1. 요구사항
- 플랫폼에 1000억개의 이미지가 있다. 사용자가 이미지를 업로드하면 가장 유사한 이미지들을 검색해야 한다.
- 이미지에는 메타데이터가 없으며, 오직 픽셀 데이터만 사용해야 한다.
2. 문제 구조화
먼저 쿼리에 해당하는 입력값은 이미지다. 사용자는 이미지를 입력하면 출력으로 이미지 리스트가 나와야 한다.
출력되는 이미지들은 쿼리 이미지와 유사한 이미지 세트를 출력한다.
먼저 해당 이미지들에 대한 분류(classification)가 되어야 한다. 특정 사물에 대한 분류를 통한 출력 세트를 만들수 있다.

혹은 특정 유사도를 통해서도 분류를 할 수 있다. 개와 고양이의 분류가 물체에 대한 인식이라면, 유사도는 비슷한 모든것을 지칭할수 있다.
표현학습은 이미지와 같은 입력 데이터를 임베딩이라는 표현으로 변환하도록 모델을 훈련한다. 모델은 입력된 이미지를 임베딩 공간인 N차원 공간의 포인트로 매핑한다. 해당 공간에서는 유사한 이미지는 서로 근접한 임베딩을 갖도록 되어 있다.

3. 훈련 데이터 셋 구성

강아지 이미지를 훈련한다고 가정하자. 훈련 데이터 셋을 준비하기 위해 각 항목을 평가한다면 다음과 같다.
* 사람 평가 (라벨링)
* 사용자 클릭과 같은 상호 작용으로 선정
* 쿼리 이미지에서 유사한 이미지를 인위적으로 생성 (증강 이미지)
를 통해서 지속적으로 기존의 이미지를 훈련셋에 포함시킬수 있다.
4. 평가
훈련의 목표는 임베딩 공간에서 유사한 이미지가 서로 가깝게 임베딩 되도록 모델 파라미터를 최적하는것이다.

결국 공간상에서 가까운 객체를 찾아야 하는데, 해당 거리를 좁히기 위해서는 대조 손실을 통해 모델을 평가한다.
1. CG(cumulative gain)

- 상위 p개의 추천 결과들의 관련성(rel, relevance) 누적값
- binary value(관련이 있는지 없는지)에 대한 합산

총 아이템에 대한 기대값이 다음과 같을때 CG@3 을 계산한다면 상위 3개를 계산해야 하므로 3+2+1=6이 된다.
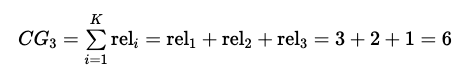
2. DCG(Discounted Cumulative Gain)

기존 CG(각 항목의 연관성 점수를 합산하여 누적 점수를 계산)에서점수의 합산은 순위가 높은 목록의 상단에서 하단으로 누적시켜가며 결과의 순위가 낮아질수록 점점 낮은 점수(불이익)을 준다.
랭킹 순서에 대한 로그함수를 통해 하위권으로 갈수록 rel 대비 작은 값을 가진다. (하위권 결과에 패널티를 주는 방식)
DCG@3일 경우엔 CG와 비슷하지만 분모에 log(i+1)값이 추가된다고 보면 된다.

3. nDCG(normalized Discounted Cumulative Gain)
- 추천시스템에서 랭킹 추천 분야에 많이 쓰이는 평가지표
- 관련성이 높은 결과를 상위권에 노출 여부
- 검색엔진, 영상추천 등의 다양한 추천 시스템의 평가지표
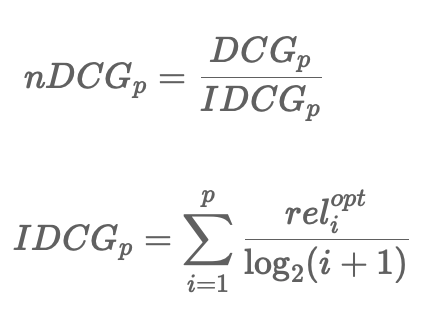
IDCG@3을 계산한다고 하면 추천된 값중 최상위 값으로 정렬을 한 후 계산된다.
위의 이미지를 최상위 값들은 3, 3, 2 순으로 된다. 그리고 분모에는 DCG와 마찬가지로 log값이 취해진다.
결국 식은 다음과 같다.
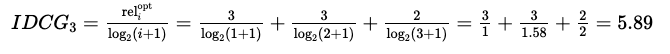

5. 서빙

사용자가 쿼리 이미지를 검색 요청을 하면 미리 준비된 인덱싱 DB에서 유사도 검색을 통해 기존의 이미지들을 랭킹 후 목록을 보여준다
또한 지속적인 인덱싱 파이프라인을 통해 사용자에게 보여줄 유사 이미지를 계속적으로 저장한다.
랭킹부분에서는 비지니스 로직과 정책을 반영한다. 예를 들어, 부적절한 결과를 필터링하고, 비공개 이미지를 포함하지 않도록 하며, 중복되는 결과를 제거하고 사용자에게 최종 결과물을 제공한다.
근접 이웃 찾기
쿼리 이미지를 임베딩을 통해 벡터로 변환하여, 임베딩 공간에서 유사한 이미지를 검색해야 한다.

