사건의 발단.
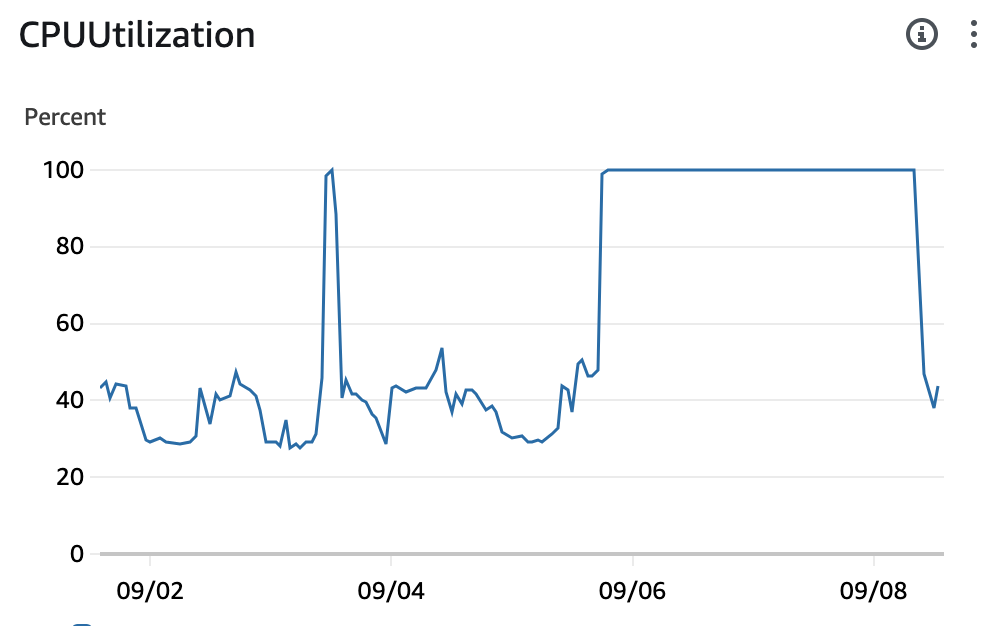
DB CPU가 100%에서 내려오질 않는다. (심지어 락 걸린것도 아님)
로그 테이블을 조회하는 쿼리였는데, 요 몇일 사용자가 늘어서 그런지 집계할때에 자원을 계속 소모해서 하루종일 알림이 울렸다..
일단 쿼리 explain 실행 계획을 데이터를 살펴보았는데 특별히 나쁜 점은 없지만 인덱스를 잘못타고 있었고, 정렬이 필요한 쿼리에서 bitmap scan을 통해 읽은 다음 다시 재정렬하는 과정을 거치고 있었다.(메모리 낭비- work_mem를 잡아먹는 쿼리가 된다.)
일단 급한 CPU사용량은 쿼리 수정과 함께 인덱스를 추가해서 일단락되었지만, 앞으로도 데이터가 계속 쌓이는 로그 테이블이여서 bitmap csan을 seq scan으로 바꾸고 싶었다.
-> Nested Loop (cost=22322.96..23092.16 rows=1 width=108)
Join Filter:
-> Hash Join (cost=22322.96..23058.62 rows=1 width=79)
Hash Cond:
-> HashAggregate (cost=6166.00..6491.15 rows=32515 width=45)
Group Key:
-> Index Scan using (cost=0.42..6066.94 rows=39623 width=37)
Index Cond: ()
-> Hash (cost=16156.68..16156.68 rows=23 width=79)
-> Bitmap Heap Scan on (cost=152.63..16156.68 rows=23 width=79)
Filter: ()
-> Bitmap Index Scan on (cost=0.00..152.62 rows=4271 width=0)
1. 클러스터링 팩터
실행계획이 언제 seq <-> bitmap을 실행하는지는 다음의 사항들로 결정됩니다.
- 데이터 분포 : 데이터 분포가 고르게 되어 있지 않으면, 인덱스 스캔보다 bitmap 스캔이 더 효율적. 블록 단위로 데이터를 읽기 때문에 랜덤 액세스 횟수를 줄입니다.
- 대량의 데이터 : 인덱스 스캔은 각 행을 개별적으로 접근하지만, 비트맵은 블록으로 한꺼번에 읽음.
- correlation 데이터 : 인덱스 칼럼의 correlation값이 낮을때, 즉 인덱스 순서대로 정렬되어 있지 않은 경우 bitmap 스캔이 우선됩니다.
클러스터링은 테이블을 특정 인덱스에 따라 물리적으로 재정렬하는 작업입니다.
!!! 꼭 클러스터링이 좋은것은 아닙니다. 적절하게 사용할때 인덱스보다 더 성능을 발휘할 수 있습니다.
* 클러스터링 좋은 경우
- 인덱스를 사용함으로써 디스크 접근이 줄어들때
- 그룹화된 데이터를 자주 접근할때
seq보다 특정 영역에서는 bitmap이 좋을수도 있지만, 인덱스를 활용한다면 정렬된 상태로 데이터를 원한다면 클러스터링 팩터를 조정함으로써 seq scan으로 변경하는게 속도 면에서 좋은 방법중 하나라고 생각해서 진행되었다.
