1. 기능 요구 사항
- 글 쓰기
- 타임라인 확인
- 트렌드 및 해시태그 리스트
- 검색
2. 추정 및 제약 사항
- 쓰기에 비해 읽기가 많다
- 최종 일관성을 유지해야 한다. 사용자가 팔로워의 트윗을 약간 늦추어도 괜찮다
- 트윗은 140 자로 제한

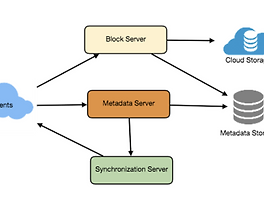
3. 데이터베이스 설계
Redis && DB
기능 요구 사항에 따른 필요 테이블들
- user
- tweet
- follwer
DB 테이블 관계도

필요 쿼리들
- get follwers
- get latest tweets
Twitter 서비스의 기본 아키텍처는 User , Tweet , Followers로 구성된다.
- 사용자 정보는 사용자 테이블에 저장된다
- 사용자가 트윗하면 사용자 ID와 함께 tweet 테이블에 저장된다
- 사용자 테이블은 tweet 테이블과 일대 다 관계를 갖는다.
- 사용자가 다른 사용자를 팔로우하면 Followers Table에 저장되고 Redis도 캐시 한다.
캐시를 위한 Rredis의 키 저장 방법 예시
Redis : <user_id>-tweets : [1, 2, 3, 4,.....]
