https://static.googleusercontent.com/media/research.google.com/ko//archive/gfs-sosp2003.pdf
요약
GFS는 엄청나게 많은 데이터를 보유해야 하는 구글의 핵심 데이터 스토리지와 구글 검색 엔진을 위해 최적화.
파일들은 64MB로 고정된 청크로 데이터가 추가되거나 읽기 위주의 작업이며, 데이터 유실에 대한 설계를 중심으로 레이턴시가 길더라도 높은 스루풋에 중점을 두었다.
1. Introduction
첫째, 파일 시스템은 저렴한 비용으로 구축된 수백, 수천 대의 스토리지 머신으로 구성되며 비슷한 수의 클라이언트 머신에서 액세스 된다. 일부 구성 요소는 언제든 작동하지 않을 수 있고, 일부는 현재 장애가 발생해도 복구되지 않을 수 있어 지속적인 모니터링, 오류 감지, 내결함성 및 자동 복구 기능이 시스템에 필수적으로 포함되어야 한다.
둘째, 파일 용량은 GB가 흔하도록 커졌다. 수십억개의 개체로 구성된 TB에 달하는 데이터를 작업할 경우 I/O 작업 및 블록 크기와 같은 설계 가정과 매개변수를 재검토해야 한다.
셋째, 파일은 기존 데이터를 덮어쓰는 방식이 아니라 추가하는 방식으로 변경된다.대용량 파일에 대한 이러한 액세스 패턴을 고려할 때, 성능 최적화와 원자성이 보장되면 반대로 데이터 블록 캐싱은 어려워진다.
2. DESIGN OVERVIEW
GFS는 익숙한 파일 시스템 인터페이스를 제공하지만 POSIX와 같은 표준 API를 구현하지않는다. 파일은 디렉터리에서 계층적으로 구성되며 경로명으로 식별된다. 파일 생성, 삭제, 열기, 닫기, 읽기, 쓰기, 스냅샷과 레코드 추가 작업을 지원한다.
2.3 Architecture
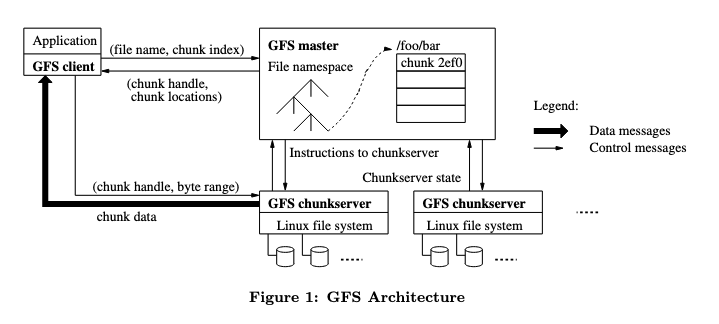
GFS 클러스터는 단일 마스터와 여러 개의 청크 서버로 구성되며 그림 1과 같이 여러 클라이언트에서 액세스가 가능하다.
파일은 고정된 크기의 청크로 나뉘며 각 청크는 청크 생성 시 마스터가 할당하는 변경 불가능하고 전역적으로 고유한 64비트 청크 핸들로 식별된다
master :
마스터는 모든 파일 시스템 메타데이터를 유지 관리한다. 여기에는 네임스페이스, 액세스 제어 정보, 파일에서 청크로의 매핑, 청크의 현재 위치가 포함된다.
또한 청크 가비지 수집, 청크 마이그레이션과 같은 시스템 전반의 활동을 제어하며 마스터는 주기적으로 각 청크 서버와 HeartBeat 메시지로 통신하여 청크 서버에 지시를 내리고 청크 서버의 상태를 수집한다.
client:
클라이언트는 각 애플리케이션에 연결된 GFS 클라이언트 코드는 파일 시스템 API를 구현하고 마스터 및 청크 서버와 통신하여 애플리케이션을 대신하여 데이터를 읽거나 쓴다.
클라이언트는 청크 서버 모든 파일 데이터를 캐시하지 않는다. 캐시를 사용하지 않으면 캐시 일관성 문제를 제거하여 클라이언트와 전체 시스템을 간소화할 수 있기 때문이다. (하지만 클라이언트는 메타데이터를 캐시.)
