데이터를 쉽게 접근할 수 있도록 csv로 저장해서 사용한다. 하지만 csv는 메타데이터를 저장할 수 없어 칼럼 별로 dtype을 다시 지정해줘야 하는 일이 생기며, 읽고 쓸 때 시간이 많이 걸린다는 단점이 있다.
이를 보완하기 위해 pickel, parquet, hdf5 와 같은 다양한 데이터 포맷을 사용하는데 그중 parquet에 대해서 알아본다
what is parquet?
Apache Parquet는 데이터 처리 프레임워크, 데이터 모델 또는 프로그래밍 언어에 관계없이 Hadoop 생태계의 모든 프로젝트에서 사용할 수 있는 칼럼형 스토리지 형식

Columnar
parquet의 저장 방식은 컬럼 지향으로 저장한다.
- 칼럼 단위의 값은 데이터가 유사할 가능성이 높다. 이로 인해 높은 압축률을 얻을 수 있다.
- MIN, MAX, SUM, COUNT 와 같은 연산에서 높은 성능을 얻을 수 있다.
- 칼럼 단위로 읽는다면 다음 번 값이 페이지 캐시 될 확률이 높다.
컬럼 지향 데이터베이스는 데이터를 칼럼 단위로 묶어서 저장한다. 그런 다음 이 칼럼 값은 디스크 상에 연속적으로 저장된다. 이 방식은 전통적인 파일의 전체 로우가 연속적으로 저장되는 일반적인 로우 지향형 접근방식과 다르다.
칼럼 기반으로 데이터를 저장하는 이유는, 특정 쿼리에 대해서는 로우의 모든 데이터가 필요하지 않다는 가정에 기반하고 있다. 이러한 경우는 특히 분석적인 데이터에서 자주 발생하기 때문에 분석 처리 파일들은 이러한 형태의 저장 스키마를 사용하기 위한 좋은 후보이다.
I/O 가 줄어든다는 이유만으로도 이 새로운 데이터 저장 구조를 채택할 법한데, 이 구조는 여기에 높은 압축률이라는 장점까지 제공한다.
일반적으로 서로 다른 논리적인 로우 상의 같은 칼럼 값들은 본질상 매우 유사하기 마련이고, 때로는 아주 약간씩만 다르기 때문에, 압축을 위해 서로 묶이는 편이 서로 상이한 값들로 이루어진 로우 지향 레코드 구조보다 훨씬 나을 때가 많다.
번외 칼럼 지향 "데이터베이스"로는 아마존 Redshift, 아파치 Cassandra, HBase 등이 있다.
파일 타입별 벤츠마크
csv는 로드/저장시 high comp low io로 처리할 수 있다. 호환성이 뛰어나고 변환 가능한 포맷에서는 위력을 발휘할 수 있다. 하지만 특정 데이터를 다룬다면 다른 포맷을 꼭 확인해 봐야 한다.

메모리 관련하여 hdf은 좋지 않은 성능을 보여준다. csv는 저장 /로드 일반 텍스트 문자열 동안 추가 메모리를 필요하지 않는다.(바로 저장한다) feather와 parquet 매우 좋은 성능을 나타낸다.

파일 크기. parquet 형식은 대량의 데이터를 효율적으로 저장하기 위해 개발되었다.
