https://www.youtube.com/watch?v=TYkQB2LZS3E
그냥 멍하니 유툽을 보다가 궁금해졌다.
위에 나오는 아이템 검색기를 어떻게 구현했을까? (그것도 전세계 사용자들이 올린 아이템을 실시간으로 검색한다. 그것도 나라마다 언어가 다른데 검색이 된다???)
1. 문제
일단 내가 세운 조건은 다음과 같다.
- 엄청나게 많은 데이터를 저장할 디비(초당 1000개로 설정)
- 아이템의 많은 속성들
- 전세계에서 검색가능해야함 (실시간 아이템 검색이 아닌 약간의 지연 상관없음 - 아이템을 올린 후 1분후에 검색되도 상관없음)
- 언어가 다르지만 검색되어야함 (4개국어로 설정)
검색시의 검색 필터값은 다음과 같다.
아이템의 검색 조건은 이름과 성능 / 거래조건으로 나뉘며, 아이템의 이름은 하나뿐이지만 성능의 속성은 엄청나게 많다.
속성만 100개 정도로 가정하며, 각 수치가 0~100씩 들어가고, 각각의 속성을 조합으로 검색 할수 있어야 한다.
예를 들어
공격력 : 10~ 100
힘 : 20 이상
방어력: 10이상
화염피해 : 20이상
의 속성은 아이템에 있어야 하며(and 조건)
다음의 속성은 하나라도 있어도 되는 or 조건이다.
회피 : 10이상
얼음방어 : 10이상
전기방어 : 50이상
사용자가 원하는 거래조건도 검색되어야 한다.
거래 화폐는 대략 7개로 나뉘어져 있다.
마지막으로 한글로 검색해도, 영어 / 중국어 / 아랍어로 된 아이템이 검색되어야 한다.
2. 분산 시스템
전 세계적으로 사용자가 많은 온라인 게임의 데이터베이스 선택은 성능, 확장성, 안정성, 그리고 데이터의 일관성을 고려해야 한다. 이러한 상황에서는 주로 분산 데이터베이스나 클라우드 기반 데이터베이스가 사용해야 한다.
- 관계형 데이터베이스 (RDBMS)
- NoSQL 데이터베이스
분산디비로 관계형 디비를 사용하면 간편하게 구축 가능하지만,
두번째, "아이템의 많은 속성들" 이 들어가 있다. 특히나 게임의 특성상 수시로 아이템의 속성이 늘어날수 있다. (예를 들어 시즌제나, DLC때 아이템의 속성이 늘어나면 관계형 디비일 경우엔 그떄마다 칼럼을 추가해준다면 엄청난 lock이 걸릴것이다.
혹은 칼럼 자체를 json으로 설정해서 사용하면 되는데, 문제는 json형태는 index가 되지 않기 때문에 항상 full scan이 된다.
그래서 nosql 데이터로 생각했다.
- MongoDB: JSON 형식 데이터를 저장하며, 빠른 데이터 쓰기와 읽기에 적합.
- Cassandra: 대규모 분산 데이터베이스. 쓰기 성능이 매우 뛰어나고, 중단 없는 확장이 가능.
특히나 쓰기와 읽기가 엄청나게 생기기 때문에 (초당 1000새로 설정) 쓰기와 읽기를 따로 구축해야 한다. (CQRS)
CQRS(명령-질의 책임 분리)의 주요 특징
CQRS는 쓰기와 읽기를 분리하여 각 요구사항에 맞는 최적화를 적용하는 패턴이다.
아이템과 같은 대규모 쓰기 작업에서는 CQRS만으로는 한계가 있을 수 있으며, 추가적인 데이터베이스 설계 및 분산 기술이 필요하다.
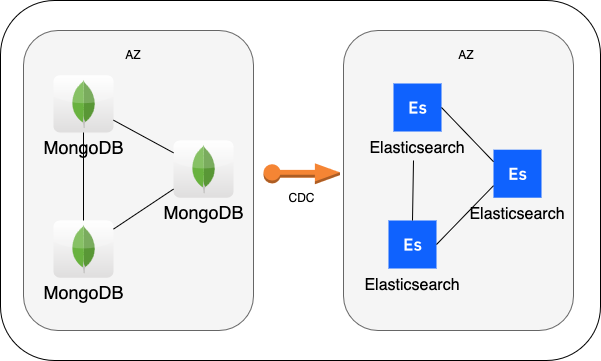
여기서 쓰기는 nosql로 검색은 엘라스틱서치로 생각했다. 두 디비를 서로 CDC로 하여 쓰기가 일어날때마다 엘라스틱서치로 데이터를 저장한다. 일반적인 게임을 하면서는 nosql을 바라보고, 아이템 검색기를 사용할떄만 엘라스틱 서치를 사용한다.
전 세계 데이터 분산
- Elasticsearch 클러스터를 지역별로 분산 필요
- 예: 미국, 아시아, 유럽에 데이터 노드 배포.
- 데이터를 지역으로 샤딩하고, 검색 시 근접한 노드에서 처리.
