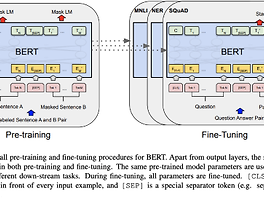
ML/LLM (16) 썸네일형 리스트형 [1] 이력서 챗봇 만들기 - LLM 설정 및 서버 적용 1. 모델 선택 먼저 임베딩 모델을 선택해야 한다. 계속 써오던 multilingual-e5 모델을 다시 쓸까 했는데, 마침 새로운 모델중에서 한국어 수치도 좋은 것들이 많아서 새로나온 모델을 선택해봤다.아래는 최근에 만들어진 고려대학교의 모델이다. 오!! 괜찬은 성능이라 판단해서 해당 모델로 선택했다.https://github.com/nlpai-lab/KUREnlpai-lab/KURE-v10.526400.605510.605510.55784dragonkue/BGE-m3-ko0.523610.603940.603940.55535BAAI/bge-m30.517780.598460.598460.54998Snowflake/snowflake-arctic-embed-l-v2.00.512460.593840.593840.5.. 벡터 표현과 HNSW 구현에 대해서는 다음 포스팅을 참조하세요 : https://uiandwe.tistory.com/1398 1. 벡터화 과정일반적으로 텍스트 데이터를 벡터로 만드는 과정은 다음과 같습니다. 1. 원천 데이터터에서 철자를 교정하고 불필요한 문자를 제거합니다. (소문자 변환, 토큰화, 특수문자 제거, 불용어 제거, 형태소 분석)2. 전처리 후 텍스트에서 단어 임베팅 값을 추출합니다. (다차원 공간의 특정 위치에 단어를 매핑합니다.)3. 임베팅 값은 벡터로 변환할수 있습니다. 벡터 차원의 특정한 특징에 중요도나 관련성을 반영합니다. 위의 과정을 통해 백터를 가지고 HNSW 알고리즘을 통해 벡터 사이의 근사값을 계산할 수 있습니다. 2. HNSW (Hierarchical Navigable Small World .. The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions https://arxiv.org/pdf/2404.13208 요약프롬프트상에서 사용자의 프롬프트를 막게 되면 답변의 질이 떨어지게 된다.모델 생성시 보안에 대한 추가적인 학습을 통해서 해야만 좋은 성능을 보일수 있다. (일반 프롬프트단에서는 방법없음..괜히 읽었나…) Abstract오늘날의 LLM은 프롬프트 인젝션, 탈옥 및 기타 공격에 취약하여 공격자가 모델의 원래 지침을 악의적인 프롬프트로 덮어쓸 수 있습니다.이 연구에서는 이러한 공격의 근간이 되는 주요 취약점 중 하나는 LLM이 시스템 프롬프트(예: 애플리케이션 개발자의 텍스트)를 신뢰할 수 없는 사용자 및 제3자가 보낸 텍스트와 동일한 우선순위로 간주하는 경우가 많다는 점이라고 주장합니다.이 문제를 해결하기 위해 우선순위가 다른 명령어가 충돌할 .. Failed to initialize NVML: Driver/library version mismatch nvidia-smi 실행시 오류 발생Failed to initialize NVML: Driver/library version mismatch 해결책 먼저 현재 nvidia 실행중인 프로세서를 모두 kill 한다.sudo lsof /dev/nvidia* kill -9 다시 lsof 로 검색시 나오는게 없으면 다음으로 진행sudo lsof /dev/nvidia* nvidia 관련 모듈 재시작sudo rmmod nvidia_drmsudo rmmod nvidia_modesetsudo rmmod nvidia_uvmsudo rmmod nvidiasudo modprobe nvidia 정상 동작 확인$ nvidia-smi 끝 [논문리뷰] KNOWLEDGE SOLVER: TEACHING LLMS TO SEARCH FORDOMAIN KNOWLEDGE FROM KNOWLEDGE GRAPHS https://arxiv.org/pdf/2309.03118 나의 결론 : graph search를 통해 LLM의 성능을 향상 시킬수 있다 (파인튜닝시에도 유용하게 사용할 수 있다) AbstractChatGPT 및 GPT-4와 같은 대규모 언어 모델(LLM)은 다양한 작업을 해결할 수 있습니다. 