이전 포스팅 : https://uiandwe.tistory.com/1483
1편에 이어 추천시스템 개선을 해보려 합니다.
이번 주요 사항은 sklearn의 기본 vector 함수를 사용하는게 아닌, bert모델을 사용하여 vector 임베딩을 하고, 해당 벡터 값을 통해 추천시스템을 만드는겁니다.
bert 모델을 사용한 간단한 추천 구현
전체적인 로직은 다음과 같습니다.
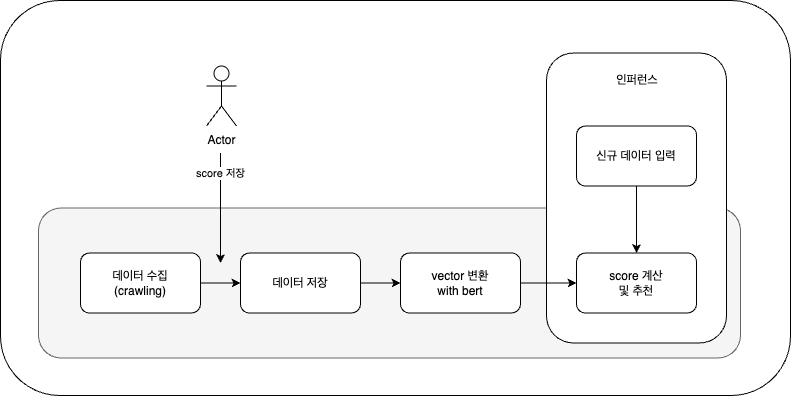
1편과 내용이 똑같아서 코드는 제외했습니다. 아래의 내용은 이번 글에서는 제외했습니다.
1. 데이터 수집 : wanted에서 데이터를 수집해 옵니다. (크롤링)
2. 수집된 내용을 사용자 평가 (기본 데이터로 쓰임)
3. 데이터 저장 : 이미지 수집된 내용은 제외 시켜야 하므로 따로 저장합니다.
아래의 내용이 해당 블로그에 추가되었습니다.
4. vertor로 변환 with bert : 수집된 내용중 특정 칼럼을 기반으로 벡터화를 합니다. bert 모델을 사용하여 vector embedding을 진행합니다.
5. score 계산 : 벡터를 기준으로 score를 예측합니다.
1. 데이터 전처리
데이터 전처리 부분도 1편과 거의 비슷하나 model을 로드하는것만 다르다고 보시면 됩니다.
사용된 모델은 "bert-base-multilingual-cased" 입니다.
import pandas as pd
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
from transformers import BertModel, BertTokenizer
import torch
from konlpy.tag import Okt
# BERT 모델 및 토크나이저 로드
model_name = "bert-base-multilingual-cased"
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name)
예외 처리를 추가 했을뿐 로직은 1편과 같습니다.
from konlpy.tag import Okt
# 텍스트 데이터 전처리 함수
def preprocess_text(text):
try:
if text is None:
return ''
# 소문자 변환
text = text.lower()
okt = Okt()
tokens = okt.morphs(text) # 형태소 분석을 통해 토큰화
text = ' '.join(tokens)
# 특수문자 제거
text = ''.join(e for e in text if e.isalnum() or e.isspace())
return text
except Exception as e:
print(e)
2. vector embedding
제가 임의로 score를 정한 데이터에 벡터화를 진행합니다. 사용칼럼은 'position', 'main_tasks', 'requirements', 'category_tag', 'skill_tag' 으로 bert 모델을 통해 vector embedding을 진행합니다. (get_bert_bedding 함수)
그리고 전체 데이터에서 신규로 입력한 데이터를 cosine_similarity() 함수를 통해 유사도를 계산하고 최종 5개의 값의 평균값을 리턴합니다.