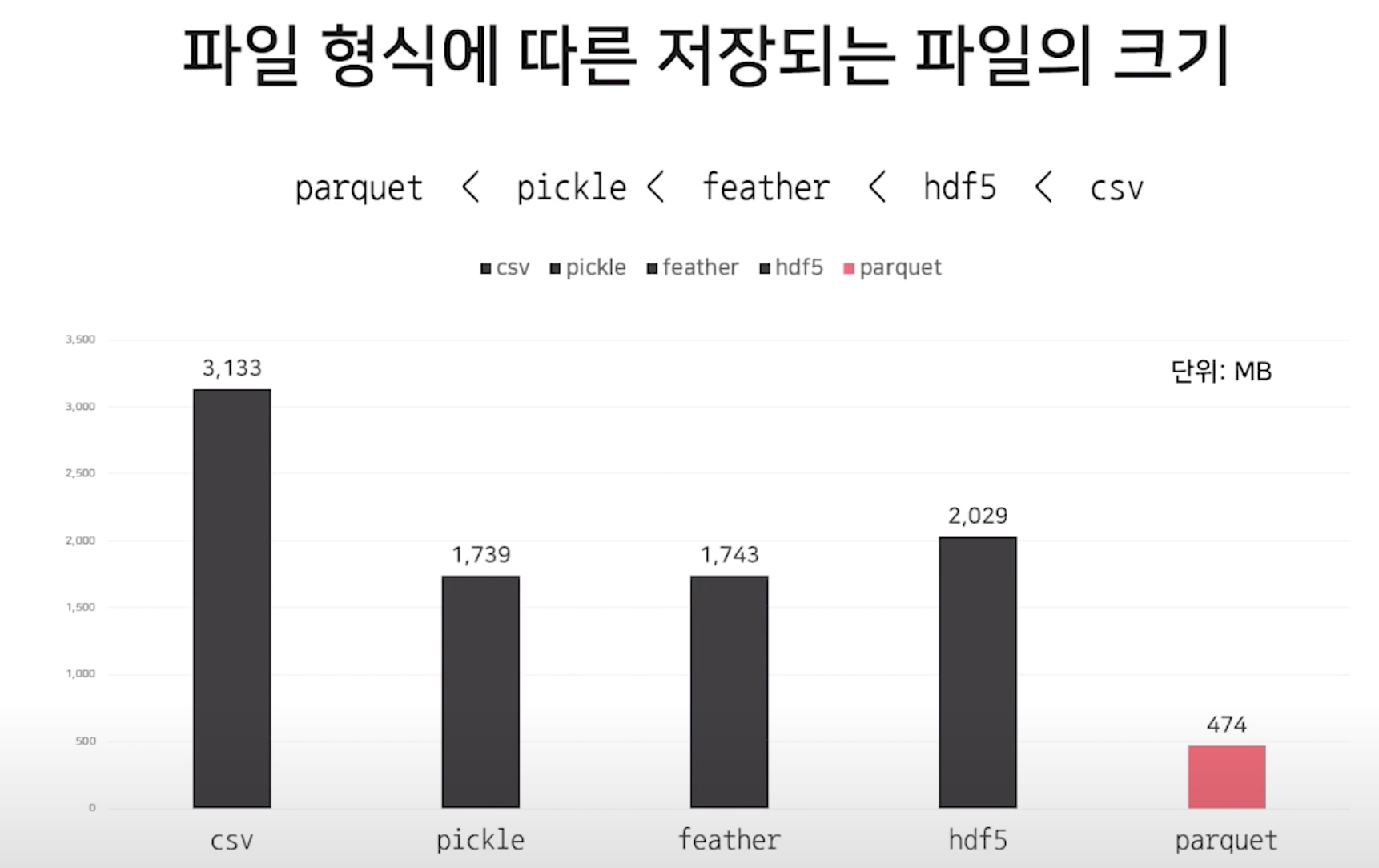
용량의 차이가 느껴지십니까?
- 동일한 데이터를 csv / parquet로 저장할시 용량 비교

번외 용도에 따른 파일 선택

parquet 장점
- 파입 압축과 쓰기, 읽기에 탁월하다.
