import timeit
arr = [i for i in range(4000 * 4000)]
def slow_sum():
sum = 0
for x in range(4000):
for y in range(4000):
sum += arr[x + 4000 * y]
# print(sum) # 127999992000000
def fast_sum():
sum = 0
for x in range(4000):
for y in range(4000):
sum += arr[x * 4000 + y]
# print(sum) # 127999992000000
timer1 = timeit.Timer('slow_sum()', setup='from __main__ import slow_sum')
t1 = timer1.timeit(number=10)
print(t1 / 10) # 2.9691435980959795
timer2 = timeit.Timer('fast_sum()', setup='from __main__ import fast_sum')
t2 = timer2.timeit(number=10)
print(t2 / 10) # 2.0557019434985705위의 코드에서 단지 [x+4000*y] <--> [x*4000+y] 의 차이만 있을뿐 결국 arr 배열 값을 더한 sum의 값은 같다.
하지만 실행 시간은 30% 차이가 난다. (컴퓨터 마다 다를 수 있다.)
왜 이런 일이 발생할까??
1. Array란 무엇인가?
배열은 "연속적인 메모리 영역"을 차지 하는 동일한 형식의 개체 시퀀이다.
인덱스로 배열의 개별 요소를 찾을 수 있으며, 일반적으로 인덱스는 0부터 시작한다.
"연속적인 메모리 영역"이란 무엇일까? 메모리가 모두 하나의 큰 덩어리로 모여 있다는 것이다.
2. 메모리?

메모리의 각각의 슬롯에는 주소가 정해져 있으며, 순차적으로 증가된다. 즉 메모리의 바이트는 주소로 지정하여 사용된다.
메모리 어딘가에 스택이나 힙에 당신이 선언한 변수가 저장된다.
예를 들어 단일 32비트 부동 소수점을 위한 공간 할당이라면, 32비트 or 4바이트 이므로, 4개 만큼의 공간을 차지하게 된다.
여기에 array는 "연속적인 메모리 영역"은 메모리의 다음 주소에 array의 다음번 인덱스에 해당하는 데이터가 있다는 뜻이 된다.
그러면 위의 코드에서 왜 for문을 통해 잘 가져왔을 데이터가 속도가 느렸던 이유는 무엇일까?
# 이 코드는 왜 더 느릴까?
def slow_sum():
sum = 0
for x in range(4000):
for y in range(4000):
sum += arr[x + 4000 * y]3. CPU 말도 들어봐야 한다.
cpu캐시는 컴퓨터 액세스의 평균 비용 (시간 또는 에너지) 줄이기 위한 메인 메모리이다. 캐시는 작고 빠른 메모리로, 자주 사용되는 주 메모리 위치의 데이터 복사본을 저장 하는 프로세서 코어에 더 가깝습니다 . 대부분의 CPU에는 여러 캐시 수준 (L1, L2, 종종 L3, 드물게는 L4) 의 계층 구조로 되어 있다.

CPU캐시의 역활 중 하나는 cpu 연산에 쓰일 데이터를 미리 가져오는 역활도 한다. 그렇다면 어떻게 쓰일줄 알고 미리 가져올수 있을까?
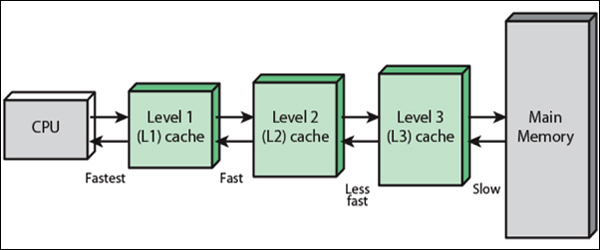
CPU는 L1 cache에 데이터가 있는지 확인하고, 만일 데이터가 없다면 (데이터 미싱 발생!) L2 cache에서 데이터를 확인하고, 없다면 다시 L3 cache에서 데이터를 확인한다. 최종적으로 L3에도 데이터가 없다면 메인 메모리에서 데이터를 로드한다. 이 과정을 cache prefetching (컴퓨터 프로세서가 실제로 필요하기 전에 원래 저장소-메인메모리에서 더 빠른 로컬 메모리로 명령이나 데이터를 가져와 실행 성능을 높이기 위해 사용하는 기술 ) 이라 한다.
물론 L1 -> L2 -> L3로 갈수록 속도는 느려진다. ( 한단계 낮아질수록 100배씩 느려진다. ) 하지만!! 데이터를 가지고 있을 용량은 커지게 된다. 이를 이용해 hardware prefetch 중 스트림버퍼라는 기술을 통해 최적화를 한다.