<user_id>-follower: [1, 2, 3, 4.....] <tweet_id>-tweet: " hello? "
4. 타임라인 설계
- 특정 사용자에 대한 글로벌 tweet 테이블 / Redis에서 모든 tweet을 가져온다.
- 리트윗도 포함되며, 원래 트윗 참조와 함께 트윗으로 리트윗 저장
- 사용자 타임 라인에 표시, 날짜순으로 정렬
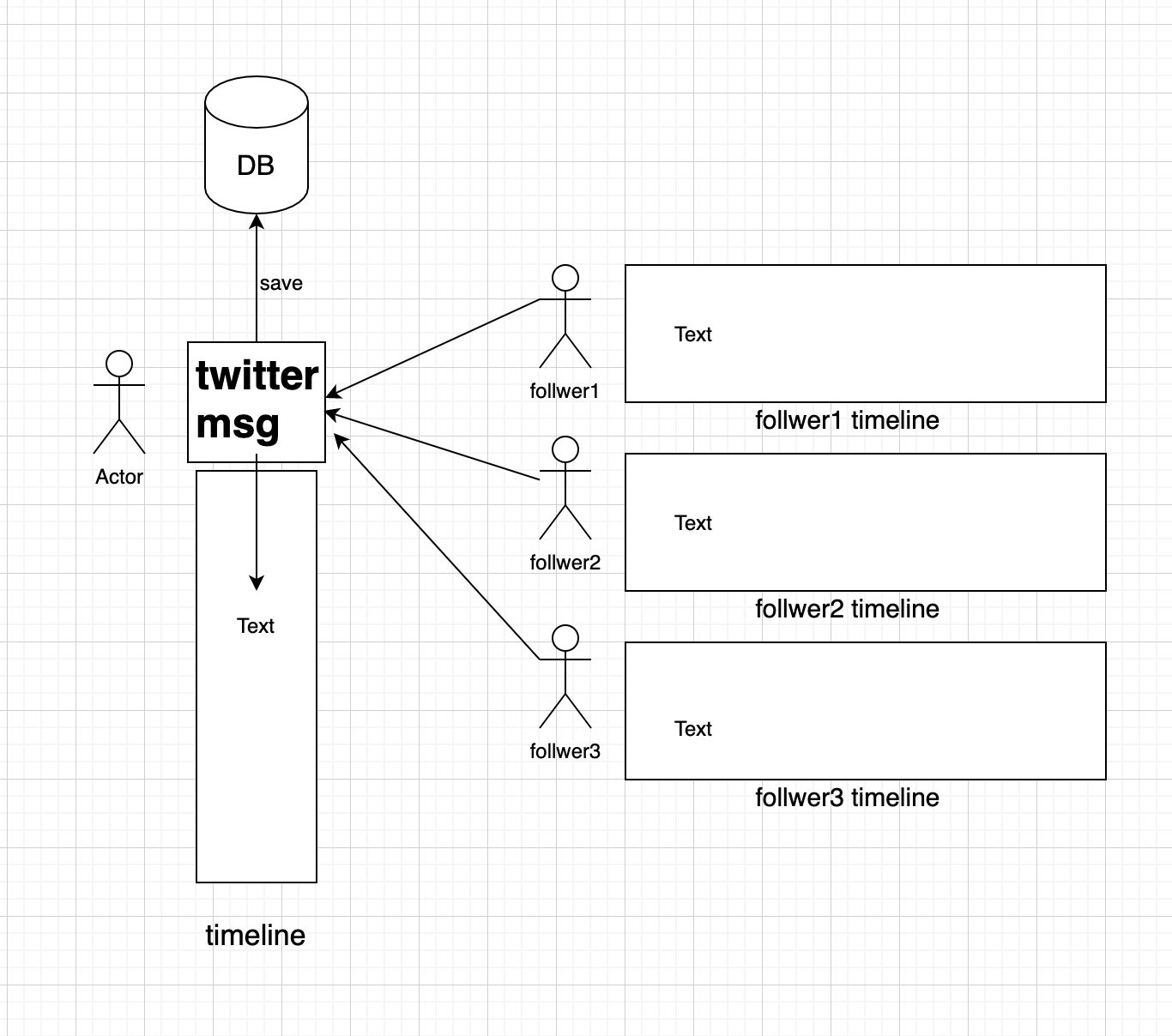
5. 일반 유저의 트윗 전달
일반 유저의 메시지를 작성한 경우 다음과 같은 흐름으로 작동한다.
- 작성한 메시지는 DB에 저장된다.
- 자신의 타임라인에 기록된다. (Redis) 바로 갱신함
- 팔로워들의 타임라인에 기록된다. (Redis) 바로 갱신함
간단한 트윗의 흐름
- 사용자 A 트윗
- Load Balancer를 통해 트윗이 백엔드 서버로 전송된다.
- 서버는 DB / redis에 트윗을 저장한다
- 서버는 캐시에서 사용자 A를 따르는 모든 사용자를 가져온다
- 서버 노드는 이 트윗을 팔로워의 redis 내 타임 라인에 저장한다