- 분산처리에 적합하다
parquet 단점
- 데이터에 2차원 배열을 쓸 수 없다. (리스트만 가능)
- 다차원 배열을 쓰고 싶다면 hdf5가 적합하다
파이썬으로 parquet 사용하기 예제
1. pandas 에서의 간단한 parquet 사용하기 (읽기 / 쓰기)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# !pip install fastparquet
# save
import pandas as pd
df = pd.DataFrame()
df.to_parquet('sample.parquet', compression='gzip')
# read
df = pd.read_parquet('sample.parquet')
print(df)
|
cs |
2. s3의 parquet 파일 읽기 ( 스트림 )
- s3에 해당 파일들을 업로드한 후 실습합니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
# -*- coding: utf-8 -*-
import boto3
import pandas as pd
import pyarrow
import pyarrow.parquet as pq
def read_surprise_table(obj):
buf = obj.get()['Body'].read()
reader = pyarrow.BufferReader(buf)
df = pq.read_table(reader).to_pandas()
return df
s3 = boto3.resource('s3')
bucket = 'test.parquet.bucket' # bucket name
path = 'test_parquet/' # object path
s3bucket = s3.Bucket(bucket)
merged_df = pd.DataFrame()
# 해당 경로에 있는 모든 parquet 파일을 읽어서 반환
for obj in s3bucket.objects.filter(Delimiter='/', Prefix=path):
print("bucket:{}, key:{}".format(obj.bucket_name, obj.key))
