selenium을 비용을 최소로 하기 위해서 lambda에 docker 를 이용하는 방법을 이용했다.
해당 작업의 기초적인 소스 코드를 공유하고자 한다.
프로젝트 구성은 다음과 같다. (venv는 무시해도 된다.)
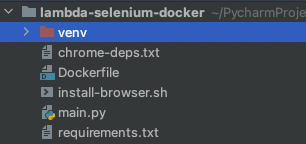
해당 파일들은 github에 올려놨으니 받아서 사용해도 된다.
https://github.com/uiandwe/lambda-selenium-docker
GitHub - uiandwe/lambda-selenium-docker
Contribute to uiandwe/lambda-selenium-docker development by creating an account on GitHub.
github.com
chrome-deps.txt : chrome 설치에 필요한 yum 패키지 리스트
install-browser.sh : chromebrower 와 chromedriver 설치 스크립트
requirements.txt : pip 패키지 리스트 (필요한것만 추가해서 설치하면 된다.)
Dockerfile
main.py
Dockerfile 코드 설명
도커파일에서는 크롬 드라이버 버전을 지정하였으며,
크롬과 크롬드라이버는 /opt에 설치하는것을 볼수 있다.
또한 사용할 파일들은 /var/task에 넣어야 한다!!!! (람다 특성상 다른위치에 있으면 실행되지 않는다.)
FROM public.ecr.aws/lambda/python:3.9 as stage
RUN yum install -y -q sudo unzip
ENV CHROMIUM_VERSION=1002910
# Install Chromium
COPY install-browser.sh /tmp/
RUN /usr/bin/bash /tmp/install-browser.sh
FROM public.ecr.aws/lambda/python:3.9 as base
COPY chrome-deps.txt /tmp/
RUN yum install -y $(cat /tmp/chrome-deps.txt)
# Install Python dependencies for function
COPY requirements.txt /tmp/
RUN python3 -m pip install --upgrade pip -q
RUN python3 -m pip install -r /tmp/requirements.txt -q
COPY --from=stage /opt/chrome /opt/chrome
COPY --from=stage /opt/chromedriver /opt/chromedriver
# copy main.py
COPY main.py /var/task/
WORKDIR /var/task
CMD [ "main.handler" ]
main.py 파일 설명
간단하게 naver의 description을 가져오는것을 구현 했다.
import json
from selenium import webdriver
from selenium.webdriver.common.by import By
def handler(event=None, context=None):
chrome_options = webdriver.ChromeOptions()
chrome_options.binary_location = "/opt/chrome/chrome"
chrome_options.add_argument("--headless")
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument("--single-process")
chrome_options.add_argument("--disable-dev-shm-usage")
chrome_options.add_argument("user-agent=Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko")
chrome_options.add_argument('window-size=1392x1150')
chrome_options.add_argument("disable-gpu")
browser = webdriver.Chrome(executable_path="/opt/chromedriver", options=chrome_options)
print("browser", browser)
browser.get("https://www.naver.com/")
description = browser.find_element(By.NAME, "description").get_attribute("content")
print(description)
browser.close()
return {
"statusCode": 200,
"body": json.dumps(
{
"message": description,
}
),
}
if __name__ == '__main__':
handler()
도커 빌드
가장 중요한!!!
빌드시 반드시 linux/x86_64커맨드가 추가 되어야 크롬이 정상적으로 작동한다!!
docker build --platform linux/x86_64 -t "이미지이름" -f Dockerfile .
빌드한 이미지를 ECR에 업로드 한다!!
업로드 방법은 아래의 블로깅을 참조하자!!
https://velog.io/@ironkey/AWS-Lambda%EB%A5%BC-Docker%EB%A1%9C-%EA%B5%AC%EC%B6%95%ED%95%98%EA%B8%B0
AWS Lambda를 Docker로 구축하기
AWS Lambda는 단순 코드뿐 아니라 Docker Image로 실행시킬 수 있습니다. 해당 포스팅은 Lambda를 Docker로 구축하는 방법을 가이드합니다.
