1. 기능 요구 사항
- 사용자가 입력한 url(원본 도메인)을 특정 도메인을 포함한 형태로 단축 URL로 반환한다.
- 반환된 단축 url 클릭시 원본 URL로 리다이렉트 된다.
- 단축 URL은 일정시간이 지나면 만료되어 삭제된다. 만료 시간은 지정할 수 있어야 한다.
ex) 예시로 tinyurl.com에서 실행한 결과
기존 url
https://www.youtube.com/watch?app=desktop&v=xFPJmk5NQao&ab_channel=siterubix
단축 url
2. 추정 및 제약 사항
2-1 트래픽
해당 시스템은 read가 압도적으로 많을 것이다. 읽기와 쓰기 사이의 비율이 100:1로 가정한다.
- 예상 트래픽 매월 5억 개의 새로운 단축 URL이 100:1로 읽기/쓰기가 발생한다면
- 100 * 5억 = 500억
- Queries per second(1초당 검색 트래픽의 양)
- 5 억 / (30 일 * 24 시간 * 3600 초) = ~ 200 / 초
- 초당 URL 리디렉션
- 100 * 200 = 2000 / 초
2-2 저장 용량 추정
- 모든 URL 단축 요청 (및 관련 단축 링크)을 5 년 동안 저장한다고 가정한다.
- 5 억 * 5 년 * 12 개월 = 300 억
- 각 객체를 500바이트라고 가정한다.
- 300 억 * 500 바이트 = 15TB
- 쓰기 요청의 경우 초당 200 개 총 수신 데이터
- 200 * 500 바이트 = 100KB / s
- 읽기 요청은 쓰기 * 100 초당 총 송신 데이터
- 20000 *500 바이트 = 10MB / s
2-3 메모리 추정
자주 액세스하는 핫 URL 중 일부를 캐시 하려면 저장하는 데 얼마나 많은 메모리가 필요한가?
URL의 20 %가 트래픽의 80 %를 생성한다는 의미인 80-20 규칙을 따르는 경우 이러한 20% 핫 URL을 캐시 가정.
- 초당 2만 개의 요청이 있으므로 하루에 17억 개의 요청이 발생
- 20K * 3600 초 * 24 시간 = ~ 17 억
- 이러한 요청의 20 %를 캐시하려면 170GB의 메모리가 필요
- 0.2 * 17 억 * 500 바이트 = ~ 170GB
주목해야 할 점은 동일한 URL의 중복 요청이 많기 때문에 실제 메모리 사용량이 170GB 미만
3. 시스템 API
REST API 를 통한 등록, 삭제 API 정의
createURL(api_dev_key,
original_url,
custom_alias=None,
user_name=None,
expire_date=None) -> strapi_dev_key (문자열) : 등록된 계정의 API 개발자 키. 사용자의 할당량에 따라 사용자를 제한하는 데 사용
original_url (문자열) : 축약 해야 하는 원본 URL
custom_alias (문자열) : URL에 대한 선택적 사용자 정의 키
user_name (문자열) : 인코딩에 사용할 선택적 사용자 이름
expire_date (문자열) : 단축 URL에 대한 선택적 만료 날짜
return : 문자열
성공시 단축 URL이 반환
deleteURL(api_dev_key, url_key)
4. 데이터베이스 설계
저장할 데이터의 특성에 대한 몇 가지 특징:
- 수십억 개의 기록을 저장
- 서비스에 저장하는 데이터는 작다 (1K 미만)
- 어떤 사용자가 URL을 생성했는지 저장하는 것 외에는 레코드 간에 관계가 없다
- 해당 서비스는 읽기가 많다
데이터베이스 스키마
URL 매핑에 대한 정보를 저장하기위한 테이블과 단축 링크를 만든 사용자 데이터를 위한 테이블 두 개가 필요

어떤 종류의 데이터베이스를 사용해야 하는가?
수십억 개의 행을 저장하며 객체간의 관계를 사용할 필요가 없으므로 DynamoDB , Cassandra 같은 NoSQL 저장소가 더 나은 선택이 된다. NoSQL을 선택하면 확장하기가 더 쉽기 때문이다
5. 기본 시스템 설계 및 알고리즘
여기서 해결하는 문제는 주어진 URL에 대해 짧고 고유 한 키를 생성하는 방법을 제시해야 한다.