if not (obj.key.startswith(path+"sample") and obj.key.endswith(".parquet")):
continue
df = read_surprise_table(obj)
if merged_df.shape[0] == 0:
merged_df = df
else:
merged_df = pd.concat([merged_df, df], axis=0)
print(merged_df)
|
cs |
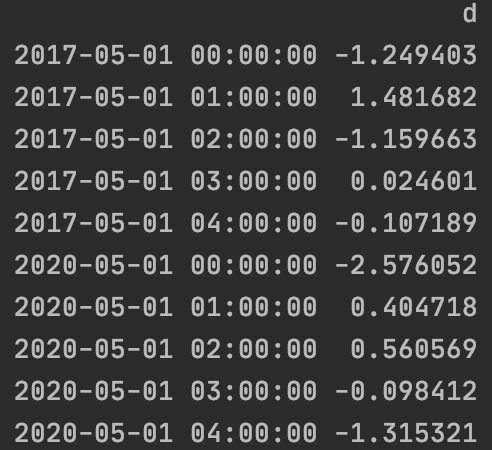
3. AWS s3-select
s3에 저장된 파일들에 select문을 통해 데이터를 가져올 수 있다!!
select문에 해당하는 데이터만 필터되기 때문에, 우리는 모든 파일들을 다운→열고→검색하는 수고를 덜 수 있다.

언제 쓰면 좋은가?
- 쿼리를 수행할 대상 데이터가 많은 경우
- 저장된 객체 중 일부 데이터만 실제 필요한 경우
- 부분적인 데이터를 가져올 수 있어서 사용자 특화된 데이터만 얻고 싶은 경우
- Spark나 Presto같은 tool을 사용해서 데이터 분석을 하기 전 사전 필터링을 수행하고 싶은 경우
- 애플리케이션 단에서 로드하고 처리할 데이터 양을 줄여서 성능 개선을 하고 싶은 경우
3-1. s3 웹서비스에서의 sql select 처리
- 데이터 다운로드 경로 https://www1.nyc.gov/site/tlc/about/tlc-trip-record-data.page
- s3에 업로드한 해당 파일을 선택한 후
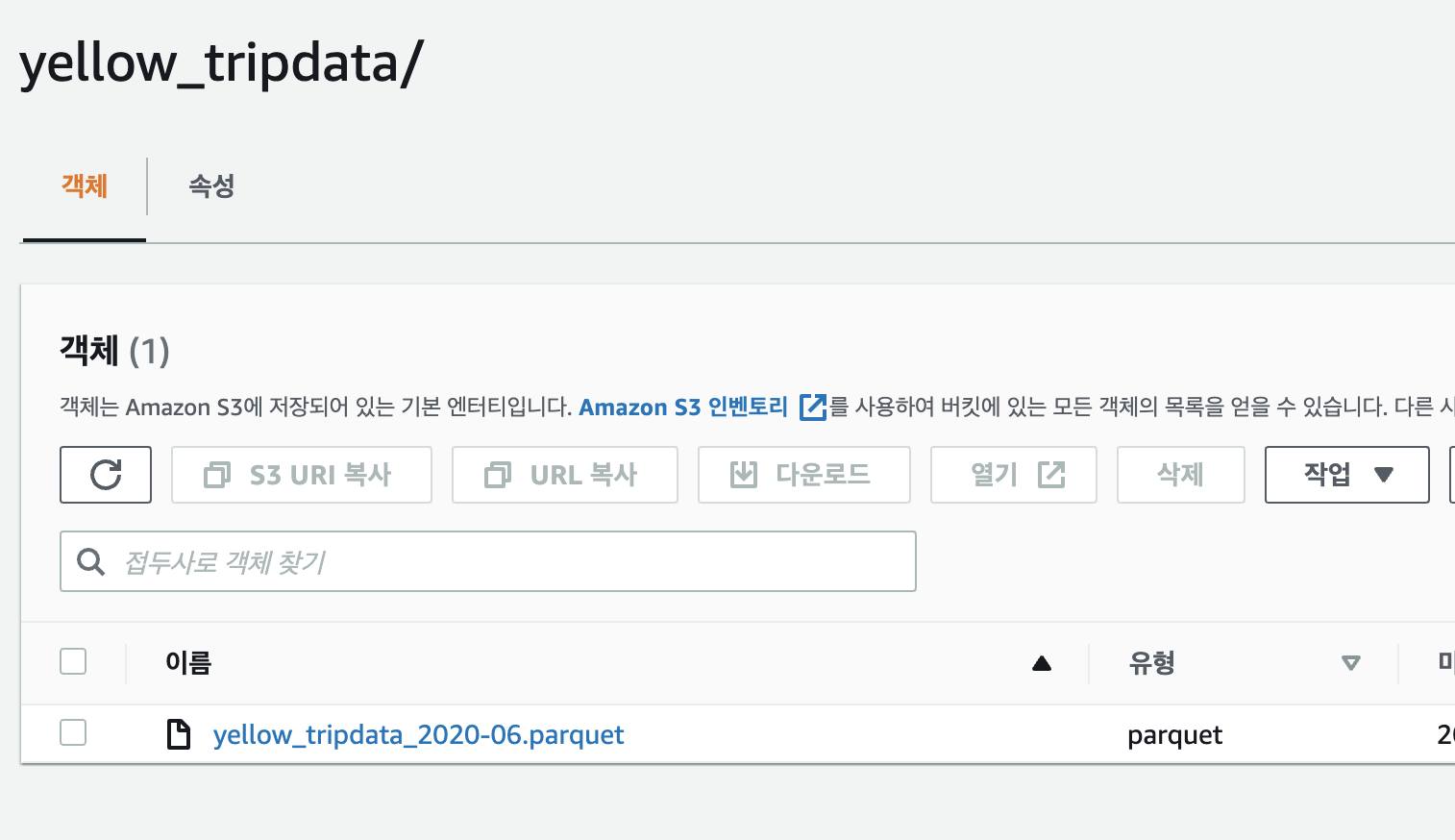
작업 → s3 select 쿼리를 선택
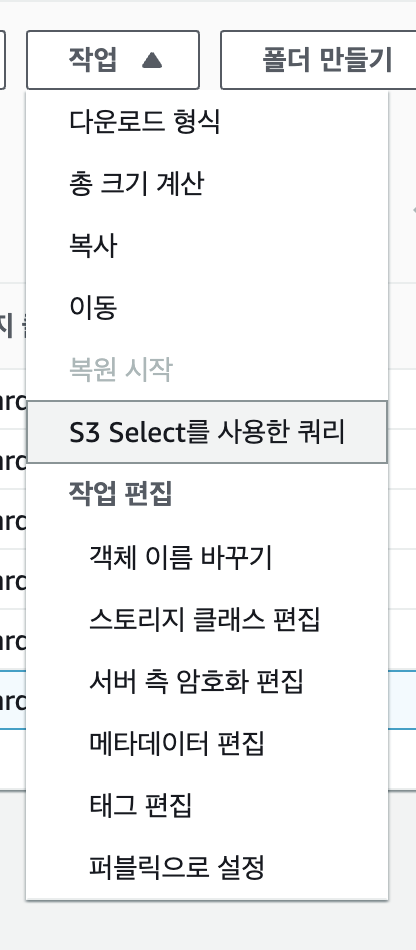
쿼리문은 다음과 같다
SELECT VendorID, tpep_pickup_datetime, tpep_dropoff_datetime, passenger_count, trip_distance, tip_amount, total_amount FROM S3Object WHERE payment_type = 5
쿼리의 결과가 다음과 같이 나오는 것을 확인할 수 있다.