velog.io
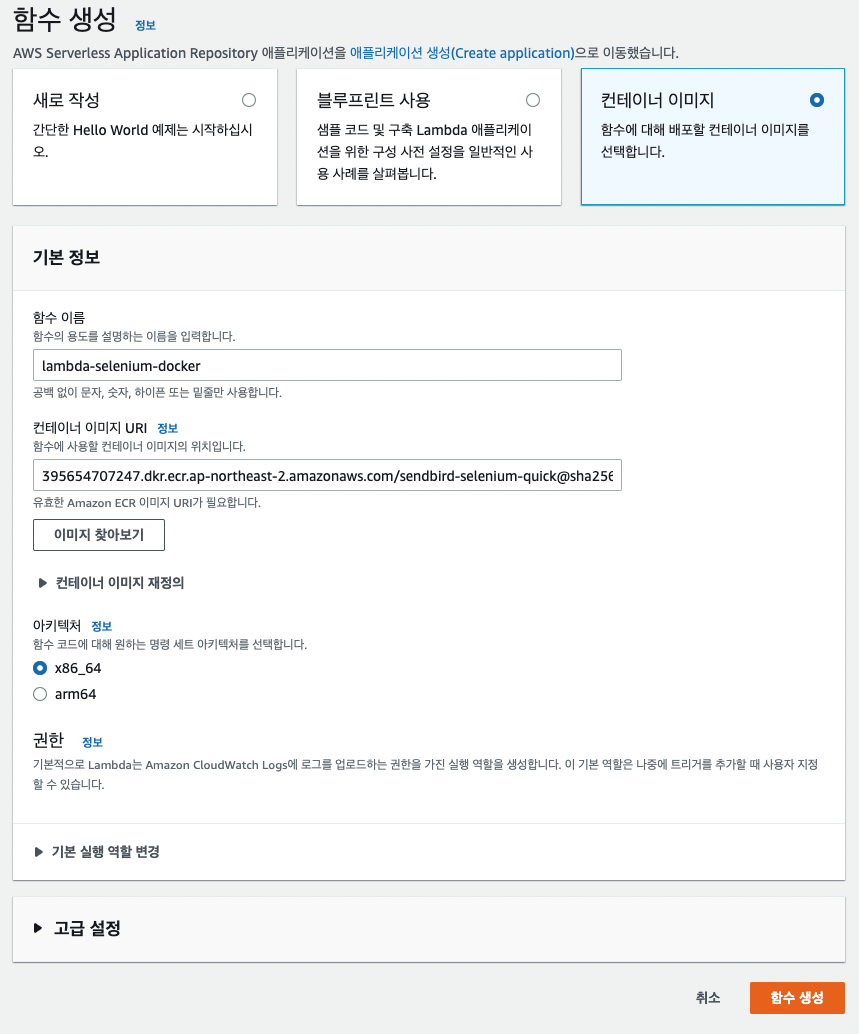
Lambda function create
람다 함수를 생성한다.
컨테이너 이미지를 선택하고, ecr에 업로드한 컨테이너 이미지를 선택한다.
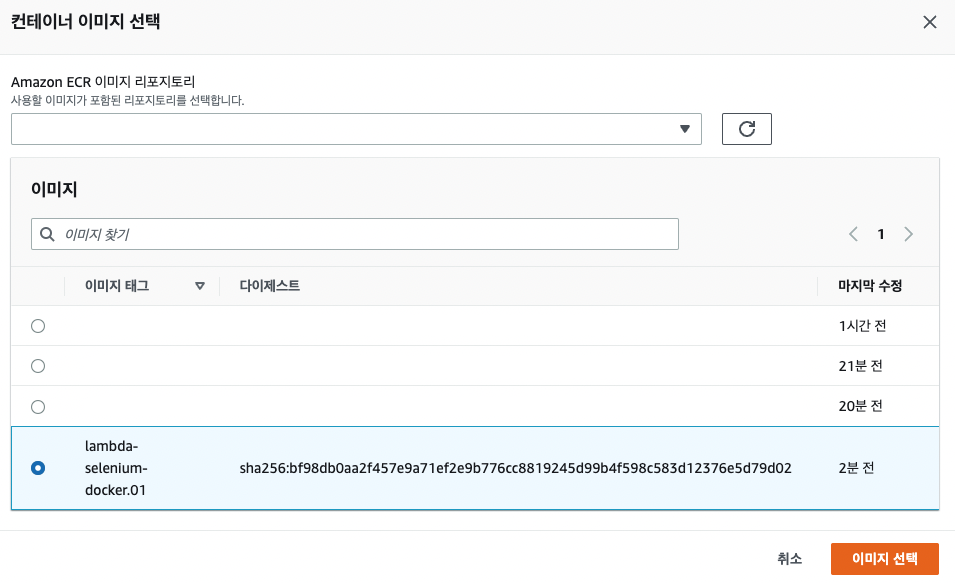
컨테이너 이미지 선택!
