 항목의 인덱스와 유사도 점수 반환
item_indices = [i[0] for i in sim_scores]
return item_indices
# 평균 제곱 오차 계산 함수
def calculate_mse(actual_values, predicted_values):
mse = mean_squared_error(actual_values, predicted_values)
return mse
# R² 계산 함수
def calculate_r2(actual_values, predicted_values):
r2 = r2_score(actual_values, predicted_values)
return r2
# 모든 아이템에 대해 MSE 및 R² 계산
def evaluate_model(data, num_recommendations=5):
actual_interests = []
predicted_interests = []
for item_id in range(len(data)):
recommended_indices = recommend_items(item_id, num_recommendations)
actual_values = data['score'].iloc[recommended_indices].values
predicted_value = data['score'].iloc[item_id] # 각 추천 항목에 대해 동일한 예측 값 사용
actual_interests.extend(actual_values)
predicted_interests.extend([predicted_value] * len(recommended_indices))
mse = calculate_mse(actual_interests, predicted_interests)
r2 = calculate_r2(actual_interests, predicted_interests)
return mse, r2
# 모델 평가
mse, r2 = evaluate_model(data, 5)
print(f'Mean Squared Error: {mse}')
print(f'R²: {r2}')
Mean Squared Error: 4.943719999999999
R²: -0.9181857975563659
MSE 값: 4.943719999999999
MSE는 예측 값과 실제 값 사이의 평균 제곱 오차를 나타냅니다. 값이 작을수록 모델의 예측이 실제 값에 가깝다는 의미입니다. MSE 값이 4.9437로, 이는 모델이 예측한 점수와 실제 점수 사이의 평균적인 차이가 약 4.94의 제곱된 차이임을 나타냅니다.
R²(결정 계수) 값: -0.9181857975563659
R² 값은 0에서 1 사이의 값일 때, 모델이 데이터를 잘 설명할수록 1에 가까운 값을 가집니다.
R² 값이 음수일 경우, 이는 모델이 실제 데이터의 분산을 설명하지 못하고 있음을 나타냅니다. 즉, 모델이 오히려 평균값으로 예측하는 것보다 더 나쁜 성능을 보인다는 것을 의미합니다.
결과
간단하게 데이터를 크롤링하고, 나만의 데이터를 활용하여 추천 시스템을 만들어보았습니다. 하지만 결과값이 상당히 부정적으로 나왔습니다.
개선의 여지는 많습니다.
1. 사용한 함수는 한글에는 정확하지 않을 수 있습니다. 한글 토큰을 사용하는 bert 같은 모델을 사용해서 정확도를 높힐수 있습니다.
2. 데이터 전처리를 통해 더 정확한 특징을 추출합니다.
3. 데이터의 양과 품질을 높입니다.
다음 글에서는 한글 벡터를 표현할수 있는 LLM이나 bert 모델을 활용해 구현해 보도록 하겠습니다.
'ML > MLops' 카테고리의 다른 글
| airflow + dbt 를 활용한 데이터 파이프라인 (0) | 2025.02.15 |
|---|---|
| [개인프로젝트] 나만의 추천시스템 만들기 (2) (1) | 2024.06.20 |
| [MLOps] Triton을 활용한 모델 배포 (0) | 2024.06.14 |
| ml를 쉽게 쓰기 위한 프론트 작업 (0) | 2024.05.03 |
| [system design] 이벤트 추천 시스템 (1) | 2024.03.22 |