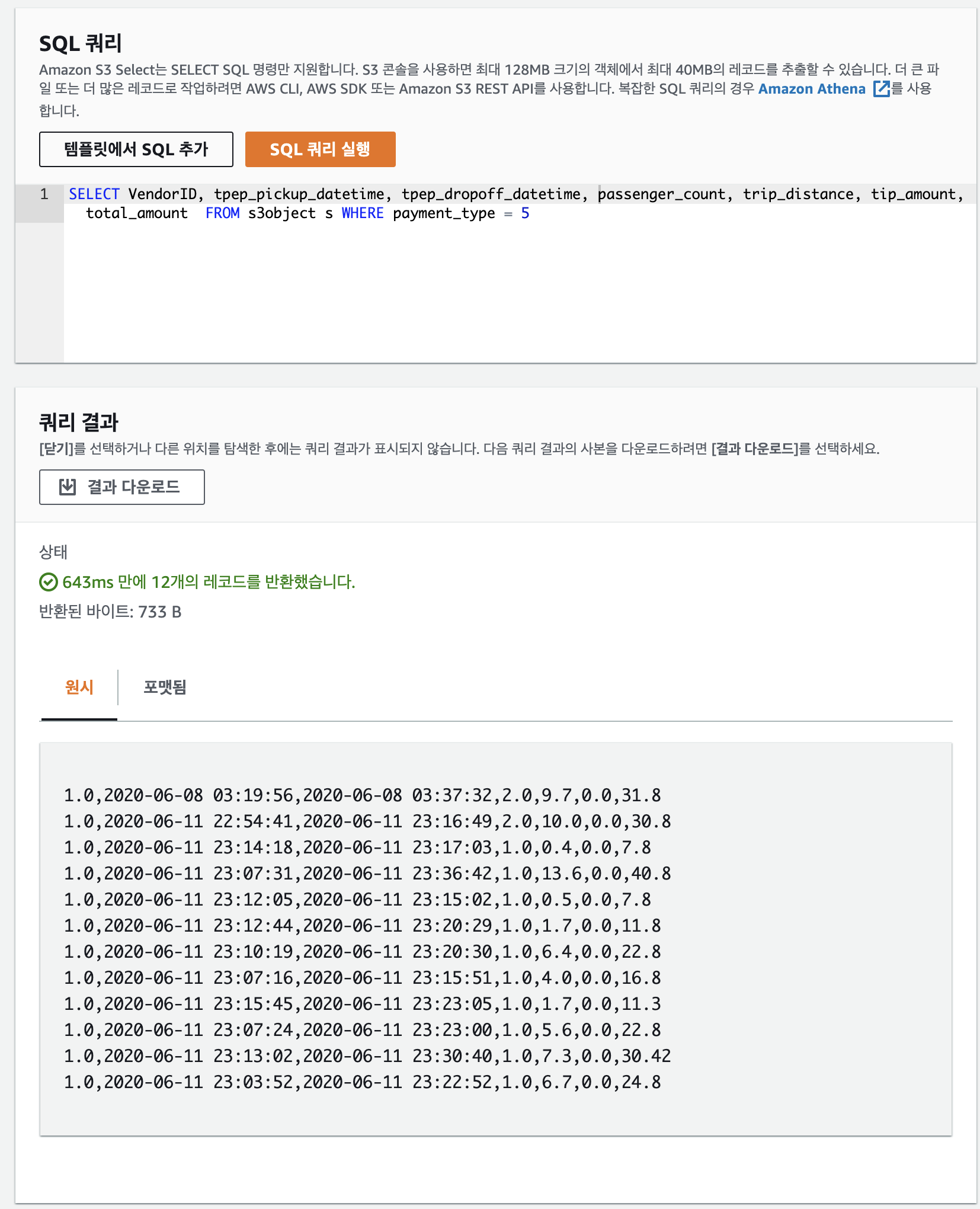
3-2. aws cli 를 통한 parquet에 sql select 처리
- 아래 사용 데이터 다운로드 경로 https://www1.nyc.gov/site/tlc/about/tlc-trip-record-data.page
- 위의 데이터 csv를 parquet로 저장
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
# -*- coding: utf-8 -*-
import os
import boto3
import pandas as pd
S3_KEY = 'test_parquet/yellow_tripdata_2020-06.parquet'
S3_BUCKET = 'test.haezoom'
TARGET_FILE = 'unknown_payment_type.csv'
s3_client = boto3.client(service_name='s3')
query = """SELECT VendorID, tpep_pickup_datetime, tpep_dropoff_datetime,
passenger_count, trip_distance, tip_amount, total_amount
FROM S3Object
WHERE payment_type = 5"""
result = s3_client.select_object_content(Bucket=S3_BUCKET,
Key=S3_KEY,
ExpressionType='SQL',
Expression=query,
InputSerialization={'Parquet': {}},
OutputSerialization={'JSON': {}})
# remove the file if exists, since we append filtered rows line by line
if os.path.exists(TARGET_FILE):
os.remove(TARGET_FILE)
# 해당 데이터 csv로 저장
with open(TARGET_FILE, 'a+') as filtered_file:
# write header as a first line, then append each row from S3 select
filtered_file.write('ID,pickup,dropoff,passenger_count,distance,tip,total\n')
for record in result['Payload']:
if 'Records' in record:
res = record['Records']['Payload'].decode('utf-8')
filtered_file.write(res)
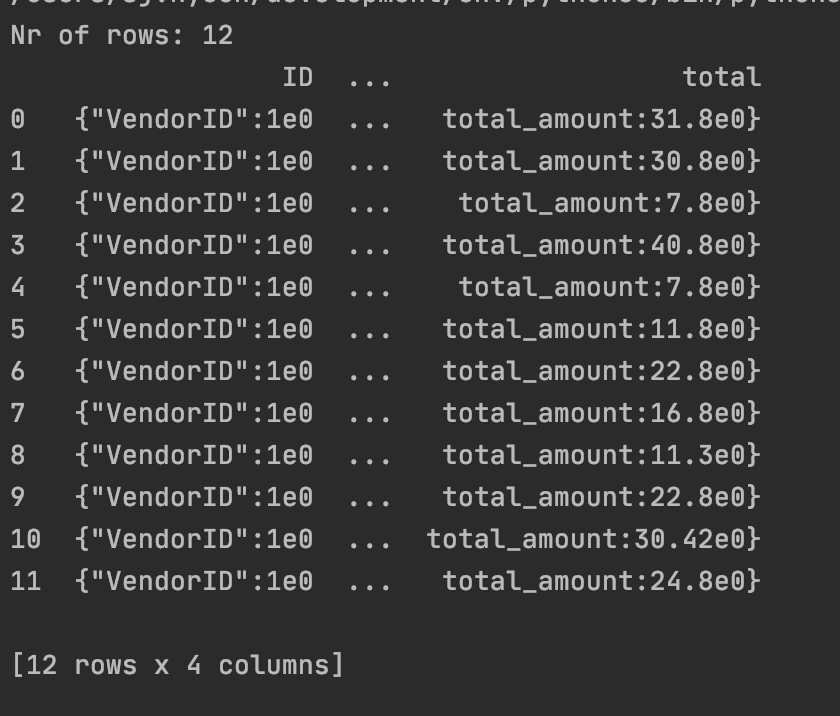
