데이터 웨어하우스에서 데이터를 변환하고 모델링하는 작업은 SQL을 작성하고, 파이프라인을 구축하고, 테스트하는 모든 과정하나하나 코드로 작성해야 했다. 나의 경우엔 예전에 포스팅했던 NES(notebook 환경)를 통해서 데이터 파이프 라인 작업을 하지만 가장 큰 문제가 정합성과 테스트가 문제였다. (+데이터 카탈로그의 부재도 한몫한다)
파이썬 + sql + numpy로 동작하는 작업에서 저장되는 데이터가 한곳이 아닌 여러곳이였으며(심지어 외부 저장소도 있었다.. ) 데이터 정합성과 실패에 대한 대책을 코드로 하다보니, 데이터 칼럼이 변경되거나, 로직이 변경되면 난리도 아니였다. (변경되는 해당 칼럼이 적용된 파이프라인만 찾는것도 하루가 걸린적이..)
그래서 찾아보다가 dbt를 사용해서 transform을 작업했었다. (테스트 까지만)
[document는 airflow에 대한 리니지+카탈로그가 가능한 datahub를 다른 팀에서 쓰고 있어서 얻혀갔다. ㅎㅎ]
1. DBT?
dbt는 SQL과 Jinja 템플릿을 사용하여 데이터 Transformation 작업을 정의하여 이를 실행할 수 있도록 지원하고 있다. 개발, 유지보수, 고도화, 그리고 인수인계 과정에서 발생하는 개발 비용을 크게 줄여준다.
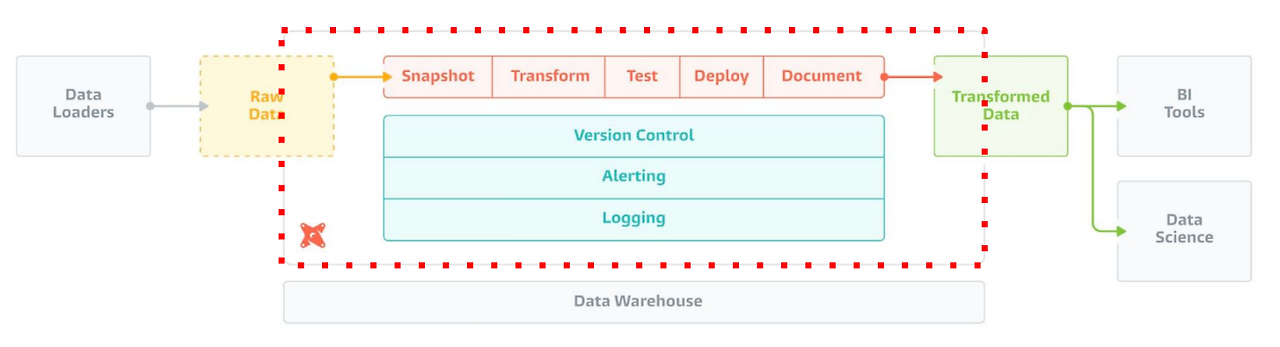
dbt는 크게 다섯가지 task 작업을 실시한다.
1. snapshot : 데이터베이스의 특정 시점에서 테이블의 상태를 기록하는 작업.주로 변경 데이터 캡처(CDC)를 구현할 때 사용
2. transform : 원시 데이터를 변환하여 분석에 적합한 형태로 가공하는 작업 (정제, 집계, 조인)
3. test : 데이터의 무결성과 품질을 검증하기 위해 테스트를 수행하는 작업
4. deploy : 개발된 dbt 모델과 파이프라인을 프로덕션 환경에 배포
5. document : dbt 프로젝트의 모델, 테이블, 컬럼 등에 대한 문서를 자동으로 생성하는 작업
dbt의 주요 장점
1. 버전 관리와 협업이 용이
SQL 코드를 마치 소프트웨어처럼 관리할 수 있어, git과 함께 사용하면 여러 팀원이 함께 작업하고 변경 이력을 추적하기가 훨씬 수월해진다.
2. 모듈화와 재사용성 (중요!)
ex : 일일 매출 집계 로직을 한 번 작성해두면 이를 여러 모델에서 참조 가능
공통된 비즈니스 로직을 매크로로 만들어 재사용
-- 매출 집계 모델 예시
WITH daily_revenue AS (
SELECT
date_trunc('day', order_date) as date,
sum(amount) as revenue
FROM {{ ref('raw_orders') }}
GROUP BY 1
)
3 테스트 자동화
데이터의 품질을 보장하기 위한 다양한 테스트를 자동으로 실행.