그러나 LLM은 때때로 작업을 수행하기 위한 도메인별 지식이 부족하여 추론 중 환각을 유발하기도 합니다. 이전 연구에서는 도메인별 지식 부족 문제를 완화하기 위해 외부 지식 기반에서 검색된 지식에 대해 그래프 신경망(GNN)과 같은 추가 모듈을 학습시켜 도메인별 지식 부족 문제를 완화했습니다.하지만 추가 모듈을 통합하려면1) 새로운 도메인을 접할 때 추가 모듈을 재학습2) LLM의 강력한 능력을 충분히 활용하지 못.. [논문리뷰] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding https://arxiv.org/abs/1810.04805 요약 : bert는 성능도 우수합니다! - 충분한 데이터만 있다면요 Abstract - 양방향 인코더 - 트랜스포머와 달리 BERT는 레이블이 없는 텍스트의 양방향 표현을 사전 학습하도록 설계되었습니다 - 레이블이 없는 텍스트에 대해 컨디셔닝하여 모든 레이어에서 왼쪽과 오른쪽 컨텍스트를 학습한다. 그 결과, pre-trained BERT 모델은 단 하나의 추가 출력 레이어만으로 미세 조정할 수 있습니다. 1. Introduction - pre-training 언어모델은 많은 자연어 처리 task의 향상에 좋은 성능을 발휘하고 있습니다. - downstream task를 위해 pre-trainedfmf 학습하는 방식에는 두가지 방법이 있다 1. f.. [dacon] 도배 하자 질의 응답 처리 : 한솔데코 시즌2 AI 경진대회 https://dacon.io/competitions/official/236216/overview/description 도배 하자 질의 응답 처리 : 한솔데코 시즌2 AI 경진대회 - DACON 분석시각화 대회 코드 공유 게시물은 내용 확인 후 좋아요(투표) 가능합니다. dacon.io 해당 대회가 LLM관련 대회여서, 심심한데 한번 해볼까? 하는 마음에 시작하게 되었다. (진지하게는 못했다...하하) 그냥 기본적인 내가 아는 기술을 써서 어디까지 올라가는지 테스트 해보고 싶었다. (hyde를 구현해서 실제로 써보고 싶었다.) 먼저 해당 대회의 내용을 읽어보면 "다양한 질문과 상황을 제공하고, 이에 대한 정확하고 신속한 응답을 제공하는 AI 모델을 개발이 목표이다" 나의 목표는 1. 모델 파인튜닝 2. .. [논문리뷰] Retrieval-Augmented Generation for Large Language Models: A Survey 해당 논문의 원문은 여기에서 볼수 있습니다. https://arxiv.org/pdf/2312.10997.pdf 요약: LLG함께 RAG도 많은 발전이 이뤄졌다. 상황에 맞는 RAG를 선택하고 구축한다면, 더 좋은 품질의 LLM 결과를 얻을 수 있다. Abstract 대규모 언어 모델(LLM)은 상당한 기능을 보여주지만 환각, 오래된 지식, 알수없는 추론 과정 등의 문제에 직면해 있습니다. 검색 증강 세대(RAG)는 모델의 정확성과 신뢰성을 향상시키고 지속적인 지식 업데이트 및 통합 지속적인 업데이트와 통합이 가능하여 유망한 솔루션으로 부상했습니다. 이 논문은 RAG 패러다임의 발전 과정을 자세히 살펴보며 ( Naive RAG, Advanced RAG, Modular RAG ) RAG 평가를 위한 메트릭과.. 이전 1 2 다음