파일은 고정 크기 청크(fixed-size chunks)로 나뉜다. 각 청크는 불변(immutable)하고 전역적(globally)으로 고유한 64 bit chunk handle에 의해 식별된다.
- 청크 핸들은 청크를 생성할 때 마스터가 할당
- chunkserver는 로컬 디스크에 청크를 리눅스 파일로 저장하고 청크 핸들 및 바이트 범위에서 지정된 청크 데이터를 읽거나 쓴다.
- 신뢰성을 위해 각 청크는 여러 청크 서버에 복제된다.
Metadata
마스터는 세 종류의 메타데이터를 저장한다.
(1) 파일과 청크의 네임 스페이스
(2) 파일과 청크의 매핑 정보
(3) 각 청크 복제본의 위치
모든 메터데이터는 마스터의 메모리에서 유지된다.
네임스페이스와 파일-청크 매핑 정보의 경우 변화(mutation)가 생길 시 마스터가 로깅하면서 유지된다. 이 작업 로그(operation log)는 마스터의 로컬 디스크에 저장되고 원격의 머신에 복제된다.
마스터는 청크 위치 정보를 지속적으로 저장하지 않는다. 대신, 마스터 시작할 때와 청크서버가 클러스터에 들어올 때마다 각 청크 서버에 청크를 묻는다.
2.6.3 Operation Log
- 작업 로그는 중요한 메타데이터 변경 내역 기록이 포함되어 있는데 이것은 GFS의 중심 역할이다.
- 메타데이터의 유일한 지속적인 기록일 뿐만 아니라 동시 동작 순서를 정의하는 논리적 타임라인 역할을 한다.
- 파일 및 청크와 해당 버전은 모두 고유하며 생성된 논리적 시간에 의해 지속적으로 식별된다.
- 작업 로그는 무척이나 중요하기 때문에 안정적으로 저장해야 한다. 따라서 이를 여러 원격 시스템에 복제하고 로컬 및 원격에서 해당 로그 레코드를 디스크에 플러시(flush)한 후에만 클라이언트 작업에 응답한다.
- 마스터는 플러시하기 전에 여러 로그 레코드를 일괄 처리하여 플러시 및 복제가 전체 시스템 처리량에 미치는 영향을 줄인다.
- 마스터는 로그가 특정 크기를 초과할 때마다 상태를 체크포인트(checkpoint)하므로 로컬 디스크에서 최신 체크포인트를 로드(load)한 후 제한된 수의 로그 레코드만 재생하여 복구할 수 있다
2.7 Consistency Model
GFS는 고도로 분산되어 있는 애플리케이션을 잘 지원하면서 동시에 구현이 비교적 간단하고 효율적인 방식으로 유지되는 완환된 일관성 모델을 갖추고 있다.
파일 네임스페이스의 변경(ex. 파일 생성)은 원자적이다. 이것은 전적으로 마스터서버에 의해 수행되며, 네임스페이스 'locking'은 원자성과 정확성을 보증한다. 마스터의 작업 로그는 이러한 작업의 전체 순서를 정한다.
데이터 변화(mutation) 후 파일 영역(file region)의 상태는 변화의 유형, 성공 또는 실패 여부, 동시 변화가 있는지 여부에 따라 달라진다.
3. SYSTEM INTERACTIONS
replica로 인해 모든 서버가 복제본을 가지고 있을때, 데이터가 들어오면 원자성을 위한 순서를 보여준다.

- 클라이언트는 청크에 대한 위치를 마스터에게 질의한다.
- 마스터는 복제본의 identity를 전달한다. 없다면 아무거나 고른다.
- 클라이언트가 모든 복제본에게 데이터를 푸시한다.
- 모든 복제본 푸시가 완료되면, 쓰기 요청을 primary에 요청한다.
- primary는 쓰기 요청을 모든 복제본에게 전달한다. 복제본은 프라이머리가 정한 순서대로 진행한다.
- 작업이 끝나면 primary에게 끝났다고 알려준다.
- primary는 클라이언트에게 완료를 알린다.
3.4 Snapshot
스냅샷은 파일이나 디렉토리 트리의 복사본을 만든다. 마스터가 스냅샷 요청을 받게 되면 먼저 outstanding lease를 revoke한다.