- 결국 사용자 A의 모든 팔로워는 타임 라인에서 사용자 A의 트윗을 보게 된다
유명인의 경우 수많은 팔로워들에게 메시지를 전달해야 한다. 이는 기존의 캐시 방식으로 활용할 수 없어 다른 방법으로 해결해야 한다.
수천만의 팔로워를 가진 유명인의 경우 (fanout ← 트위터에서 명칭 한 시스템 이름)
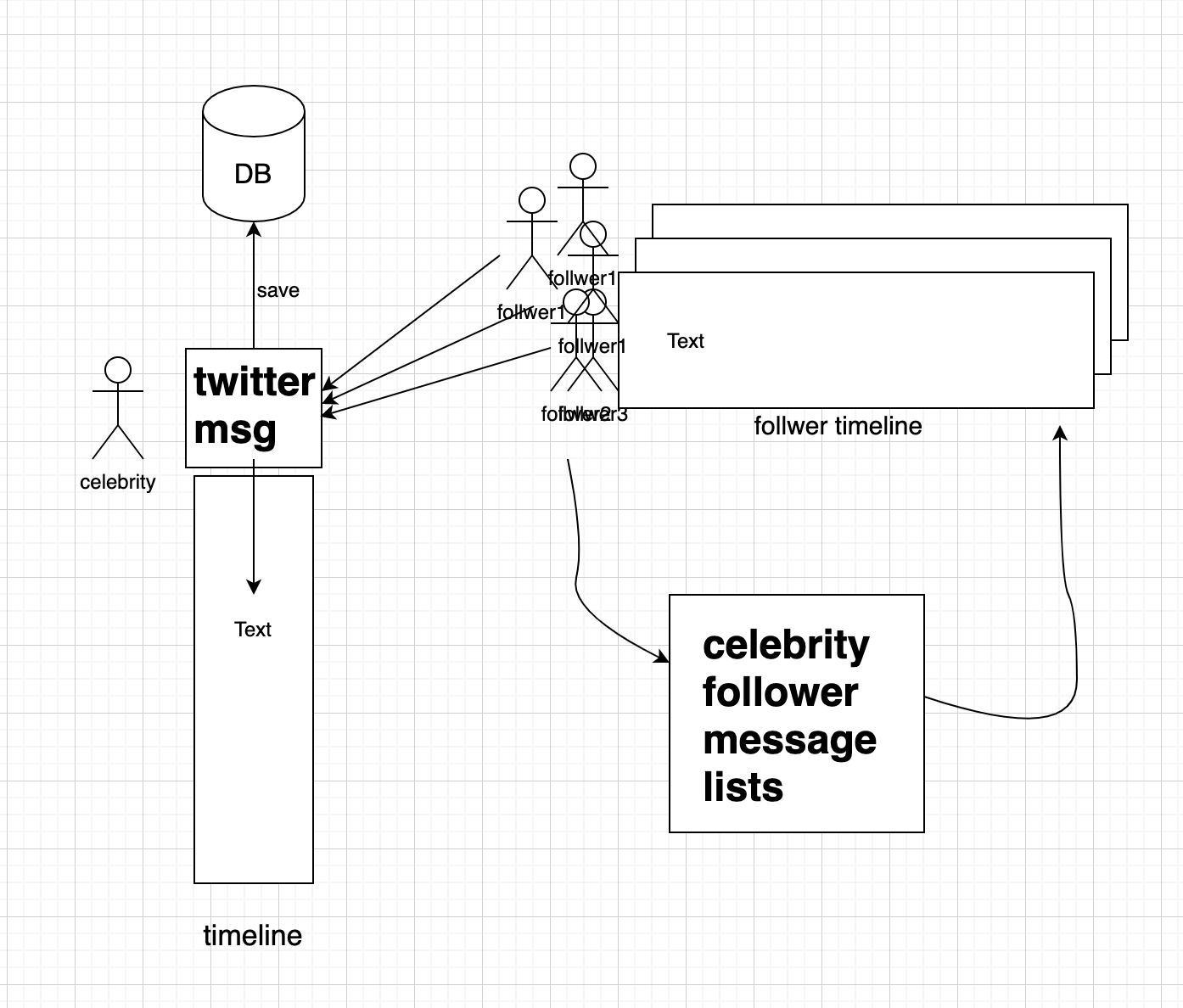
수천만의 redis 메모리를 바로 작업할 수가 없다. 메모리 부족 문제와 함께 누군가는 지연 현상이 있기 때문이다.
- 유명인들만의 메시지를 담은 Redis서버가 있고
- 유명인이 메시지를 작성하면 1번의 redis서버로 저장된다.
- 나의 타임라인 갱신 시 1번의 redis서버에 내가 팔로우하고 있는 유명인의 메시지가 있는지 확인하고
- 나의 타임라인을 업데이트해준다. 바로 갱신하지 않음
유명인의 트윗 흐름
- 유명인 트윗을 제외한 모든 사람과 함께 사용자 A의 사전 계산된 홈 타임 라인
- 사용자 A가 타임 라인에 액세스 하면 그의 트윗 피드가 로드 시간에 유명인 트윗과 병합된다.
- 모든 사용자는 유명인 목록을 매핑하고 요청이 도착하면 런타임에 트윗을 혼합하고 캐시 한다.