- cdc때문에 약간의 지연이 있지만, 검색이 실시간은 아니기 때문에 상관없음 (약간의 지연 상관없음)
3. 테이블 설계
기존 테이블은 mongodb로 설계합니다. 다국어 이름 검색을 위해 언어별 데이터를 한꺼번에 넣어줍니다. (물론 따로 id로 fk로 볼수도 있다)
{
"item_id": "abc123",
"name": {
"en": "Flaming Sword",
"ko": "불타는 검",
"zh": "烈焰之剑",
"hi": "जलती हुई तलवार"
},
"description": {
"en": "A sword imbued with fire magic.",
"ko": "화염 마법이 깃든 검입니다.",
"zh": "附有火焰魔法的剑。",
"hi": "आग के जादू से भरी तलवार।"
},
"attributes": {
"attack": 75,
"strength": 85,
"defense": 40,
"fire_damage": 30
},
"trade_conditions": {
"price": 100,
"currency": "gold"
},
"region": "global",
"timestamp": "2025-01-17T12:00:00Z"
}
인덱싱
- 필드 기반 인덱스: 자주 검색되는 필드(예: name, attributes.*, trade_conditions.currency)에 인덱스를 생성.
- 복잡한 쿼리 조건을 빠르게 처리하기 위해 복합 인덱스 사용:
db.items.createIndex({"attributes.attack": 1, "attributes.defense": 1, "trade_conditions.currency": 1})
파티셔닝
- MongoDB의 샤딩을 사용하여 전 세계 데이터를 분산
- 샤드 키: region + item_id
- 지역(예: NA, EU, ASIA) 및 아이템 ID를 기반으로 데이터 분산
검색 설계
아이템 검색은 복잡한 조건(AND/OR 조합, 범위 검색)이 있으므로 검색 엔진을 추가로 사용해야 합니다.
- Elasticsearch
- 고성능 풀텍스트 검색과 복잡한 쿼리 조건을 빠르게 처리.
- 아이템 데이터 동기화:
- MongoDB와 Elasticsearch를 Change Streams나 Debezium으로 연결하여 실시간으로 데이터를 Elasticsearch에 동기화.
- Elasticsearch는 다국어 데이터를 처리하기 위해 멀티필드 인덱스와 언어별 분석기를 지원
- 멀티필드(Multi-field) 매핑
- 아이템 이름과 설명에 대해 언어별 필드를 정의.
- 언어별로 적합한 텍스트 분석기(Analyzer)를 적용.
- 영어: english
- 한국어: korean (nori analyzer)
- 중국어: smartcn 또는 jieba
- 힌디어: hindi (third-party plugin 필요 시 설치)
- Elasticsearch 매핑 예시
{
"mappings": {
"properties": {
"name": {
"properties": {
"en": { "type": "text", "analyzer": "english" },
"ko": { "type": "text", "analyzer": "korean" },
"zh": { "type": "text", "analyzer": "smartcn" },
"hi": { "type": "text", "analyzer": "hindi" }
}
},
"description": {
"properties": {
"en": { "type": "text", "analyzer": "english" },
"ko": { "type": "text", "analyzer": "korean" },
"zh": { "type": "text", "analyzer": "smartcn" },
"hi": { "type": "text", "analyzer": "hindi" }
}
},
"attributes": {
"properties": {
"attack": { "type": "integer" },
"strength": { "type": "integer" },
"defense": { "type": "integer" },
"fire_damage": { "type": "integer" }
}
},
"trade_conditions": {
"properties": {
"price": { "type": "float" },
"currency": { "type": "keyword" }
}
},
"region": { "type": "keyword" }
}
}
}
4. 검색
다국어 검색을 위해 쿼리는 다음과 같아집니다.
- 이름 검색 (Elasticsearch bool 쿼리를 활용)
{
"query": {
"bool": {
"should": [
{ "match": { "name.ko": "불타는 검" } },
{ "match": { "name.en": "불타는 검" } },
{ "match": { "name.zh": "불타는 검" } },
{ "match": { "name.hi": "불타는 검" } }
],
"minimum_should_match": 1
}
}
}
- 검색 조건 통합 (속성 조건도 함께 처리)
{
"query": {
"bool": {
"must": [
{ "range": { "attributes.attack": { "gte": 10 } } },
{ "range": { "attributes.strength": { "gte": 20 } } },
{ "match": { "trade_conditions.currency": "gold" } }
],
"should": [
{ "match": { "name.ko": "불타는 검" } },
{ "match": { "name.en": "불타는 검" } }
],
"minimum_should_match": 1
}
}
}
5. 결론
- 다국어 지원: 언어별 검색 및 글로벌 사용자 검색 가능.
- 확장성: Elasticsearch와 NoSQL을 결합하여 쓰기/읽기 확장성 보장.
- 유연성: 새로운 언어와 필드 추가 가능.
but
- 복잡성 증가: 다국어 데이터 동기화 및 관리가 복잡.
- 운영 비용: Elasticsearch 클러스터 관리 및 분석기 튜닝 필요.
- 실시간성 제한: MongoDB → Elasticsearch 동기화 시 약간의 지연 발생.
- 동영상에서 나오듯이 한국서버만 느린 이유는 아마 엘라스틱서치에서 한국 토크나이저가 느린게 아닐까 생각한다...(혹은 읽기 태스크 서버를 낮게 설정했거나?)
끝!
'server > system design' 카테고리의 다른 글
| fastapi로 server sent event 구현 실습 (1) | 2025.01.28 |
|---|---|
| [2] 챗봇 프론트 화면을 만들어보자. (0) | 2025.01.24 |
| postgreSQL CDC를 활용한 엘라스틱서치로 데이터 실시간 연동 (0) | 2025.01.14 |
| kafka를 이용한 서버 아키텍처 구현 (0) | 2025.01.09 |
| redis pub/sub을 이용한 서버 아키텍처 구현 (0) | 2025.01.08 |