요약
re-ranking은 colbert를 사용하자.
ABSTRACT
정보검색(IR)에서 문서 랭킹을 위한 언어 모델(LM)은 fine-tuning을 통해 빠르게 성장하고 있다. 더욱 효율적인 검색을 위해 LM(특히, BERT)을 적용하는 새로운 랭킹 모델인 ColBERT를 소개한다.
introduction

ELMo 및 BERT는 사전 학습된 심층 언어 모델(LM)을 미세 조정하여 관련성을 추정하는 접근 방식이 최근에 등장했다.
하지만 BERT 기반 모델은 이전 모델보다 100-1000배 더 계산 비용이 많이 들며, 일부 모델 또한 저렴하지도 않다

BERT는 검색 정밀도를 크게 개선했지만, GPU를 사용하더라도 지연 시간을 최대 수만 밀리초까지 증가시킨다. 쿼리 응답 시간이 100밀리초만 증가해도 사용자 경험에 영향을 미치고 심지어 수익이 현저히 감소하는 것으로 알려져 있다.
이 문제를 해결하기 위해 최근 자연어 이해(NLU) 기술을 사용하여 BM25와 같은 기존 검색 모델을 보강하는 연구되었지만 접근 방식은 지연 시간을 성공적으로 줄이기는 하지만, 일반적으로 BERT에 비해 정밀도가 상당히 떨어진다
IR에서 효율성과 문맥화를 조화시키기 위해, BERT보다 문맥화된 후기 상호작용에 기반한 순위 모델인 ColBERT를 제안한다. query와 document가 두 세트의 컨텍스트 임베딩으로 개별적으로 인코딩되고, 두 세트 간의 가지 치기 계산을 통해 모든 후보를 평가하지 않고도 순위를 매길 수 있다
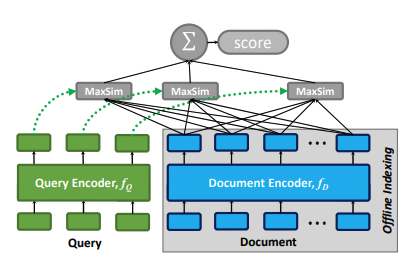
그림 2는 제안한 상호작용 접근 방식을 기존의 신경 매칭 패러다임과 비교 그림이다.
(a)는 representation-focused ranker를 보여주는데, 이 랭커는 q에 대한 임베딩과 d에 대한 임베딩을 독립적으로 계산하고 두 벡터 간의 관련성을 단일 유사성 점수로 추정한다. 오프라인에서도 문서를 미리 임베딩이 가능하다.
(b)는 interaction-focused ranker 시각화이다. q와 d를 개별 임베딩으로 요약하는 대신, q와 d에 걸쳐 단어 및 구문 수준의 관계를 모델링하고 심층 신경망(예: CNN/MLP)을 사용하여 일치시킨다. 신경망에 q와 d에 걸쳐 모든 단어 쌍 간의 유사성을 반영하는 상호작용 행렬에 대한 값으로 추정합니다. CNN / mlp 통해서 학습.
(c)는 BERT의 트랜스포머 아키텍처에서와 같이 단어 간 상호작용은 물론 q와 d에 모든 상호작용을 동시에 모델링한다. 높은 성능을 보이지만 computation cost가 높은 문제점이 있다.
(d)는 Late interaction = interaction + representation 을 합친 방식으로 모든 쿼리 임베딩과 모든 문서의 임베딩을 maxsim(예: 코사인 유사성)을 계산하는 MaxSim 연산자를 통해 상호 작용하며, 이러한 연산자의 스칼라 출력은 쿼리 용어 전체에 걸쳐 합산된다. 이 패러다임은 ColBERT가 문서 인코딩 비용을 오프라인으로 전환하여 검색 호율화를 할수 있다.
또한, ColBERT는 벡터 유사성 검색 인덱스를 활용하여 대규모 문서 컬렉션에서 직접 상위 k개의 결과를 검색할 수 있으므로 검색 결과의 순위만 재조정하는 모델에 비해 re-rank을 크게 향상시킬 수 있다
2. RELATED WORK
3.2 ery & Document Encoders
query encoder
- bert 기반의 word piece tokens 생성 후 [CLS] 뒤에 [Q] 토큰 배치
- 새로운 CNN으로 확장 후 L2 norm을 통해 정규화