4. 스트림 버퍼
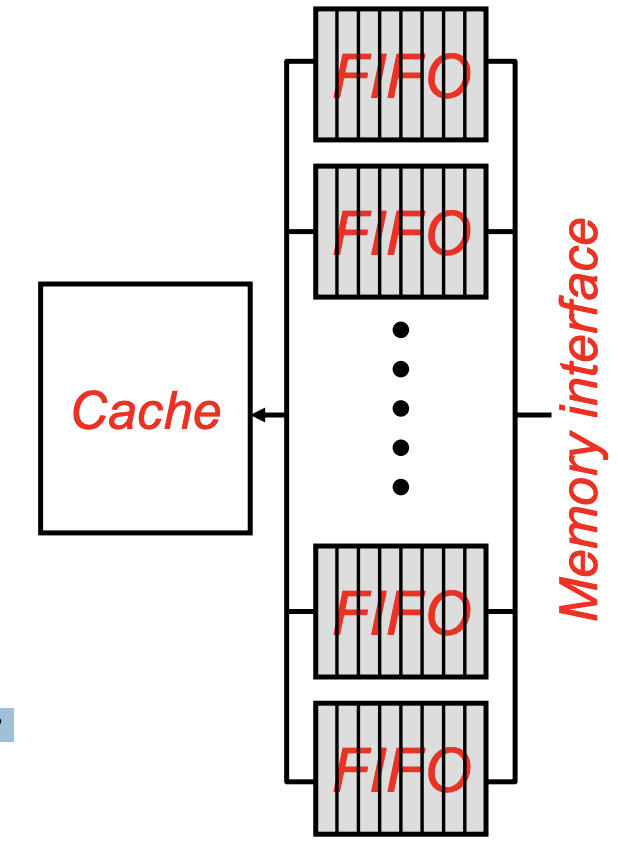
스트림 버퍼 는 사용중인 가장 일반적인 하드웨어 기반 프리 페칭 기술 중 하나로, 프리 페치 메커니즘이 메모리 블록 (예 : A)에서 누락을 감지 할 때마다 누락 된 블록부터 연속 블록을 프리 페치하기 시작하는 스트림을 할당합니다. 스트림 버퍼가 4 개의 블록을 보유 할 수있는 경우, A + 1, A + 2, A + 3, A + 4를 프리 페치하고 할당 된 스트림 버퍼에 보유합니다. 프로세서가 다음에 A + 1을 소비하면 스트림 버퍼에서 프로세서 캐시로 "위로"이동됩니다. 스트림 버퍼의 첫 번째 항목은 이제 A + 2 등이됩니다. 연속적인 블록을 프리 페치하는 이 패턴을 Sequential Prefetching(순차 프리 패치) 라고 합니다. 연속 된 위치를 프리 페치 할 때 주로 사용됩니다. 예를 들어 명령어를 프리 페치 할 때 사용됩니다. 이 메커니즘은 각각 별도의 프리 페치 스트림을 유지하는 여러 '스트림 버퍼'를 추가하여 확장 할 수 있습니다. 각각의 새로운 미스에 대해 새로운 스트림 버퍼가 할당되고 위에서 설명한 것과 유사한 방식으로 작동합니다.
5. 급결론
결국 처음의 코드에서의 속도차이는 데이터를 메모리에서 CPU로 얼마나 빠르게 가져왔는가? 에 대한 시간 차이다. 데이터를 가져오는 방법으로 프리패치를 사용하고(하드웨어 프리패치 혹은 소프트웨어 프리패치), 다양한 최적화를 통해 우리는 마음 편히 코딩을 하고 있다.
docs.microsoft.com/ko-kr/cpp/cpp/arrays-cpp?view=msvc-160
en.wikipedia.org/wiki/CPU_cache
en.wikipedia.org/wiki/Cache_prefetching
compas.cs.stonybrook.edu/~nhonarmand/courses/sp15/cse502/slides/13-prefetch.pdf
'app > python' 카테고리의 다른 글
| pip multiple versions of dependency resolver problem (1) | 2021.06.10 |
|---|---|
| 파이썬 부동소수점 사용시 주의할점 (1) | 2021.06.09 |
| Peephole optimization (0) | 2020.04.09 |
| The internals of Python string interning (0) | 2020.04.01 |
| wsgi를 왜 쓰나요 (3) | 2020.03.31 |