예를 들어 주문 금액이 음수가 아닌지, 고객 ID가 항상 존재하는지 등을 검증할 수 있다.
version: 2
models:
- name: orders
columns:
- name: amount
tests:
- not_null
- positive_values
dbt 단점
리소스 관리에 주의해야 한다. (중간에 멈출수가 있나??) 잘못 설계된 모델은 데이터 웨어하우스의 비용을 크게 증가시킬 수 있다. 특히 증분 업데이트(incremental) 모델을 잘못 설계하면 전체 데이터를 다시 처리하게 되어 비용이 급증할 수 있다.
사용 예시
- 원본 데이터(주문, 고객, 제품 테이블)를 데이터 웨어하우스에 적재
- dbt로 데이터 정제 및 기본 집계 수행
- 비즈니스 KPI용 마트 테이블 생성
- BI 도구와 연동하여 대시보드 구축
2. 구현
전체 코드는 다음 github에 올려놧습니다. https://github.com/uiandwe/airflow-dbt
데이터만 kaggle에서 받아서 디비에 넣어주면 됩니다. (데이터가 너무 커서 git에 올릴수 없음요)
1. 사용 데이터
데이터는 kaggle에서 서울의 공기오염도 데이터를 선택했다.
https://www.kaggle.com/datasets/bappekim/air-pollution-in-seoul
Air Pollution in Seoul
Air Pollution Measurement Information in Seoul, Korea
www.kaggle.com
해당 데이터를 디비에 넣고, airflow에서 dbt를 통해서 집계하는 것을 목표로 했다.
2. dbt 구조
모델을 저장하는 방식에는 여러가지 패턴이 있다. (정확히는 자기 정하기 나름이다.)
나는 메타몽님의 블로그에서 비즈니스 도메인 패턴에 맞게 설정했다.
자세한 사항은 메타몽님 블로그를 참조하면 좋다.
비즈니스 도메인 맞춤
- staging : 초기 정제
- intermediate : 중간 집계나 조인
- mart : 최종 분석용 테이블
models/
├── staging/
│ ├── staging_measurements.sql
├── intermediate/
│ ├── ...
│ └── ...
└── mart/
├── air/
│ ├── daily_aggregation.sql
│ ├── monthly_aggregation.sql
│ ├── weekly_aggregation.sql
│ └── yearly_aggregation.sql
├── marketing/
│ ...
│ ...
└── product/
...
...
3. 집계 SQL
해당 데이터에 대해서 일별 / 주별 / 월별 / 연도별 집계를 하는 쿼리이다.
해당 쿼리를 models/air 폴더(도메인별 폴더)에 정의한다.
daily_aggregation.sql
SELECT
DATE(measurement_date) AS date,
station_code,
item_code,
AVG(average_value) AS avg_value
FROM {{ ref('staging_measurements') }}
GROUP BY date, station_code, item_code
monthly_aggregation.sql
SELECT
DATE_TRUNC('month', measurement_date) AS month,
station_code,
item_code,
AVG(average_value) AS avg_value
FROM {{ ref('staging_measurements') }}
GROUP BY month, station_code, item_code
weekly_aggregation.sql
SELECT
DATE_TRUNC('week', measurement_date) AS week,
station_code,
item_code,
AVG(average_value) AS avg_value
FROM {{ ref('staging_measurements') }}
GROUP BY week, station_code, item_code
yearly_aggregation.sql
SELECT
DATE_TRUNC('year', measurement_date) AS year,
station_code,
item_code,
AVG(average_value) AS avg_value
FROM {{ ref('staging_measurements') }}
GROUP BY year, station_code, item_code
4. 실행
docker-compose 를 실행하고, airflow에 접근한다. (localhost:8080)
로그인 정보는 admin // admin 이다.