이렇게 하면 어떠한 연속된 쓰기도 lease holder를 찾기 위해 마스터와 교류를 해야 한다. lease가 revoke되거나 만료되면 마스터는 디스크에 작업을 로깅한다.
4.4 Garbage Collection
4.4.1 Mechanism
파일을 지우면 마스터는 이 로그를 남긴다. 파일은 삭제된 시간이 포함된 hidden name으로 renamed 된다. 마스터가 정기적으로 하는 파일 시스템 네임스페이스 스캔에서 3일 이상 지난 hidden filed은 삭제되며, 인메모리 메타데이터도 지워진다.
이와 비슷하게 마스터는 orphaned chunks도 찾는다. 어떤 파일에게서도 접근이 안 되는 청크이다. 마스터의 메타데이터에 없는 청크를 알려주고 지운다.
5.1 고가용성
GFS 클러스터의 수백 대의 서버 중 일부 서버는 특정 시간에 사용할 수 없는 서버가 있습니다. 전체 시스템의 고가용성을 유지하기 위해 빠른 복구와 복제를 통한 고가용성을 유지한다.
5.1.3 Master Replication
- 마스터 상태가 복제된다. Operation log와 checkpoints가 다수의 머신에 복제된다.
- shadow master가 primary master가 다운됐을 때 read-only access를 제공할 수 있다.
- shadow master도 operation log의 복제본을 데이터 구조에 변화를 준다. 프라이머리처럼 시작할 때 청크서버에게 poll하고 그 뒤로는 자주 하지 않지만 청크 복제본과 통신하면서 모니터링한다.
5.2 Data Integrity
- 각 청크서버는 저장된 데이터의 corruption을 탐지하기 위해 checksum을 사용한다.
- 청크는 32비트 체크섬을 갖고 있다.
- 다른 메타데이터처럼 체크섬도 인메모리에 저장되고 유저 데이터와 별도로 저장된다.
- 읽기 작업이 오면 청크서버는 체크섬을 확인한다. 만약 체크섬에서 오류가 있다면 청크서버는 에러를 반환하고 마스터에게 알려준다.
- 요청자는 다른 복제본에서 읽을 것이고 마스터는 다른 복제본을 복사할 것이다. 그 뒤에는 mismatch가 일어난 복제본을 지우라고 청크서버에게 지시한다.
6. 실험
모든 머신은 듀얼 1.4GHz PIII 프로세서, 2GB 메모리, 80GB 5400rpm 디스크 2개, HP 2524 스위치에 대한 100Mbps 전이중 이더넷 연결로 구성됩니다.
19대의 GFS 서버 머신은 모두 하나의 스위치에, 16대의 클라이언트 머신은 모두 다른 스위치에 연결됩니다. 두 스위치는 1Gbps 링크로 연결됩니다.
6.1.1 read
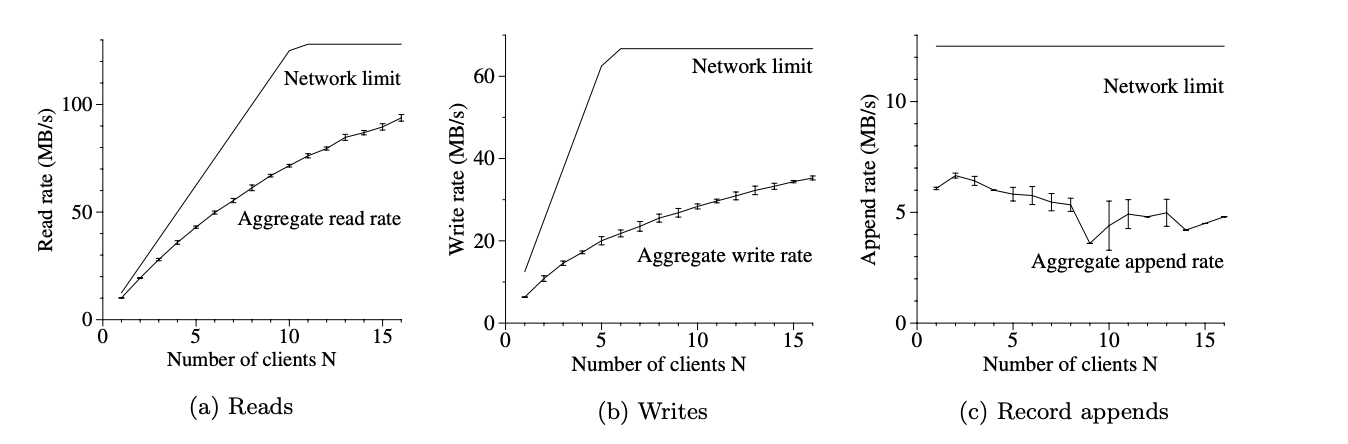
N개의 클라이언트가 파일 시스템에서 동시에 읽습니다.