TinyURL에서 단축 URL은 https://tinyurl.com/4fyzbta6이다. 이 URL의 마지막 8자는 생성하려는 단축키입니다. 여기에서 두 가지 설루션을 살펴본다.
A. 실제 URL 인코딩 ( base64 )
원본 URL의 고유한 해시(MD5 or sha256등)을 계산할 수 있다. 그다음 해당 해시를 url 인코딩하여 표시할 수 있다. url 인코딩은 base64로 url 인코딩을 사용할 수 있다 ([a-z, A-Z, 0-9, + , /]
base64 인코딩을 사용하면 6 자 길이의 키는 64 ^ 6 = ~ 687억 개의 가능한 문자열이 생성 가능하다
base64 인코딩을 사용하면 8 자 길이의 키는 64 ^ 8 = ~ 281조 개의 가능한 문자열이 생성 가능하다
687억개로 5년간의 요 청수인 수인 300억을 충분히 커버 가능하다.
base 62 의 경우 [a-z, A-Z, 0-9]
- 6자 길이로 62 ^ 6 = 568억
- 8자 길이로 62 ^ 8 = 218조
모듈러 함수를 만든다면 다음과 같다
|
1
2
3
4
5
6
7
8
9
|
def base62(url):
s = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789"
hash_str = ""
while url > 0:
hash_str += s[url%62]
url = url // 62
return hash_str
print(base62("www.naver.com"))
|
cs |
위와 같이 원본URL을 인코딩으로 변환 시 몇 가지 문제점을 가지고 있다
- 여러 사용자가 동일한 URL을 입력하면 동일한 단축 URL을 얻을 수 있다. 이는 시스템상 허용되지 않는다
