Pub/Sub(발행-구독) 아키텍처는 비동기적 데이터 흐름과 확장성이 필요한 상황에서 주로 사용됩니다.일반적으로 다음의 상황들에 적용하게 됩니다.
- 이벤트 기반 시스템 ( 이메일/푸시 알림 , 데이터 실시간 업데이트)
- 마이크로서비스 간 통신 (주문 처리 시스템, 사용자 인증)
- 스트리밍 데이터 처리
- 데이터 동기화
- 장애 복구 및 재처리 (결제 시스템)
- 확장 가능한 비동기 작업 처리 ( 백그라운드 처리 )
이번 예제에서는 Redis와 Python의 FastAPI를 사용하여 비동기 웹 서버를 만들고 관리하는 설정을 구성할 수 있습니다. 아래는 전체적인 구성 예제입니다.
주요 구성 요소
- FastAPI 웹 서버: 요청을 받아 작업을 Queue에 넣습니다.
- Redis: Queue 역할을 합니다.
- Worker: Redis에서 작업을 가져와 처리합니다.
(queue로 하면 되는데, 왜 pub/sub으로 구현했는지는 마지막 세션의 kafka로의 확장을 위함입니다. 하지만 pub/sub으로 하면 work가 여러개(멀티프로세싱)일 경우 같은 task를 여러번 처리하게 되므로, 중복 처리 로직이 들어가야 하는 단점이 생깁니다. - queue로 하면 중복처리는 안해도 되지만, 확장이 어려워집니다)
참고로 웹서버와 워커 로직의 분리한 이유는 다음과 같습니다.
- 비동기 작업 처리
- 웹 서버는 사용자 요청에 즉각 응답해야 합니다. 하지만 작업(예: 데이터 처리, 파일 업로드 등)이 오래 걸리면 응답이 지연됩니다.
- 워커를 사용하면 웹 서버는 작업을 큐에 넣고 즉시 응답할 수 있으며, 작업은 워커가 처리합니다.
- 시스템 확장성
- 웹 서버와 워커를 분리하면 각각 독립적으로 확장 가능합니다.
- 요청량이 많아지면 웹 서버를 추가.
- 작업량이 많아지면 워커를 추가.
- 이를 통해 효율적인 리소스 사용과 고가용성을 보장합니다.
- 장애 격리
- 작업 중 오류가 발생하더라도 워커만 영향을 받으며, 웹 서버는 계속 동작할 수 있습니다.
1. redis 실행
(로컬 실행이기 때문에 따로 보안 설정은 하지 않았습니다.)
docker-compose 로 레디스를 실행합니다.
version: "3.9"
services:
redis:
image: "redis:alpine"
ports:
- "6379:6379"
2. 웹서버
먼저 도커로 실행된 레디스에 클라이언트를 접속하게 됩니다.
/enqueue : 사용자 요청을 API 호출로 받은 후 redis에 저장
/task/{task_id} : 해당 task의 상태 확인 및 완료 시 redis에서 삭제
from fastapi import FastAPI
import redis
import json
import uuid
app = FastAPI()
# Redis 연결
redis_client = redis.Redis(host="localhost", port=6379, decode_responses=True)
@app.post("/enqueue/")
async def enqueue_task(data: dict):
task_id = str(uuid.uuid4()) # 고유한 Task ID 생성
task_data = {"id": task_id, "data": data, "status": "queued"}
# Redis에 작업 상태 저장 (key: task_id, value: task_data)
redis_client.set(task_id, json.dumps(task_data), ex=3600) # 1시간 후 자동 삭제
# Redis Pub/Sub 채널로 작업 발행
redis_client.publish("task_channel", json.dumps(task_data))
return {"message": "Task published", "task_id": task_id}
@app.get("/task/{task_id}")
async def get_task_status(task_id: str):
# Redis에서 작업 상태 조회
task_data = redis_client.get(task_id)
if task_data:
task = json.loads(task_data)
# 작업 상태를 'completed'로 업데이트
task["status"] = "completed"
redis_client.set(task["id"], json.dumps(task))
# 작업 데이터 삭제
print(f"Deleting task {task['id']} from Redis.")
redis_client.delete(task["id"])
return {"task_id": task["id"], "status": task["status"], "data": task["data"]}
return {"message": "Task not found", "task_id": task_id}
3. worker
워커의 경우 웹서버와 따로 실행되게 됩니다. sub을 통해 계속해서 레디스의 데이터를 처리하게 됩니다.
import redis
import json
redis_client = redis.StrictRedis(host='localhost', port=6379, decode_responses=True)
# 메시지 처리 함수
def process_task(task):
task_data = json.loads(task)
task_id = task_data["id"]
# 중복 확인: 작업 ID가 이미 처리된 Set에 있는지 검사
if redis_client.sismember("processed_tasks", task_id):
print(f"[SKIP] Task {task_id} already processed.")
return
# 작업 처리
print(f"[PROCESSING] Task {task_id} is being processed.")