# 데이터 전처리 함수
def preprocess_data(data):
try:
for column in ['position', 'main_tasks', 'requirements', 'category_tag', 'skill_tag']:
data[column] = data[column].apply(preprocess_text)
return data
except Exception as e:
print(e)
# BERT 임베딩 벡터 생성 함수
def get_bert_embedding(text):
inputs = tokenizer(text, return_tensors='pt', truncation=True, padding=True, max_length=512)
outputs = model(**inputs)
embeddings = outputs.last_hidden_state.mean(dim=1).squeeze().detach().numpy()
return embeddings
# 칼럼별 BERT 임베딩 벡터 생성 함수
def vectorize_columns(data, columns):
vectors = []
for column in columns:
column_vectors = data[column].apply(get_bert_embedding).tolist()
vectors.append(column_vectors)
combined_vector = np.hstack(vectors)
return combined_vector
# 새로운 입력 데이터를 벡터화하는 함수
def vectorize_new_data(new_data, columns):
vectors = []
for column in columns:
vector = get_bert_embedding(new_data[column])
vectors.append(vector)
combined_vector = np.hstack(vectors)
return combined_vector
# 새로운 입력 데이터를 바탕으로 score를 계산하는 함수
def calculate_score(new_data, origin_data, combined_vector):
new_data = preprocess_data(pd.DataFrame([new_data]))
# 새로운 데이터 벡터화
new_data_vector = vectorize_new_data(new_data.iloc[0], columns)
# 코사인 유사도 계산
cosine_similarities = cosine_similarity([new_data_vector], combined_vector)
# 가장 유사한 항목들의 score 평균 계산
top_similar_indices = cosine_similarities[0].argsort()[-5:][::-1] # 상위 5개의 유사한 항목 선택
top_scores = origin_data.iloc[top_similar_indices]['score']
# score 평균 계산
calculated_score = top_scores.mean()
return calculated_score
3. 기존 데이터를 vector embedding 계산을 합니다.
# 기존 데이터 로드
file_path = 'data.csv'
data = pd.read_csv(file_path)
# 데이터 전처리
data = preprocess_data(data)
# 기존 데이터 벡터화
columns = ['position', 'main_tasks', 'requirements', 'category_tag', 'skill_tag']
combined_vector = vectorize_columns(data, columns)
1편과 같은 데이터에 대해서 score 예측값을 뽑아봅니다.
해당 데이터는 프론트엔드 관련 jd였으며, 1편에서는 4.2가 나왔습니다.
# 새로운 입력 데이터 예시
new_data = {
'Id': 123456,
'company_id': 99999,
'name': 'New Company',
'due_time': '2024-12-31',
'position': 'Frontend (React / Angular) 개발자(5년 이상)',
'intro': """[업무 방식]
• code review 를 통해 더 좋은 코드를 작성하고 지식을 나누며 성장하고자 합니다.
• tech spec 를 작성하여 제품의 개발 방향을 함께 고민하고 최선의 방법을 찾고자 노력합니다.
• 회고 문화를 통해 지나온 발자취를 되돌아 보고 개선점을 찾고자 노력합니다.""",
'main_tasks': """• 사용자와 연동되는 모든 내/외부 서비스
• React 혹은 React Native를 활용하여 앱/웹 서비스를 개발*
• 프론트엔드 서비스 전반에 걸친 공용 컴포넌트 개발
• 생산성 향상을 위해 개발 환경 개선""",
'requirements': """• React 혹은 React Native 개발 및 운영 경험이 최소 2년 이상 개발 경험이 있으신 분
• HTML, CSS, JavaScript에 대한 깊은 이해가 있으신 분
• 프로젝트의 한 사이클(서비스 설계부터 구축, 출시까지)을 경험해보신 분*
• JavasScript(ES6 이상), CSS, HTML에 대한 이해가 깊은 분
• Javascript, React, Webpack, Babel, redux, recoil, react-query""",
'preferred_points': """• Typescript 경험
• 모듈 번들러를 사용하시는 분
• 서버 사이드 렌더링(SSR) 개발 경험
• 어드민, 관리자 페이지, 통계, 그래프 개발하고 운영 경험*""",
'rate': 80.0,
'target_count': 100,
'address': 'Seoul',
'Memo': 'Flexible working hours',
'category_tag': '프론트엔드 개발자',
'skill_tag': 'React,CSS,HTML,JavaScript,TypeScript,SSRS,React Native'
}
# score 계산
calculated_score = calculate_score(new_data, data, combined_vector)
print(calculated_score)
이번에도 4.2 가 나오는군요. 프론트엔드 관련 직무이기 때문에 2이하값이 나왔어야 합니다.