15 일 이상 시스템에 로그인하지 않은 비활성 사용자에 대해서는 타임 라인을 계산하지 않는다!!! (실제로 이렇게 작동한다)
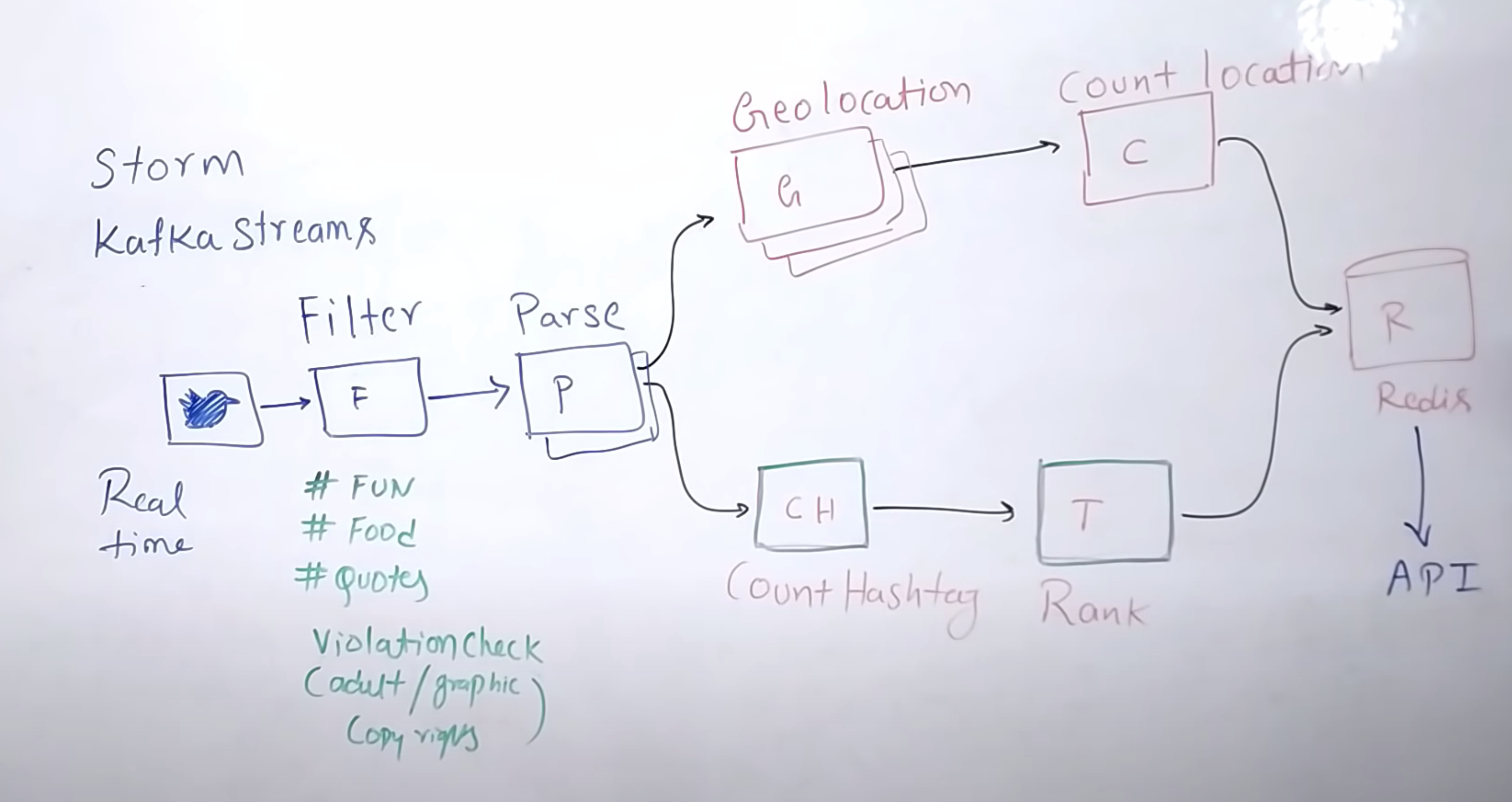
6. 트렌드 및 hashtag 반영
- 카프카 스트림을 사용한다.
- 트윗의 특정 단어 및 해시태그를 필터링/파싱 한다.
- 트윗의 지역 정보가 있을 경우 redis 서버에 저장한다
- 트윗의 특정 단어와 해시태그를 카운팅 하여 랭킹 서버에 반영한다.
- 사용자는 API로 redis에 정보를 요청한다.