- URL의 일부가 URL 인코딩 된 경우 어떻게 될까? 예 : http://www.educative.io/distributed.php?id=design 및 http://www.educative.io/distributed.php%3Fid%3Ddesign 은 URL 인코딩을 제외하고 동일해야 한다.
문제에 대한 해결 방법
각 입력 URL에 증가하는 시퀀스 번호를 추가하여 고유하게 만든 해당 시퀀스 번호로 다음 해시를 생성할 수 있다. 또한 이 시퀀스 번호를 데이터베이스에 다시 저장할 필요는 없다. 하지만 증가하는 시퀀스 번호를 계속 추가하게 되면 서비스 성능에도 영향을 미친다.
또 다른 해결책은 사용자ID(고유해야 함)를 short URL에 추가하는 것이다. 그러나 사용자가 로그인하지 않은 경우 사용자에게 고유한 키를 선택하도록 요청해야 한다. 그 후에도 충돌이 발생하면 고유 한 키를 얻을 때까지 키를 계속 생성해야 한다.
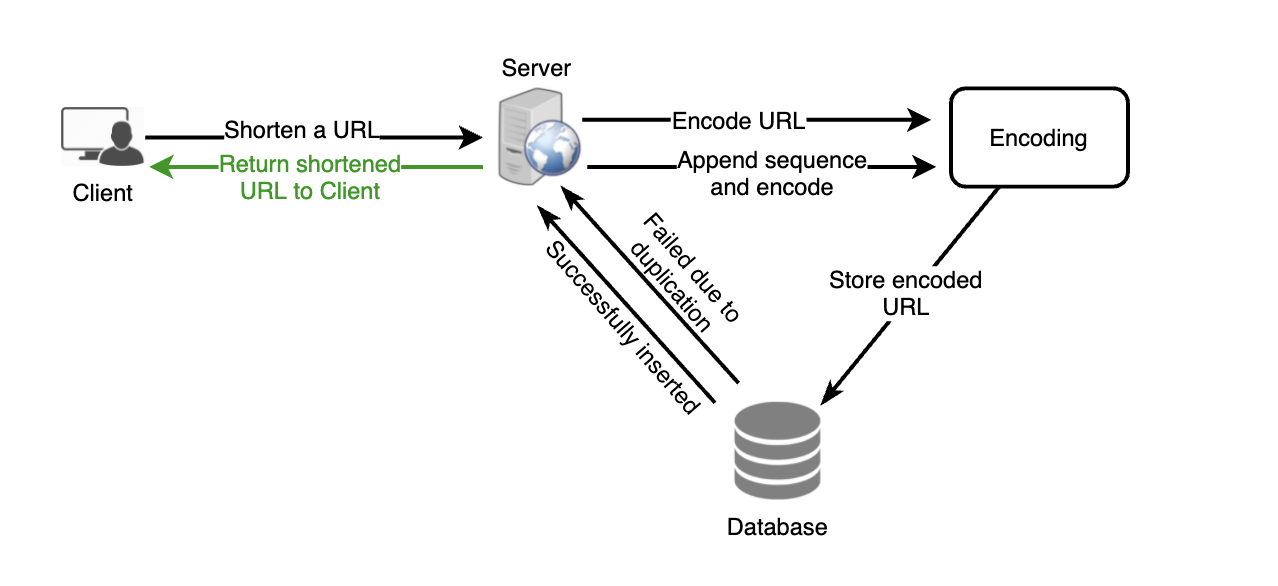
위의 방법의 경우
- 사용자가 원본 URL을 요청
- 서버에서 encode 된 URL을 DB에 저장
- 시퀀스 번호 디비에서 검색 (혹은 캐시 서버가 하나 필요)
- 해당 시퀀스 번호 endcoding
- DB에 저장
DB에 접근이 두 번 혹은 디비 + 캐시 서버 접근이 필요하다.
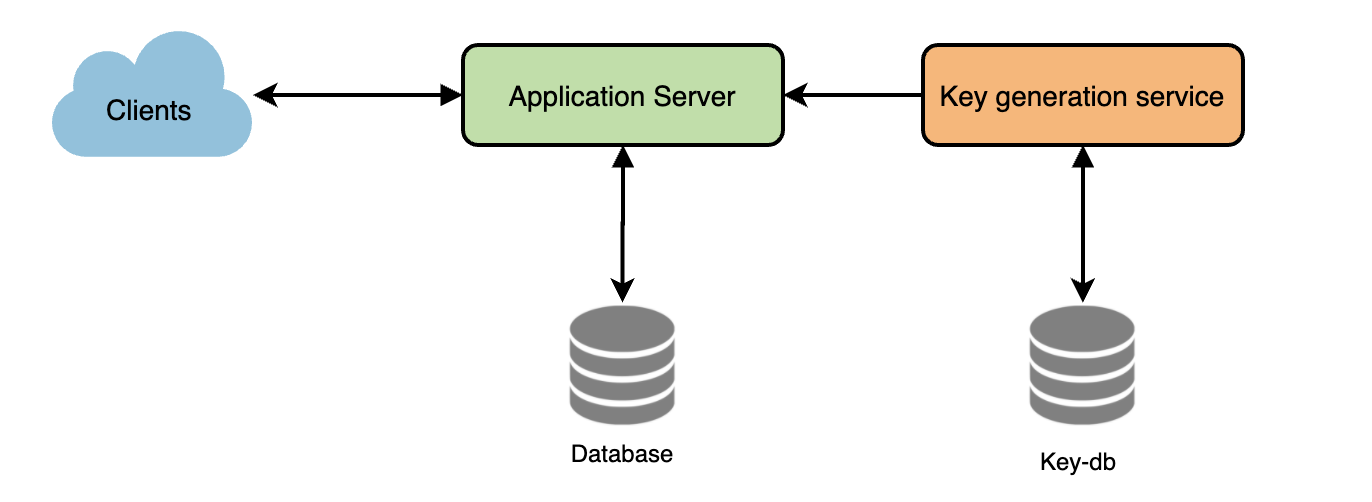
B. Key Generation Service (KGS) 구축
사전에 임의의 문자열 6자를 생성하여 데이터베이스에 저장하는 독립형 키 생성 서비스 (key generation service - KGS)를 가질 수 있다 (키-DB라고 하자). 단축 URL을 생성 요청이 있을 때마다 이미 생성된 키 중 하나를 사용하여 사용한다. 이 접근 방식은 일을 매우 간단하고 빠르게 만들 수 있다. URL을 인코딩하지 않을 뿐만 아니라 중복이나 충돌에 대해 걱정할 필요가 없다.