이번 데이터는 백엔드이지만 블록체인으로 5~6 이하 값이 나와야 합니다.
# 새로운 입력 데이터 예시
new_data = {
'Id': 123456,
'company_id': 99999,
'name': 'New Company',
'due_time': '2024-12-31',
'position': '코박(Cobak) 백엔드 개발자[3년 이상] (Python, Django)',
'intro': """[코박팀의 백앤드 개발자는 이런 다양한 서비스에 맞게 안정된 서비스를 사용자에게 제공하는 일을 하고 있습니다.
우리 코박팀의 모든 의사소통은 Slack을 통해 이뤄지고 있으며, 사용하는 기술은 Python, Django, AWS, Redis, MySQL, NGINX, Elasticsearch, Blockchain 등이 있습니다.
최근 블록체인 및 암호화폐에 대해 전 세계적 폭발적 관심으로 코박의 사용자 수는 계속해서 증가하고 있으며 차별화된 서비스 제공 및 글로벌 시장 진출을 위해 더욱 고도화된 플랫폼을 준비중에 있습니다.
당사의 비젼있는 발걸음에 함께할 개발자를 모십니다""",
'requirements': """• API 개발 및 유지보수
• 서비스 및 인프라의 안정성, 확장성, 효율성 개선
• 신규 서비스 구축 참여 및 유지보수""",
'main_tasks': """• 백엔드 개발 경력 3년 이상이신 분
• Python / Django 프레임 워크 사용 경력이 있으신 분
• 백엔드 구축을 진행해본 경험이 있으신 분
• AWS 사용 경험 혹은 그에 준하는 클라우드 인프라 운영 경험이 있으신 분""",
'preferred_points': """• Git에 대한 이해 및 소스 코드 관리 경험이 있으신 분
• DB성능 최적화(인텍싱, 정규화, 퀴리 등) 및 ORM 최적화 경험이 있으신 분
• 대량 트래픽 대비 언어, 인프라, DB 최적화 경험이 있으신 분
• 블록체인 지갑 개발 경험이 있으신 분
• 가상자산 및 블록체인에 대한 이해도가 높으신 분""",
'rate': 80.0,
'target_count': 100,
'address': 'Seoul',
'Memo': 'Flexible working hours',
'category_tag': '서버 개발자,파이썬 개발자,블록체인 플랫폼 엔지니어',
'skill_tag': 'Android,Django,React,VueJS,C#,Python,MVVM,C,C++,jQuery,API,HTML5,CSS3,SASS,MFC,Flutter'
}
# score 계산
calculated_score = calculate_score(new_data, data, combined_vector)
print(calculated_score)
예측값 4.9이 나왔습니다. 이번 데이터는 알맞게 나온것으로 판단됩니다.
이번엔 새로운 데이터로 백엔드 관련으로 아마도 6~8 점을 줬을거 같습니다.