# 작업 완료 기록
redis_client.sadd("processed_tasks", task_id)
print(f"[DONE] Task {task_id} completed.")
pubsub = redis_client.pubsub()
pubsub.subscribe("task_channel")
print("Worker is running and waiting for tasks...")
# Pub/Sub 메시지 수신 및 처리
for message in pubsub.listen():
if message["type"] == "message":
process_task(message["data"])
전체적인 실행 결과는 다음과 같습니다.
1. 사용자가 /enqueue API를 호출합니다. uuid로 task_id가 발급되며, 해당 task_id를 통해 상태를 확인하게 됩니다.
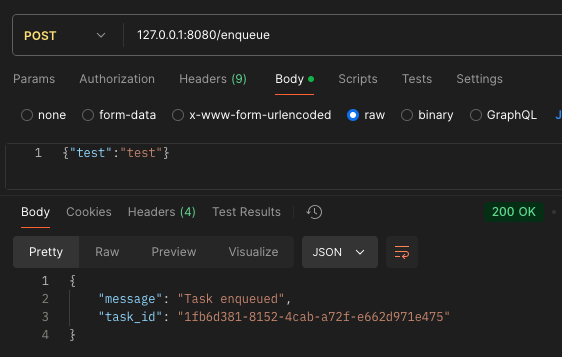
2. worker에서 레디스에 데이터가 들어오면 처리하게 됩니다.

(참고로 다른 워커에서는 해당 task를 받았지만 이미 처리중이므로 skip 됩니다)

3. 클라쪽에서는 /task/{task_id}로 계속해서 완료되었는지 API를 호출하게 됩니다.
(완료가 되었다면 redis에서도 삭제하게 됩니다.)
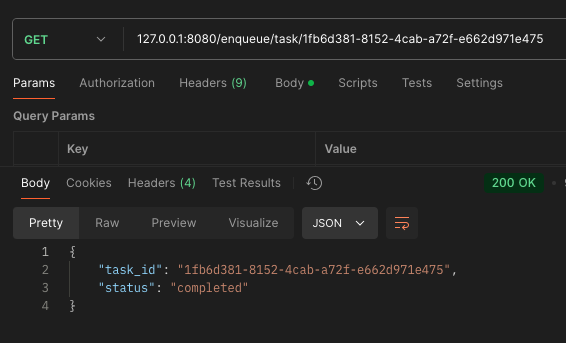
번외
pub/sub을 redis 대신에 Kafka를 사용하는 경우
카프카의 경우 분산 메시징에 특화되어 있습니다. 대규모 서비스를 원한다면 kafka를 사용해야 겠지만, 확장성과 장애 관련 처리를 고려해서 선택해야 합니다.
Redis vs Kafka
| 주요 목적 | 데이터 구조 기반 메시징 및 캐싱 | 분산 메시징 및 로그 스트리밍 |
| Pub/Sub 지원 | 예 | 예 |
| 확장성 | 단일 노드 확장에 한계 | 분산 환경에서 무한 확장 가능 |
| 메시지 영속성 | 선택적 (RDB 또는 AOF 설정) | 기본적으로 영속성 지원 |
| 적합한 사용 사례 | 실시간 알림, 간단한 작업 큐 | 대규모 분산 작업, 데이터 파이프라인 |
위의 코드에서는 redis접속 부분을 카프카로 변경해주면 적용이 가능해집니다.
다음번에는 카프카를 통한 데이터 처리를 포스팅해보겠습니다.
끝
'server > system design' 카테고리의 다른 글
| postgreSQL CDC를 활용한 엘라스틱서치로 데이터 실시간 연동 (0) | 2025.01.14 |
|---|---|
| kafka를 이용한 서버 아키텍처 구현 (0) | 2025.01.09 |
| [25 Computer Papers] 4. Cassandra - A Decentralized Structured Storage System (0) | 2024.09.21 |
| 레디스 트러블 슈팅 (1) | 2024.09.19 |
| [25 Computer Papers] 3. Bigtable: A Distributed Storage System for Structured Data (0) | 2024.09.11 |