여러 개의 서버가 있고 KGS는 하나일 경우 두 개 이상의 서버가 동시에 요청 시 동일한 키를 시도하지 않을까?
KGS는 두 개의 테이블을 사용하여 키를 저장한다. 하나는 아직 사용되지 않은 키용이고 다른 하나는 사용된 모든 키용이다. KGS는 서버 중 하나에 키를 제공하는 즉시 사용 된 키 테이블로 이동할 수 있다. KGS는 서버에서 필요할 때마다 신속하게 제공하기 위해 항상 일부 키를 메모리에 보관할 수 있다.
(하나의 테이블에서 칼럼으로 표기하지 않는 이유는 REPEATABLE READ( 트랜잭션이 rollback 될 가능성에 대비해 언두 공간에 백업해두고, 레코드 값을 변경(mvcc). 언두 공간을 통해 트랜잭션 내에서는 동일한 데이터를 제공)까지 방지할 수 있다.)
KGS DB 크기
base64 인코딩을 사용하면 687억 개의 고유한 6자 키를 생성할 수 있다. 하나의 영숫자 문자를 저장하는 데 1 바이트가 필요하다
6 (키다 문자) * 687억 (고유 키) = 412GB.
KGS 단일 실패 지점
이를 해결하기 위해 KGS의 대기 복제본을 만들어야 한다. 기본 서버가 죽을 때마다 대기 서버가 키를 생성하고 제공할 수 있다.
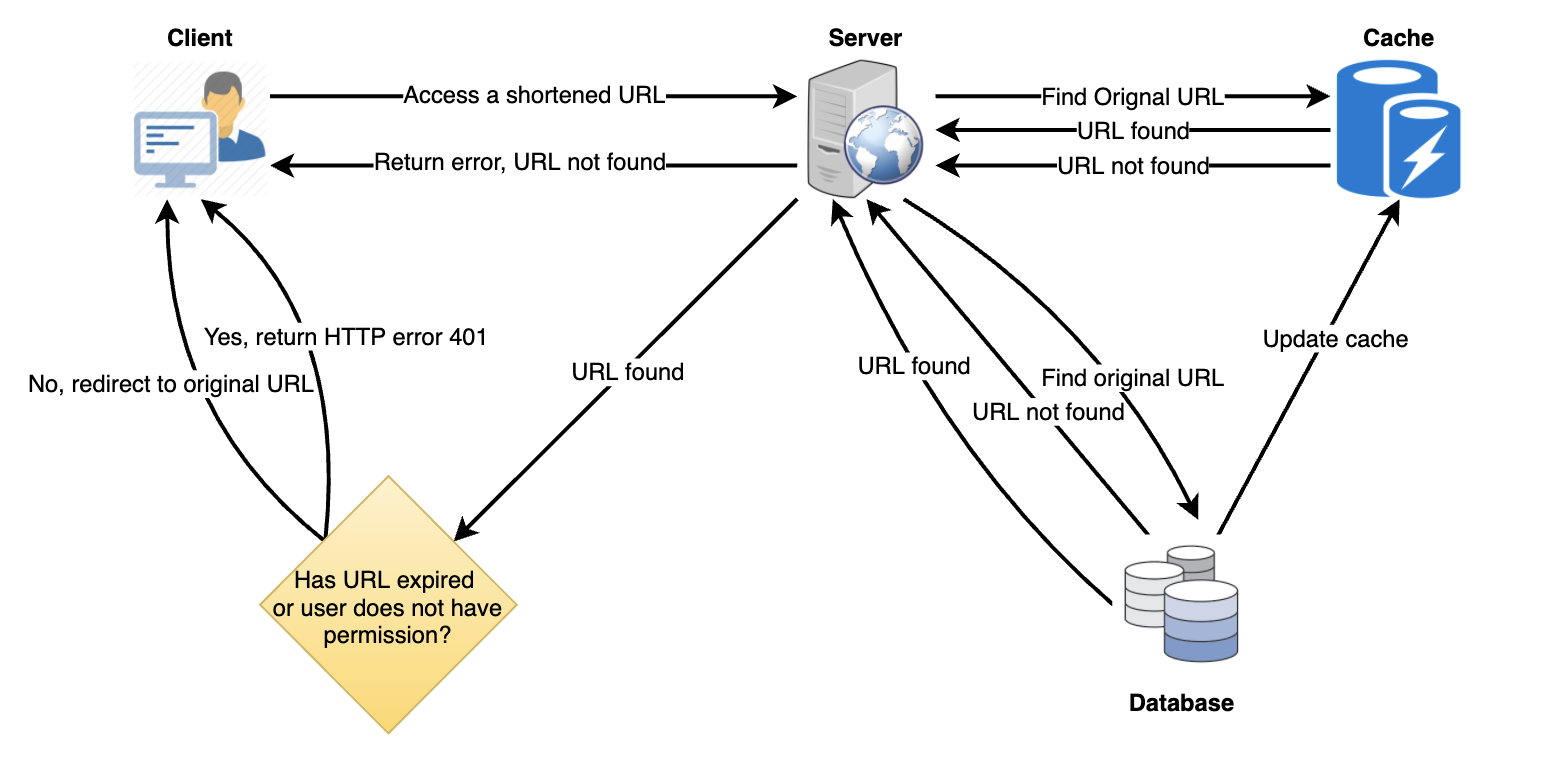
키 조회
데이터베이스에서 키를 검색하여 전체 URL을 얻을 수 있다. DB에 있는 경우 "HTTP 302 리디렉션"상태를 다시 브라우저로 발행하고 요청의 "위치"필드에 저장된 URL을 전달한다. 해당 키가 시스템에 없으면 "HTTP 404 찾을 수 없음" 상태를 발행하거나 사용자를 홈페이지로 다시 리다이렉션 한다
6. 분할 및 복제
DB를 확장하려면 수십억 개의 URL에 대한 정보를 저장할 수 있도록 DB를 분할해야 한다 따라서 데이터를 서로 다른 DB 서버로 분할하여 저장할 수 있는 파티셔닝 체계로 개발해야 한다