df = pd.read_csv('unknown_payment_type.csv')
print(f'Nr of rows: {len(df)}')
print(df[['ID', 'distance', 'tip', 'total']])
|
cs |
번외 s3의 csv를 sql select 처리
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
# -*- coding: utf-8 -*-
import os
import boto3
import pandas as pd
S3_KEY = 'test_parquet/yellow_tripdata_2020-06.csv'
S3_BUCKET = 'test.haezoom'
TARGET_FILE = 'unknown_payment_type.csv'
s3_client = boto3.client(service_name='s3')
query = """SELECT VendorID, tpep_pickup_datetime, tpep_dropoff_datetime,
passenger_count, trip_distance, tip_amount, total_amount
FROM S3Object
WHERE payment_type = '5'"""
result = s3_client.select_object_content(Bucket=S3_BUCKET,
Key=S3_KEY,
ExpressionType='SQL',
Expression=query,
InputSerialization={'CSV': {'FileHeaderInfo': 'Use'}},
OutputSerialization={'CSV': {}})
# remove the file if exists, since we append filtered rows line by line
if os.path.exists(TARGET_FILE):
os.remove(TARGET_FILE)
with open(TARGET_FILE, 'a+') as filtered_file:
# write header as a first line, then append each row from S3 select
filtered_file.write('ID,pickup,dropoff,passenger_count,distance,tip,total\n')
for record in result['Payload']:
if 'Records' in record:
res = record['Records']['Payload'].decode('utf-8')
filtered_file.write(res)
df = pd.read_csv('unknown_payment_type.csv')
print(f'Nr of rows: {len(df)}')