(단!!! 클러스터링 작업시에는 해당 테이블 잠금으로 인해 사용이 불가능하며, 추가적인 디스크 공간과 메모리가 필요함)
2. 클러스터링 팩터 && n_live_tup
SELECT
schemaname,
tablename,
attname AS column_name,
correlation
FROM
pg_stats이 쿼리는 특정 테이블의 각 컬럼에 대한 클러스터링 팩터를 보여줍니다. correlation 값이 1에 가까울수록 테이블의 물리적 순서가 인덱스 순서와 잘 맞는다는 것을 의미합니다.
이번 문제가 되었던 쿼리에서 쓰이는 칼럼의 값은 -값이였다....즉 인덱스와 정말 순서가 안맞았다는점

두번째로 봐야 하는 칼럼은 n_live_tup, n_dead_tup 이다.
n_live_tup 칼럼으로 해당 정보는 테이블에서 지워지지 않고 살아있는 tuple의 수다.
n_dead_tup 칼럼으로 해당 정보는 테이블에서 지워 졌지만 보이지는 않는 tuple의 수다.
postgres에서는 MVCC로 개발되었기 때문에 삭제시 데이터가 바로 삭제되지 않고, 쓰레기 데이터로 남아있게 된다. (보이지만 않을뿐 어딘가에 디스크를 차지하고 있다.) 이를 청소하기 위해선 vaccum full이 필요하다 (그냥 auto vaccum으로는 삭제 되지 않는다.)
SELECT c.relname AS table_name,
pg_stat_get_live_tuples(c.oid) AS live_tuple,
pg_stat_get_dead_tuples(c.oid) AS dead_tupple
FROM pg_class AS c
JOIN pg_catalog.pg_namespace AS n
ON n.oid = c.relnamespace
WHERE pg_stat_get_live_tuples(c.oid) > 0
AND c.relname NOT LIKE 'pg_%'
ORDER BY dead_tupple DESC;
해당 쿼리에서 사용하는 live / dead의 값이다. 한쪽 테이블에서 수정/갱신이 자주 일어나며, vaccum이 실행되지 않은 것으로 판단할수 있다.

해당 dead_tupple는 vaccum으로 정리가 가능하다. 단!! vaccum full로 진행해야 하며 진행하는 동안 table lock으로 인해 정상적인 서비스는 불가능하므로, 신중하게 선택해서 진행해야 한다.
3. cluster
우리가 흔히 알고 있는 이중화가 아니다!! cluster 명령어는 테이블을 인덱스 정보를 기반으로 물리적으로 재정렬한다. 즉 클러스터링 팩터가 좋게 변경하는 명령어이다. 명령어는 다음과 같은데, 원하는 테이블의 특정 index 이름으로 진행하게 된다.
https://www.postgresql.org/docs/current/sql-cluster.html
CLUSTER [VERBOSE] table_name [ USING index_name ]
CLUSTER ( option [, ...] ) table_name [ USING index_name ]
CLUSTER [VERBOSE]
where option can be one of:
VERBOSE [ boolean ]
주의!!
- 클러스터링 동안은 access exclusive 잠금 상태가 된다. 즉 해당 작업이 끝날때까지 읽기 쓰기 모두 잠금상태가 되므로, 당연히! 운영중인 서비스에 실행하게 되면 흥분되는 실제 상황을 보게 될 것이다!!
- 클러스터링은 일종의 sort 작업과 비슷하여 시스템에서 maintenance_work_mem을 사용하여 동작하게 된다. 작업 전에 해당 메모리를 조정 (적당히 큰값)하는 것을 추천한다.
cluster 명령어를 통해 클러스터팩터 값이 조정되고, 해당 쿼리 실행시 bitmap scan이 seq scan으로 실행계획이 바뀌게 되면서 최종적으로는 sort하는 메모리를 더 아끼고, 속도면에서도 이미 정렬된 상태를 보장되므로, 충분한 속도 향상을 보게 된다.
마무리
* 임시방편으로 cluster를 통해서 해소했지만 근본적인 원인인 원천데이터의수정/삭제가 문제가 될수도 있다라고판단되기 때문에,
나의 경우에는 수정/삭제가 없는 로직 형태로 바꾸는게 가장 베스트라 생각된다. (해당 로직을 다른 부서에서 실행중이라 로직은 변경을 하지 못했다.)
번외
사용하는 쿼리의 데드락이 자주 발생한다면 쿼리를 수정하는것도 하나의 방법이지만, 미리 예방하기 위해서 lock_timeout을 설정해주는것도 하나의 방법이다. (limit을 걸어서 해당 시간이 지나면 deadlock을 감지할수 있다.)
SET lock_timeout TO '2s';
SELECT * FROM your_table WHERE condition;
기본 셋팅을 보는것은 다음과 같다. (보통 0으로 셋팅되어 있어 무제한으로 타임아웃이 없다. 데드락이 발생해도 계속 대기중에 빠진다.)
SELECT name, setting, boot_val
FROM pg_settings
WHERE name = 'lock_timeout';
참고사항들
https://www.postgresql.org/docs/current/sql-cluster.html
PostgreSQL Vacuum에 대한 거의 모든 것 | 우아한형제들 기술블로그 (woowahan.com)
'Database > DB' 카테고리의 다른 글
| postgresql 한글 order by의 기준 (0) | 2023.03.08 |
|---|---|
| postgresql SQL Error [42P10]: ERROR: there is no unique or exclusion constraint matching the ON CONFLICT specification (0) | 2022.11.10 |
| 파티셔닝 실습 - postgresql (0) | 2021.06.22 |
| 파티션 개념 (0) | 2021.06.21 |
| 객체 지향 데이터베이스 (OODB / object-oriented Database) (2) | 2021.06.18 |