A. 범위 기반 분할
해시 키의 첫 글자를 기준으로 별도의 파티션에 URL을 저장할 수 있다. 따라서 우리는 문자 'A'(및 'a')로 시작하는 모든 URL을 한 파티션에 저장하고 문자 'B'로 시작하는 URL을 다른 파티션에 저장하는 식이다. 이 접근 방식을 범위 기반 분할이라고 한다. 자주 사용하지 않는 특정 문자를 하나의 데이터베이스 파티션으로 결합할 수도 있다. 따라서 항상 예측 가능한 방식으로 URL을 저장 / 찾을 수 있도록 정적 분할 체계를 개발해야 한다.
이 접근 방식의 주요 문제점은 DB 서버의 불균형으로 이어질 수 있다 예를 들어 문자 'E'로 시작하는 모든 URL을 DB 파티션에 넣기로 결정했지만 나중에 문자 'E'로 시작하는 URL이 너무 많다는 사실을 뒤늦게 알 수 있다
B. 해시 기반 파티셔닝
이 방식에서는 저장 중인 객체의 해시를 구한다. 구한 해시를 기반으로 사용할 파티션을 계산한다. '키'의 해시 또는 짧은 링크를 사용하여 데이터 개체를 저장하는 파티션을 결정할 수 있다.
해싱 기능은 URL을 다른 파티션에 무작위로 배포한다 (예 : 해싱 기능은 항상 모든 '키'를 [1… 256] 사이의 숫자로 매핑할 수 있음). 이 숫자는 객체를 저장하는 파티션을 나타낸다.
이 접근 방식은 여전히 파티션 과부하로 이어질 수 있으며 이는 Consistent Hashing을 사용하여 해결할 수 있다.
7. 캐시
자주 액세스 하는 URL을 캐시 해야 한다. Memcached와 같은 기성 설루션을 사용할 수 있으며, 각각의 해시와 함께 전체 URL을 저장할 수 있다. 따라서 애플리케이션 서버는 백엔드 스토리지에 도달하기 전에 캐시에 원하는 URL이 있는지 신속하게 확인할 수 있다.