print(df[['ID', 'distance', 'tip', 'total']])
|
cs |
4. aws athena 로 parquet sql select 요청
Q: 왜 athena 써야 돼요? 위에 aws-cli 쓰면 되는데?
A: aws-cli는 단일 파일만 검색이 가능. 여러개의 파일을 한 번의 쿼리로 처리하려면? 돈을 내야 하는 athena 제품을 쓰세요!!!
- 비슷한 걸로 google bigQuery 가 있다.
- 데이터베이스 생성
create table 클릭 후 데이터의 경로를 s3 경로를 넣어주면 된다.
- 테이블 생성

- sql 문을 사용하기 위해서 칼럼 타입에 맞게 테이블을 생성해 줘야 한다. (파일에 저장된 타입과 해당 타입이 다를 경우 쿼리 실행 시 에러가 발생한다)
- 쿼리 실행
SELECT * FROM S3Object WHERE payment_type = 5
번외 athena 실행시 WorkGroup primary is disabled.
athena는 외부 api 요청으로 쿼리를 날릴 수 있는 형태로 사용하지 않는다면 반드시 workgroup를 꺼 놓는 것을 추천한다. 그렇지 않다면? 재무실로 불려 가게 될 것이다.


참고
https://beomi.github.io/2020/01/29/Use-parquet-on-pandas/
https://towardsdatascience.com/the-best-format-to-save-pandas-data-414dca023e0d
https://data-newbie.tistory.com/279
https://engineering.vcnc.co.kr/2018/05/parquet-and-spark/
https://aws.amazon.com/ko/blogs/korea/s3-glacier-select/
https://www.youtube.com/watch?v=1j8SdS7s_NY&ab_channel=Databricks
https://www.youtube.com/watch?v=0Vm9Yi_ig58&ab_channel=PyConKorea
'app > python' 카테고리의 다른 글
| cython : python to C (0) | 2021.07.28 |
|---|---|
| ERROR: Cannot install -r /requirements.txt because these package versions have conflicting dependencies. (0) | 2021.07.26 |
| pickle (0) | 2021.06.28 |
| pip multiple versions of dependency resolver problem (1) | 2021.06.10 |
| 파이썬 부동소수점 사용시 주의할점 (1) | 2021.06.09 |



