3줄 요약
SPLADE를 사용하면 fine-tuning 필요 없이 더 빠르고 정확한 검색이 가능합니다.
하지만 기존 성능에 비해 크게 향상은 되지 않고 잘못된 semantic 검색도 야기됩니다.
Abstract
문서와 쿼리에 대한 희소 표현을 학습하는 것에 대한 관심이 높아지고 있다. 명시적 희소성 정규화와 용어 가중치에 대한 새로운 랭커를 제시하여 고도로 희소한 표현과 비교하여 경쟁력 있는 결과를 이끌어낼수 있다.
introduction
SPLADE는 효율적인 문서 확장을 수행하며, 고밀도 모델을 위한 복잡한 훈련 파이프라인에 대해 경쟁력 있는 결과를 보여준다.
희소 정규화를 제어하여 효율성(부동 소수점 연산 횟수)과 효과 사이의 균형에 영향을 줄 수 있는 방법을 보여줍니다.
RELATED WORKS

- 중요한 용어를 강조하여 각 용어에 가중치를 부여하는 모델로 비정보 콘텐츠의 대부분을 폐기하는 모델 (필요 없는 정보는 버려서 중요한 단어를 통해 랭킹을 계산한다.)
- 형태소 분석 추가하여 정형화한다. (legs -> leg)
3. SPARSE LEXICAL REPRESENTATIONS FOR FIRST-STAGE RANKING
1. 문서를 토큰화 후 해당 값을 BERT에 입력

2. 하위 토큰(예: 'digit', 'calculation', 'dog')의 임베딩은 전체 어휘(|V|=30522 - 전체 단어)로 다시 투영
3. 각 토큰별 벡터는 합산되고 로그 활성화를 적용하여 단일 용어의 가중치로 변환됨
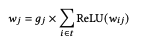
4. 스칼라 곱(dot product)로 랭킹 점수를 획득
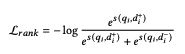
conclusion
최근 BERT 기반의 고밀도 검색이 1단계 검색에서 우월성을 입증하면서 기존 sparse 모델의 경쟁력에 의문이 제기되고 있다. 이 연구에서는 쿼리/문서 확장을 재검토하는 sparse 모델인 SPLADE를 제안했다.
SPLADE는 최신 고밀도 검색 모델과 경쟁할 수 있고, 훈련 절차가 간단하며, 정규화를 통해 희소성/FLOPS를 명시적으로 제어할 수 있고, 역 인덱스에서 작동할 수 있다는 점에서 초기 검색에 매우 매력적인 후보이다.
끝! (근데, naver에서 모델을 만들었는데, 유럽에서 만들어서 한글이 지원 안됨....ㅜㅡㅜ)
참고
https://www.youtube.com/watch?v=OvVajh6yPEg
https://www.youtube.com/watch?v=0FQ2WmM0t3w
'ML > 인공지능' 카테고리의 다른 글
| [논문 리뷰] RoBERTa: A Robustly Optimized BERT Pretraining Approach (0) | 2024.05.14 |
|---|---|
| [논문 리뷰]ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT (1) | 2024.04.07 |
| [논문 리뷰] T-RAG: LESSONS FROM THE LLM TRENCHES (0) | 2024.03.30 |
| [사내 해커톤] ocr + gpt를 이용한 식품 성분 분석 및 추천 (0) | 2024.03.28 |
| [사내 해커톤] Stable Diffusion을 이용한 영상 가공 (0) | 2024.02.25 |