얼마나 많은 캐시 메모리가 있어야 하나?
일일 트래픽의 20%(80:20 법칙)로 시작할 수 있으며 클라이언트의 사용 패턴에 따라 필요한 캐시 서버 수를 조정할 수 있다. 위에서 추정 한대로 일일 트래픽의 20%를 캐시 하려면 170GB의 메모리가 필요하다. 오늘날의 서버는 최대 24TB의 메모리를 가질 수 있으므로 모든 캐시를 하나의 시스템에 쉽게 맞출 수 있다. 또는 두 개의 작은 서버를 사용하여 이러한 모든 핫 URL을 저장할 수 있다.
우리의 요구에 가장 적합한 캐시 제거 정책은 무엇입니까?
캐시가 가득 차서 링크를 최신/최신 URL로 바꾸려면 어떻게 선택을 해야 할까? LRU(최소 최근 사용)는 시스템에 대한 합리적인 정책이 될 수 있다. 이 정책에 따라 가장 최근에 사용하지 않은 URL을 먼저 삭제한다. 우리는 사용할 수 있는 collections.OrderedDict 에 URL 및 해시를 저장하여 최근에 액세스 된 URL을 추적할 수 있다.
효율성을 더욱 높이기 위해 캐싱 서버를 복제하여 부하를 분산해야 한다.
8. 로드밸런서 (LB)
시스템의 세 위치에 로드밸런싱을 추가할 수 있다
- 클라이언트와 애플리케이션 서버 사이
- 애플리케이션 서버와 데이터베이스 서버 사이
- 애플리케이션 서버와 캐시 서버 사이
처음에는 들어오는 요청을 백엔드 서버 간에 균등하게 분배하는 간단한 라운드 로빈(Round) 접근 방식을 사용할 수 있다. 이 LB는 구현이 간단하며 오버 헤드가 발생하지 않는다. 이 접근 방식의 또 다른 이점은 서버가 작동하지 않는 경우 LB가 서버를 순환에서 제거하고 트래픽 전송을 중지한다는 것이다.
Round Robin LB의 문제점은 서버 부하를 고려하지 않는다는 것이다. 결과적으로 서버가 오버 로드되거나 느린 경우 LB는 해당 서버에 대한 새 요청 전송을 중지하지 않는다. 이를 처리하기 위해 주기적으로 백엔드 서버에 부하에 대해 쿼리하고 이에 따라 트래픽을 조정하는보다 지능적인 LB 설루션을 배치할 수 있다.
9. 만료 데이터 삭제
만료된 링크를 계속 검색하여 제거하면 데이터베이스에 큰 부담이 된다. 대신 만료 된 링크를 천천히 제거(lazy delete)를 수행 할 수 있다. 해당 서비스는 만료 된 링크만 삭제되도록 보장한다. 일부 만료 된 링크는 더 오래 지속될수 있지만 사용자에게 반환되지는 않는다.
- 사용자가 만료된 링크에 액세스하려고 할 때마다 링크를 삭제하고 사용자에게 오류를 반환 할 수 있다.
- 별도의 정리 서비스를 주기적으로 실행하여 스토리지 및 캐시에서 만료 된 링크를 제거할 수 있다. 이 서비스는 매우 가볍고 사용자 트래픽이 낮을 것으로 예상되는 경우에만 실행되도록 예약되어야 한다.
- 각 링크에 대한 기본 만료 시간 (예 : 2 년)을 가질 수 있다.
- 만료된 링크를 제거한 후 해시 키를 다시 kgs에 넣어 재사용할 수 있다.