그림 3(a)는 N 클라이언트에 대한 총 읽기 속도와 이론적 한계를 보여줍니다. (client의 수에 비례해서 좋아지진 않는다.)
6.1.2 writes
N개의 클라이언트가 N개의 서로 다른 파일에 동시에 기록한다.
각 클라이언트는 새 파일에 1GB의 데이터를 1MB씩 연속으로 쓰기 시작한다.
총 쓰기 속도와 이론적 한계는 그림 3(b)에 나와 있다.
한 복제본에서 다른 복제본으로 데이터를 전파하는 데 지연이 발생하면 전체 쓰기 속도가 저하된다.. 클라이언트 수가 증가함에 따라 여러 클라이언트가 동일한 청크 서버에 동시에 쓸 가능성이 높아진다. 또한 각 쓰기에는 세 개의 서로 다른 복제본이 포함되므로 16명의 읽기보다 16명의 쓰기에서 충돌이 발생할 가능성이 더 높다.
6.1.3 record append
그림 3(c)는 레코드 추가 성능을 보여줍니다.
N개의 클라이언트가 단일 파일에 동시에 추가합니다.
애플리케이션은 파일을 동시에 여러 개 생성하는 경향이 있다. 즉, N개의 클라이언트가 수십 개 또는 수백 개의 공유 파일에 동시에 추가하는 경우있다.
따라서 다른 파일의 청크 서버가 사용 중일 때 클라이언트가 한 파일 쓰기를 진행할 수 있기 때문에 실험에서 청크 서버 네트워크 혼잡은 실제로는 큰 문제가 되지 않습니다.
9. CONCLUSIONS
대부분 동시에 추가되고 읽혀지는 대용량 파일에 최적화하며(보통 순차적으로), 표준 파일 시스템 인터페이스를 확장하고 완화하여 전반적인 시스템을 개선했다.
청크 복제를 통해 청크 서버 장애를 견디며, 이러한 장애 복구는 정기적으로 투명하게 손상을 복구하고 손실된 복제본을 가능한 한 빨리 보상하는 새로운 온라인 복구 메커니즘의 동기가 되었다
또한, 시스템의 디스크 수를 고려할 때 너무 흔하게 발생하는 디스크 또는 IDE 하위 시스템 수준에서 데이터 손상을 감지하기 위해 체크섬을 사용한다.
마스터의 파일 시스템 제어, 청크 서버와 클라이언트 간에 직접 전달되는 데이터 전송을 분리하여 데이터 변경 시 기본 복제본에 권한을 위임하는 청클리스 덕분에 공통 작업에 대한 마스터의 개입이 최소화된다.
이를 통해 병목 현상 없이 단순한 중앙 집중식 마스터를 구현할 수 있다.
결론
GFS는 저렴한 기기들로 구성된 장치에서도 파일 시스템의 필수 품질을 보증할수 있다.
'server > system design' 카테고리의 다른 글
| [25 Computer Papers] 3. Bigtable: A Distributed Storage System for Structured Data (0) | 2024.09.11 |
|---|---|
| [25 Computer Papers] 2. Dynamo: Amazon’s Highly Available key-value Store (1) | 2024.09.05 |
| 쿠폰발급 서비스 구축하기 (실험용) (0) | 2022.08.12 |
| 9. netflix (0) | 2022.02.13 |
| 8. 메신져 (slack // facebook messenger // whatapp // kakaotalk) (0) | 2021.10.04 |