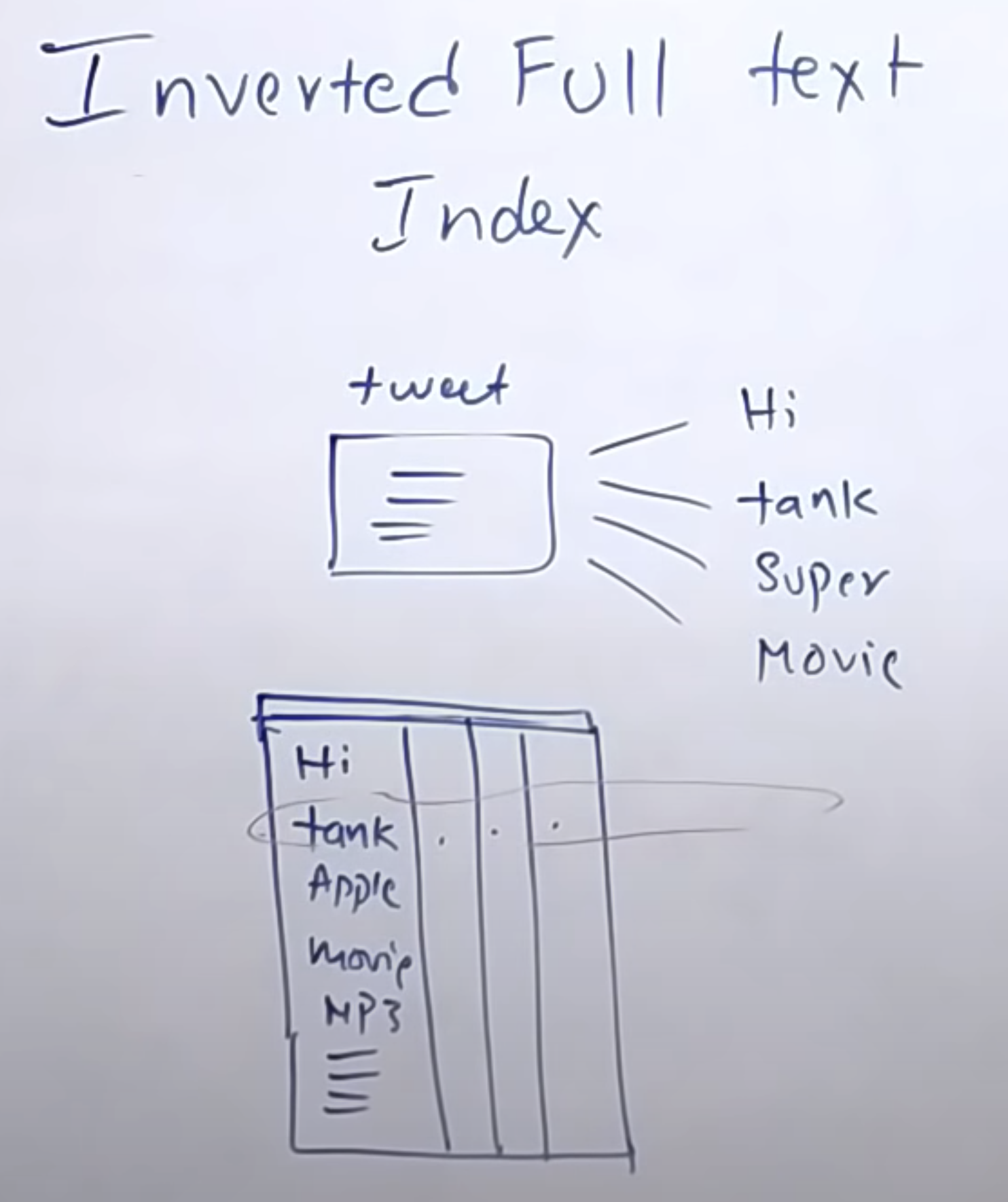
7. search (early bird)
full text 검색이 가능한 DB 사용 ( elasticsearch )
- 트윗의 단어별로 필터링한다.
- 기존 elasticsearch에 저장된 단어에 트윗의 id를 저장한다.
많이 검색되는 단어들은 redis 서버에 저장한다.
