https://arxiv.org/abs/1810.04805
요약 : bert는 성능도 우수합니다! - 충분한 데이터만 있다면요
Abstract
- 양방향 인코더
- 트랜스포머와 달리 BERT는 레이블이 없는 텍스트의 양방향 표현을 사전 학습하도록 설계되었습니다
- 레이블이 없는 텍스트에 대해 컨디셔닝하여 모든 레이어에서 왼쪽과 오른쪽 컨텍스트를 학습한다. 그 결과, pre-trained BERT 모델은 단 하나의 추가 출력 레이어만으로 미세 조정할 수 있습니다.
1. Introduction
- pre-training 언어모델은 많은 자연어 처리 task의 향상에 좋은 성능을 발휘하고 있습니다.
- downstream task를 위해 pre-trainedfmf 학습하는 방식에는 두가지 방법이 있다
1. feature-baesd : ELMo
2. fine-tuning : Generative pre-trained transformer
* 한계
- 표준 언어 모델이 단방향적이어서 사전 학습 중에 사용할 수 있는 아키텍처의 선택이 제한됩니다.
- 대부분의 텍스트는 긴 context를 이해하고 대답하는 능력이 필요하다. (단방향에서는 긴 문장을 예측이 떨어진다)
BERT는 "masked language model"(MLM)의 pre-train를 사용하여 단방향성 제약을 완화 시킵니다.
- BERT는 대규모의 문장 수준 및 토큰 수준 작업에서 좋은 성능을 달성하는 최초의 미세 조정 기반 표현 모델입니다.
2. Related Work
2.1 비지도 학습 기반 접근
사전 학습된 단어 임베딩은 최신 NLP 시스템의 필수적인 부분으로 단어 임베딩 벡터를 사전 학습하기 위해 왼쪽에서 오른쪽으로 언어 모델링 목표와 왼쪽 및 오른쪽 문맥에서 올바른 단어와 잘못된 단어를 구별하는 목표가 사용되었습니다.
ELMo : 오른쪽에서 왼쪽으로 문맥에 민감한 특징을 추출 / 질문 답변, 감정 분석, 명명된 개체 인식에 사용
2.2 비지도 fine-tuning 접근
- 레이블되지 않은 사전훈련된 워드 임베딩 파라미터만 사용
3. BERT

pre-training 에서는 다음으로 학습을 진행한다.
- mask prediction : 입력 문장의 일부 단어를 가진뒤, 단어를 맞춤
* 마스크된 토큰의 위치를 무작위로 선택하여 원래 토큰값을 예측한다.
- next sentence prediction : 두개 문장을 입력으로 받고 두번째 문장이 첫번째 문장의 다음 문장인지 맞춤
fine-tuning 에서는 pre-training된 모델에서 더욱 성능을 높이기 위해 특정 문제에 대한 데이터를 학습하게 된다.
- 데이터셋의 입력과 출력에 연결된 모든 파라미터 가중치를 미세조정 (Fine Tuning)
model architecture
BERT의 모델 구조는 다중 레이어 bidirectional Transformer encoder
BERT_BASE: layer=12, Hidden size=768, self-attention head=12, Total Parameters=110M
- BERT는 양방향 self-attention을 사용하고, GPT Transformer는 모든 토큰이 왼쪽의 문맥만 attend하도록 강요된 self-attention 사용
BERT_LARGE: layer=24, Hidden size=1024, self-attention head=16, Total Parameters=340M
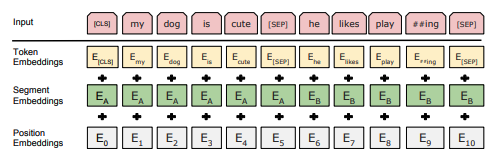
* 모든 sequence의 첫번째 토큰은 항상 [CLS] 토큰 / 마지막에는 [SEP] 토큰 사용 ( [CLS] : Classification / [SEP] : Separation )
* 주어진 토큰의 입력 표현은 해당 토큰, 세그먼트, position 임베딩을 합쳐서 구성
- 토큰 임베딩 : 단어를 딥러닝 모델들이 이해할 수 있는 고차원 벡터로 변환
- 세그먼트 임베딩 : 두개의 텍스트를 위치값 (A인지 B인지)
- position 임베딩 : 입력된 데이터의 순서
Effect of model size

모델 크기가 fine-tuning task 정확도에 미치는 관계
- 모델 사이즈를 키우는 것은 계속된 향상을 이끈다고 알려짐 (위의 그림)
- 충분한 pre-training + 극단적인 모델 크기의 확장 => 매우 작은 규모의 task에서도 큰 개선이 됨
* downstream task 데이터가 매우 작은 경우에도 pre-training으로 이익을 얻을 수 있음.
conclusion
심층 양방향 아키텍처로 일반화하여 사전 학습된 모델을 통해 NLP 작업을 성공적으로 처리할 수 있도록 공헌!
나의 결론
bert 장단점
장점
* BERT는 양방향 처리를 통해 다양한 문제에서 GPT보다 높은 성능을 통해 확인할 수 있음
* 특정 문제에 대한 질답을 fine-tuning으로 학습 한다면 NLP 문제에서 높은 성능을 낼 수 있음
단점
* 많은 파라미터로 인해 학습과 추론에 상당한 계산 비용이 요구
* 대량의 학습 데이터가 필요
끝!
참조
https://ffighting.net/deep-learning-paper-review/language-model/bert/
https://wiz-tech.tistory.com/m/83
'ML > LLM' 카테고리의 다른 글
| [dacon] 도배 하자 질의 응답 처리 : 한솔데코 시즌2 AI 경진대회 (4) | 2024.02.28 |
|---|---|
| [논문리뷰] Retrieval-Augmented Generation for Large Language Models: A Survey (1) | 2024.02.19 |
| [논문리뷰] Precise Zero-Shot Dense Retrieval without Relevance Labels (HyDE) (0) | 2024.02.14 |
| [논문리뷰] Lost in the Middle: Models Use Long Contexts (2) | 2024.02.13 |
| 3. 벡터 임베딩를 활용한 성과 지표 (다중 분류 문제) (1) | 2024.01.29 |