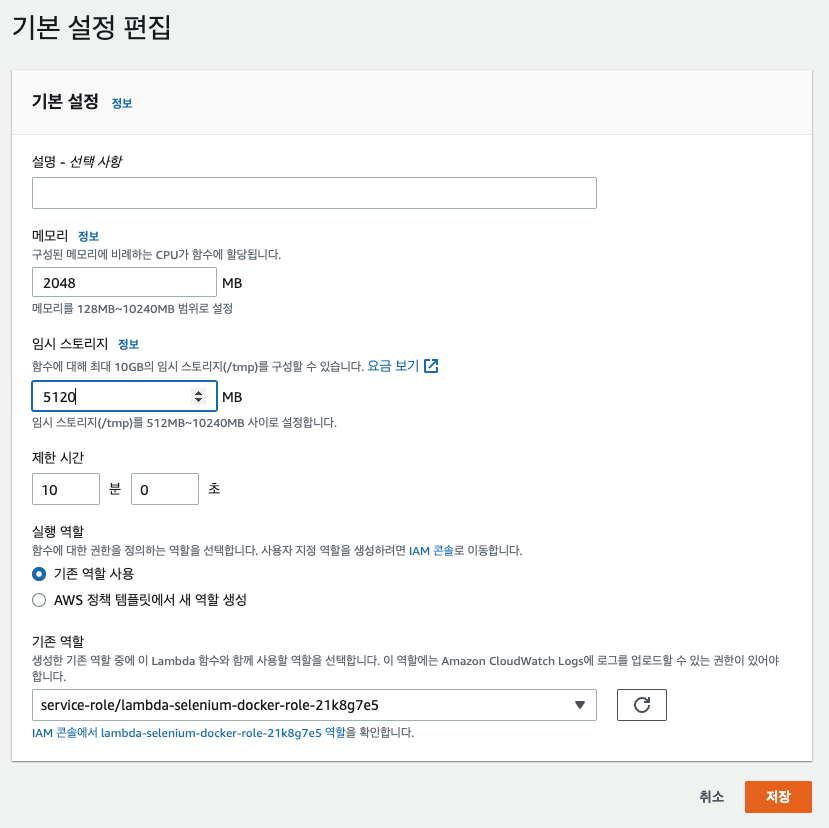
람다 기본 설정 변경
중요!! 람다 기본 설정 변경 한다!!
메모리와 제한 시간때문에 selenium이 멈출수 있다
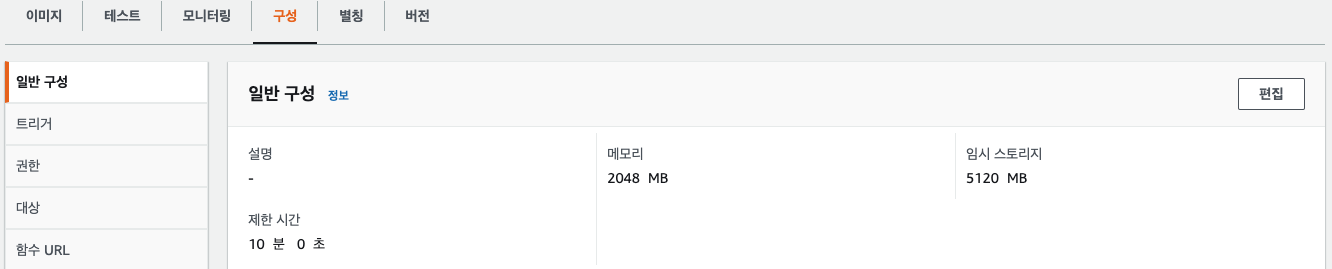
나의 경우 메모리 2G / 스토리지 5G / 제한시간 10분으로 설정 했다
변경된것을 확인해 보자!
테스트
정상적으로 동작하는지 테스트를 해보자
기본 제공되는 테스트를 실행하면 된다!