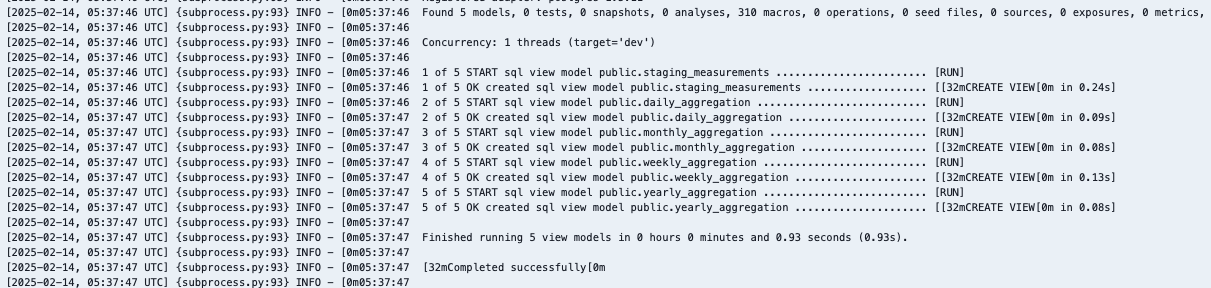
process_dbt_dag를 실행하면 다음과 같이 dbt가 실행된다. (파이썬 패키지로 dbt를 실행가능한 패키지도 있지만, 기본 dbt cli와 같기 때문에 나는 cli로 실행한다.)
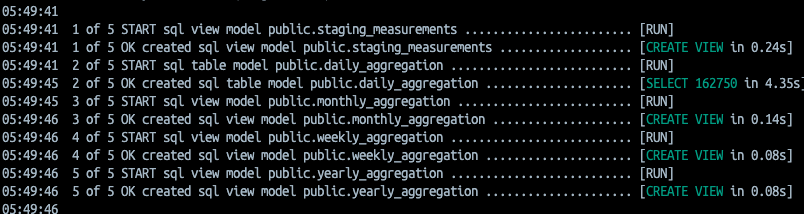
그러면 아래와 같이 실행결과가 나올것이다.
staging에서 원본 데이터를 읽고, air 도메인에 있는 sql를 실행 결과이다.
결과는 view로 표현된다.
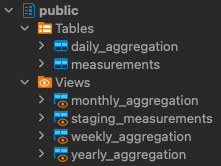
해당하는 view가 생성된것을 볼수 있다.
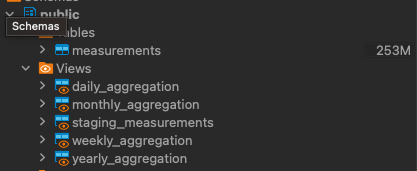
dbt는 기본적으로 View를 생성하지만, 실제로는 View와 Table 둘 다 만들 수 있다. 이는 모델의 materialization 설정에 따라 달라진다
models:
your_project:
model_name:
materialized: view- Views : 자주 변경되는 소규모 데이터, view 생성
- Table : 자주 조회되는 대규모 데이터, 실제 데이터 저장
- Incremental : 시계열 등 증분 데이터, 새로운 데이터만 저장
- Ephemeral : 임시 중간 변환, 실제로 뷰나 테이블을 만들지 않고 CTE로 처리
sql에 설정함으로써 table에 저장할수 있다. (템플릿언어로 지정)
daily_aggregation.sql의 상단을 다음과 같이 변경하였다. ( materialized에 원하는 변경값으로 넣어주면 된다. )
{{ config(materialized='table', sort='date') }}
SELECT
DATE(measurement_date) AS date,
station_code,
item_code,
AVG(average_value) AS avg_value
FROM {{ ref('staging_measurements') }}
GROUP BY date, station_code, item_codeTable로 변경해서 다시 실행해보면 다음과 같이 테이블이 생성된것을 볼 수 있다.
https://docs.getdbt.com/docs/build/materializations
자세한 사항은 역시 공식 문서를 보면 된다!!
Materializations | dbt Developer Hub
Configure materializations in dbt to control how the SQL is run and resulting data is stored.
docs.getdbt.com
끝!
참고
https://zzsza.github.io/data-engineering/2025/01/16/dbt-core/
https://medium.com/iotrustlab/data-warehouse-with-dbt-b65be67750e9
'ML > MLops' 카테고리의 다른 글
| jenkins pipeline이 사라졌다!! (0) | 2025.05.08 |
|---|---|
| [개인프로젝트] 나만의 추천시스템 만들기 (2) (1) | 2024.06.20 |
| [개인프로젝트] 나만의 추천시스템 만들기 (1) (0) | 2024.06.17 |
| [MLOps] Triton을 활용한 모델 배포 (0) | 2024.06.14 |
| ml를 쉽게 쓰기 위한 프론트 작업 (0) | 2024.05.03 |