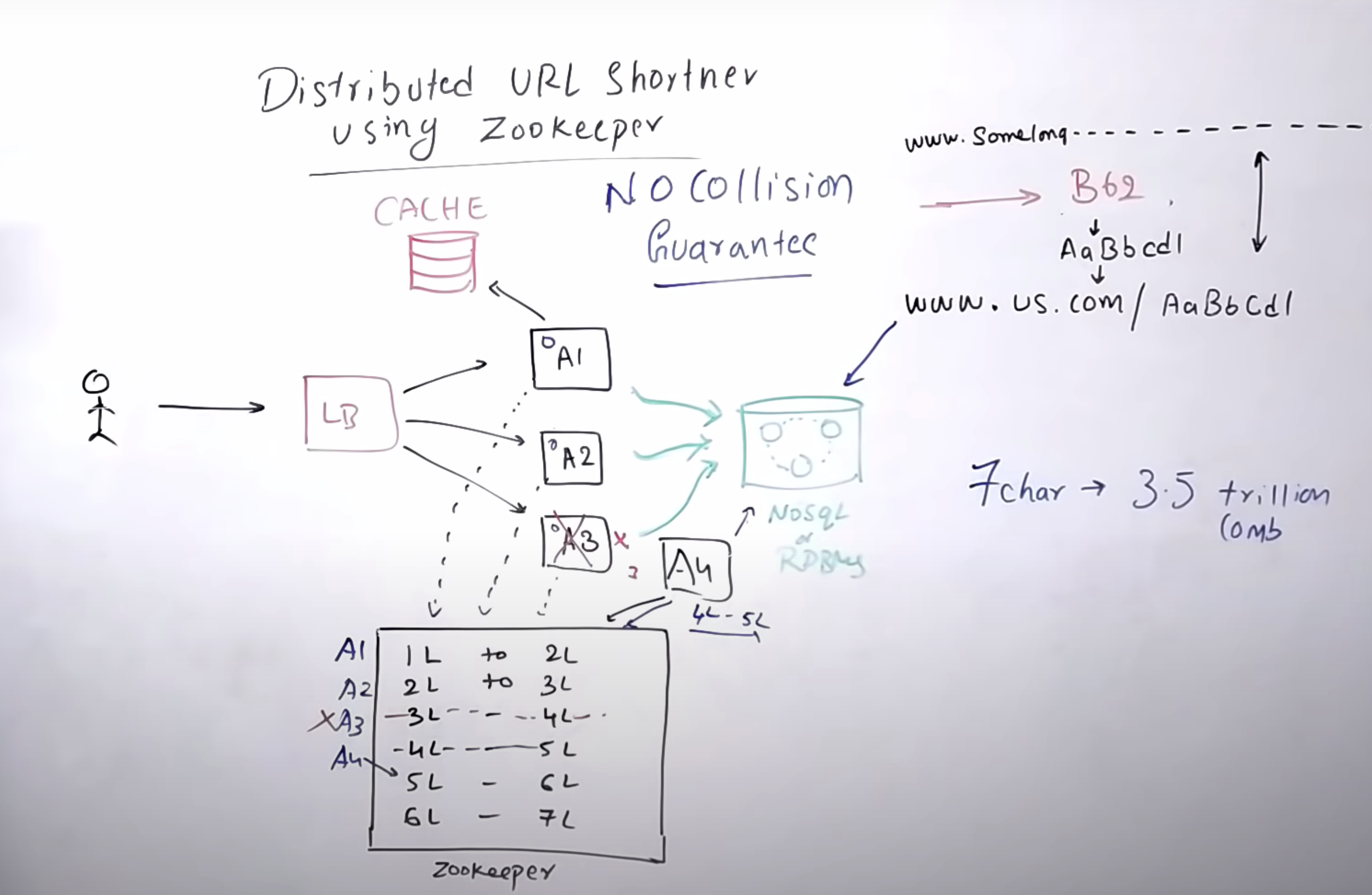
번외) zookerper를 이용한 collision 처리
- zookerper와 같이 동시 병렬이 가능한 시스템으로 미리 hashurl을 계속 만들어둔다.
- hashurl 요청 시 worker에서 DB에 저장 및 캐시 후 삭제한다.
- 빈 worker는 다시 hashurl을 생성한다.
'server > system design' 카테고리의 다른 글
| 5. dropbox // google drive (0) | 2021.07.30 |
|---|---|
| 4. instagram // Flickr // Picasa (0) | 2021.07.23 |
| 3. twitter (0) | 2021.07.21 |
| 2. pastebin ( text storage site ) (0) | 2021.07.17 |
| how to system desgin? (0) | 2021.07.07 |