# 새로운 입력 데이터 예시
new_data = {
'Id': 123456,
'company_id': 99999,
'name': 'New Company',
'due_time': '2024-12-31',
'position': '[100억↑투자] Backend(백엔드) Engineer',
'intro': """데이터라이즈는 세상에 “데이터를 활용하여 비즈니스 성장이 가능함”을 증명하고 이커머스 고객사의 매출 성장을 돕는, 데이터 기반의 Saas 솔루션을 만들고 있습니다.\n\n2019년 창업 후 1년도 되지 않아 네이버와 BASS Investment의 투자를 유치했고, 성장가능성을 높게 평가 받아 2022년엔 115억의 시리즈A를, 2024년에는 150억의 시리즈B 투자를 유치했습니다. 현재 젝시믹스, 아뜨랑스, 핫핑, 와이즐리, 캔마트, 마틸라, 슬림나인, 딘트, 미아마스빈 등의 300여개의 고객사가 사용 중입니다.\n\n2024년 글로벌 진출을 앞두고 있으며, 데이터의 진정한 가치를 통해 성공하는 비즈니스, ‘Data Makes Growth' 라는 비전을 가지고 고객이 성장을 구현할 수 있도록 함께 고민하고 성장할 멤버분을 모시고자 합니다.""",
'requirements': """• 4년 이상의 실무 경험이 있으신 분 \n• 1개 이상의 프로그래밍 언어에 능숙하신 분\n• 코드 리뷰 및 의견 공유에 있어 적극적인 분\n• 내가 만든 제품을 고객이 직접 사용하는 순간! 그때의 긴장감과 뿌듯함을 즐기시는 분""",
'main_tasks': """• Datarize 의 고객사가 이용하는 Datarize Console을 만듭니다.\n •• 메시지/온사이트 서비스 \n - CRM 메시지와 온사이트 배너를 통해 고객의 매출 증대에 기여합니다.\n - 분석 데이터를 바탕으로 일 수백만 건 이상의 개인화된 콘텐츠가 안정적이고 빠르게 고객에게 전달될 수 있는 파이프라인을 설계 및 구현합니다.\n - 다양한 데이터의 Integration, 퍼포먼스 향상, 빠르게 변화하는 고객에 니즈에 대응할 수 있는 유연한 설계를 고민하고 적용합니다.\n •• 결제 서비스\n - PG사의 다양한 인터페이스에 맞게 유연하게 구성하고 처리할 수 있는 시스템을 개발합니다.\n - 다양한 유즈케이스와 복잡한 정책을 간결하고 일반화시키는데 집중합니다.\n - 내부 정산 및 관리자용 시스템을 개발합니다.\n •• 진단 \n - 데이터 분석가와의 협업을 통해 고객이 자신의 쇼핑몰을 진단할 수 있도록 주요 지표를 가시적으로 제공합니다.\n - 데이터 가시화에 필요한 데이터의 형태와 효율적인 대용량 처리 방법에 대해 고민합니다.\n •• 인프라\n - 전사적으로 사용하는 인프라를 운영 관리합니다.\n - 대량의 데이터를 제공하기 위한 확장성 있는 기술들을 연구하고 적용합니다.\n\n\n[데이터라이즈의 Backend를 지탱하고 있는 기술들]\n\n• 애플리케이션 개발을 위해 Python, FastAPI 등을 사용합니다.\n• 모든 애플리케이션은 AWS 위에서 Docker, Kubernetes 로 운영합니다.\n• Git, GitHub Actions, ArgoCD 를 기반으로 GitOps 배포 자동화를 하고 있습니다.\n• 복잡함을 다루기 위해 도메인 주도 설계(Domain Driven Design)를 사용하여 개발합니다.\n• 변경에 유연한 설계를 위해 Clean Architecture 를 바탕으로 개발합니다.\n• 테스트 케이스의 중요성을 인지하면서 검증할 수 있으며 안정적인 서비스를 개발합니다.\n\n\"앞으로 도입할 더 좋은 기술은 같이 연구하고 만들어가요.""",
'rate': 80.0,
'target_count': 100,
'address': 'Seoul',
'Memo': 'Flexible working hours',
'category_tag': '서버 개발자,파이썬 개발자,소프트웨어 엔지니어',
'skill_tag': 'Python,Java,Docker,FastAPI,AWS'
}
# score 계산
calculated_score = calculate_score(new_data, data, combined_vector)
print(calculated_score)
이번 예측값은 5.62이 나왔습니다. 아마도 관련 데이터가 부족하여 데이터가 낮게 나온것으로 판단됩니다.
결과
이번 글에서는 벡터계산을 bert 모델을 통해 개선했지만, 결과적으로는 결과값이 부정적으로 나왔습니다.
마지막 글에서는 데이터를 많이 추가해보고 전처리 품질을 높이는 작업을 진행해보도록 하겠습니다.
'ML > MLops' 카테고리의 다른 글
| jenkins pipeline이 사라졌다!! (0) | 2025.05.08 |
|---|---|
| airflow + dbt 를 활용한 데이터 파이프라인 (0) | 2025.02.15 |
| [개인프로젝트] 나만의 추천시스템 만들기 (1) (0) | 2024.06.17 |
| [MLOps] Triton을 활용한 모델 배포 (0) | 2024.06.14 |
| ml를 쉽게 쓰기 위한 프론트 작업 (0) | 2024.05.03 |