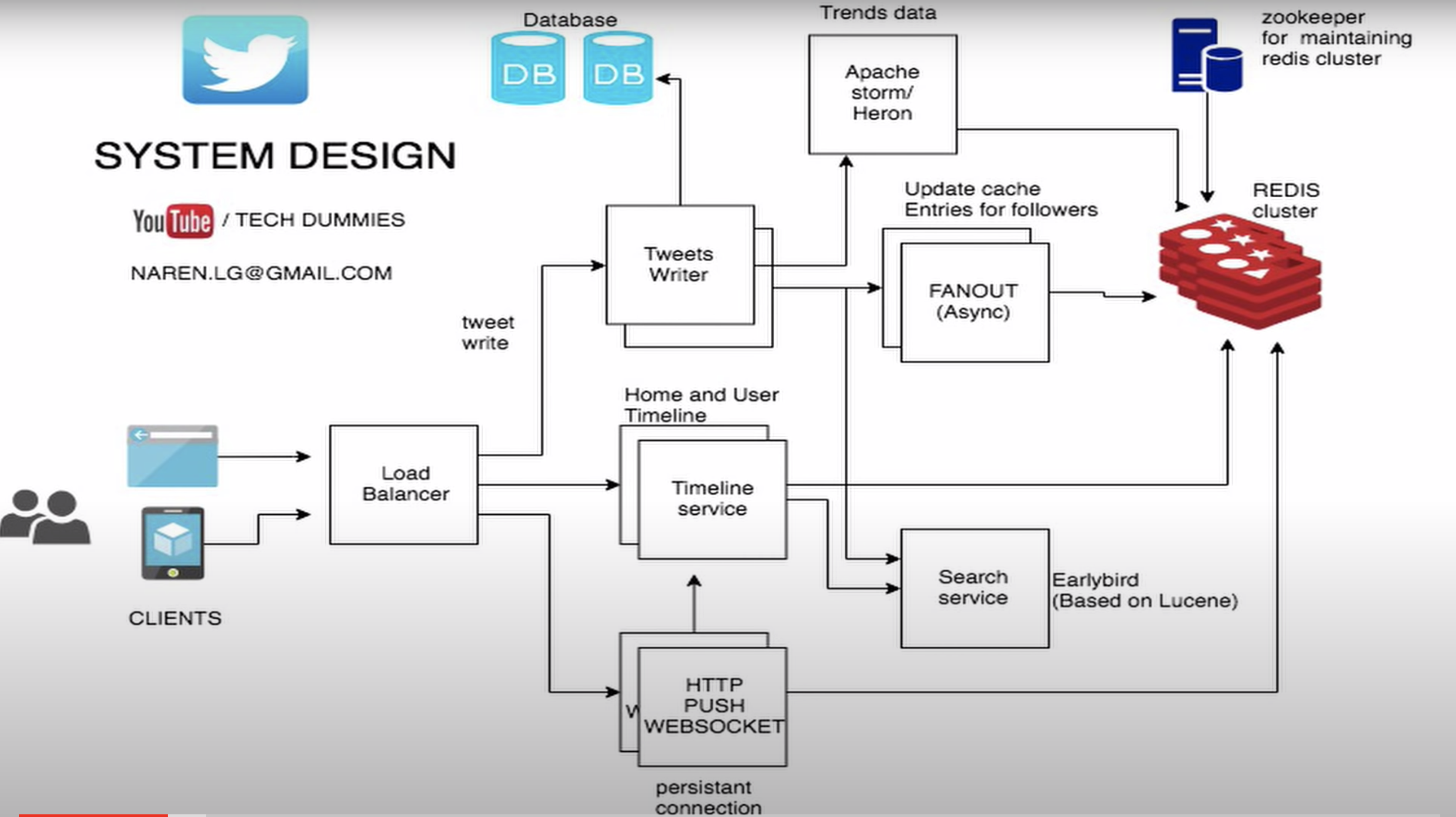
트위터에서 밝힌 실제 시스템 흐름도
참조
https://www.youtube.com/watch?v=wYk0xPP_P_8&ab_channel=TechDummiesNarendraL
https://www.youtube.com/watch?v=J5auCY4ajK8&ab_channel=Parleys
https://blog.pankajtanwar.in/how-twitter-stores-500m-tweets-a-day-1
'server > system design' 카테고리의 다른 글
| 5. dropbox // google drive (0) | 2021.07.30 |
|---|---|
| 4. instagram // Flickr // Picasa (0) | 2021.07.23 |
| 2. pastebin ( text storage site ) (0) | 2021.07.17 |
| 1. TinyURL // bitly (URL shortening service) (0) | 2021.07.09 |
| how to system desgin? (0) | 2021.07.07 |