document encoder
- [CLS] 뒤에 [Q] 토큰 배치
- [mask] 토큰은 추가하지 않음
- 새로운 CNN으로 확장 후 L2 norm을 통해 정규화
- 문장 부호를 제거해서 임베딩 수 줄임
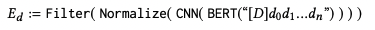
3.3 Late Interaction
- cosine similarity or squared L2 distince 사용
- end to end 검색일때 각 문서에 대해 점수를 생성 한 후 pairwise softmax cross-entropy loss로 최적화
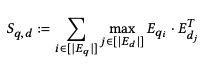
3.4 Offline Indexing: Computing & Storing Document Embeddings
- text preprocessing : bert tokenization으로 미리 인덱싱
- length-based bucketing : 문서중 최대 길이에 맞게 padding 해둠 (계산시 용이)
3.5 Top-k Re-ranking with ColBERT
1. top k개의 문서를 doc를 메모리에 로딩
2. query q에 대한 임베딩계산 (offline index에서 사용한 BERT로 연산)
3. 각 문서에 대한 dot(Eq, D) 계산
- max pool을 통한 (CNN에서 pooling시 최대 값을 선택)
4. summation을 통해서 스코어 계산 및 정렬
* 이미 계산된 임베딩에 대한 연산을 수행하기 때문에 (앞써 offline에서 문서에 대한 임베딩은 수행) 매우 저렴하고 빠름
3.6 End-to-end Top-k Retrieval with ColBERT
1. faiss를 이용해서 vecor similarity data structure 계산 (임베딩 을 미리 인덱싱됨)
2. query q에 대한 임베딩 계산
3. faiss 인덱싱을 통해 빠르게 top k개를 얻을수 있음
4. top k ranking 수행
4. EXPERIMENTAL EVALUATION
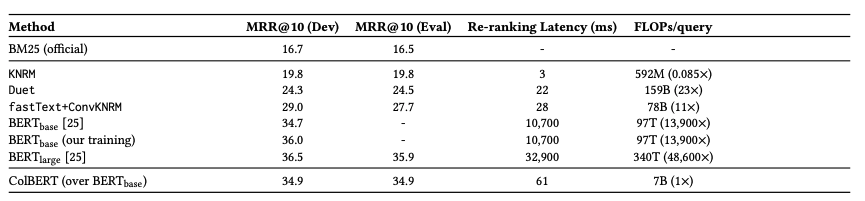
bert와 비슷한 성과가 나오지만, latency는170배, FLOPs/query는 13900배의 차이가 난다. 연산시 GPU로 전송하는 시간에서의 지연시간과 데이터양에 따른 것으로 예측되며, 텍스트 전처리 부분을 병렬처리 하는것이 성능에 가장 큰 영향을 미쳤다고 예측된다.
참고
https://arxiv.org/pdf/2004.12832.pdf
https://www.youtube.com/watch?v=5mynfZA2t7U
https://pangyoalto.com/colbertv1-2-review/
'ML > 인공지능' 카테고리의 다른 글
| [논문 리뷰] RoBERTa: A Robustly Optimized BERT Pretraining Approach (0) | 2024.05.14 |
|---|---|
| [논문 리뷰] SPLADE: Sparse Lexical and Expansion Modelfor First Stage Ranking (0) | 2024.04.09 |
| [논문 리뷰] T-RAG: LESSONS FROM THE LLM TRENCHES (0) | 2024.03.30 |
| [사내 해커톤] ocr + gpt를 이용한 식품 성분 분석 및 추천 (0) | 2024.03.28 |
| [사내 해커톤] Stable Diffusion을 이용한 영상 가공 (0) | 2024.02.25 |