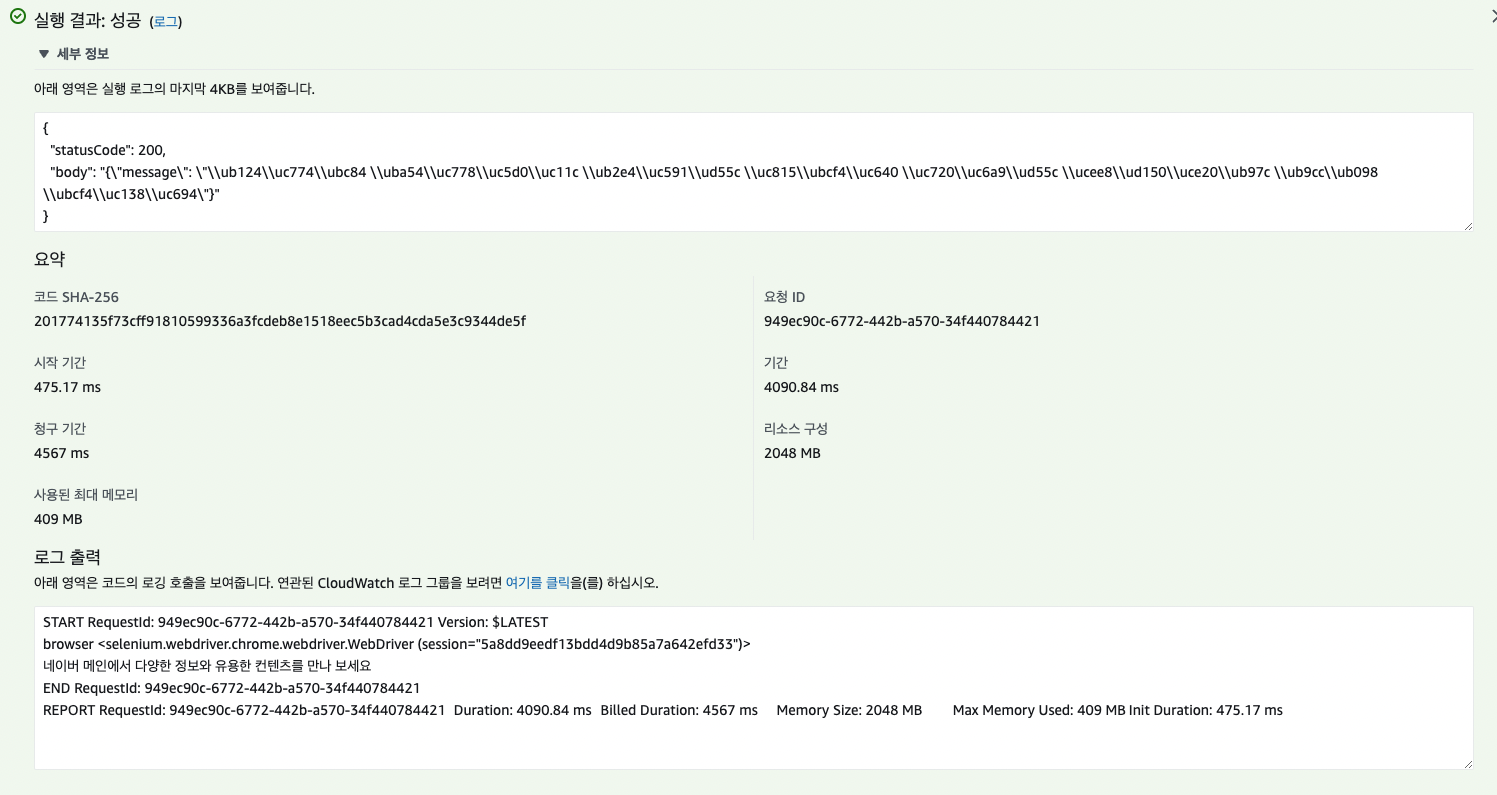
정상적으로 출력되었음을 확인 할 수 있다!!
끝!
참고사항
https://velog.io/@ironkey/AWS-Lambda를-Docker로-구축하기
https://cloudbytes.dev/snippets/run-selenium-in-aws-lambda-for-ui-testing
'aws' 카테고리의 다른 글
| aws 로드밸런서에 대해서 설명하세요. (0) | 2024.05.17 |
|---|---|
| lambda docker 이미지에 mecab 설치 (0) | 2022.12.14 |
| aws codedeploy Could not download bundle at after 3 retries. Server returned codes: 404 'Not Found'; 404 'Not Found'; 404 'Not Found'; 404 'Not Found'. (0) | 2022.06.23 |
| aws cloudfront s3 access denied (0) | 2022.02.10 |
| RDS -> s3 백업 (0) | 2021.06.30 |