쿼리 q에 대하여 최근접 이웃 검색을 진행한다면 임베딩 공간상에서 가장 가까운 객체들을 찾아야 한다.
임베딩 공간은 각 차원이 고유의 속성을 가지고 있으므로 가장 가깝다는 뜻은 가장 유사한 객체임을 뜻한다.
벡터 디비 인덱싱
벡터 임베딩을 활용한 경우 가까운 이웃들은 같은 영역을 포함할 경우가 많다.
즉 높은 차원의 공간이라도 차원을 축소함으로서 가장 유사한 객체를 찾아낼수 있어, 차원 축소를 통해 속도를 높힐수 있다.
여러 벡터 디비중 하나인 faiss에 대해서 알아보자.
Faiss는 Facebook에서 밀집 벡터(dense vector)의 효율적 검색과 클러스터링을 위해 개발한 라이브러리이다. faiss는 반전 인덱스(inverted indices), 벡터 양자화(product quantization), 근사적인 거리 계산 반전된 파일(IVFADC) 등의 다양한 인덱스 구조를 제공한다.
faiss에서 지원하는 IndexFlatL2 칼럼(L2거리 기반 인덱싱)
쿼리 벡터와 인덱스에 로드된 벡터 사이의 모든 지정된 지점 사이의 L2(또는 유클리드) 거리를 측정합니다 .
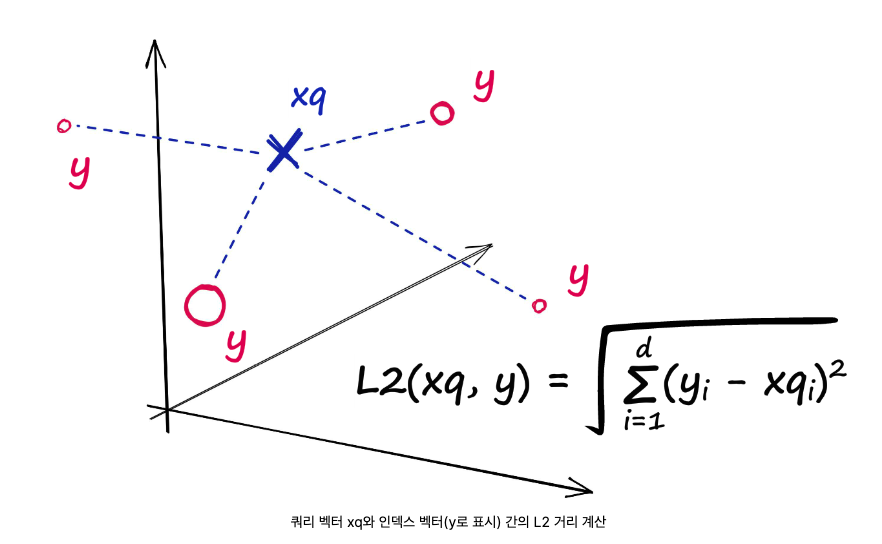
인덱싱 방식
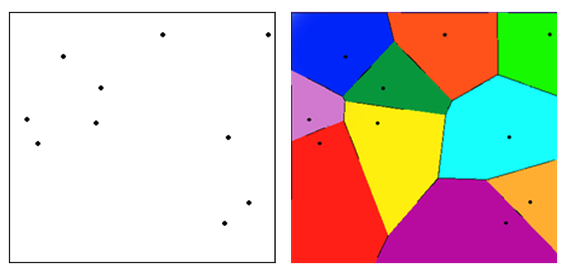
보로노이 다이어그램(Voronoi diagram)을 사용하면 similarity search을 구현할 수 있다.
보로노이 다이어그램(Voronoi diagram)은 특정 공간에서 점까지의 거리가 가장 가까운 점의 집합으로 분할한 그림이다. 평면에서 점과 점 사이의 중간 지점에 선을 긋고 해당 선들을 닫힌 꼴로 만들어 내면 해당 점에 대한 일정한 공간(cell)을 차지하는 모향을 만들수 있다.
새 데이터가 들어오면 모든 voronoi 공간에서의 거리를 계산한다. 계산된 거리 중 가장 짧은 거리를 가진 cell과 유사하다고 판단할 수 있다. 해당 Cell의 벡터는 다른 cell의 벡터보다 가깝다고 할수 있다.
하지만 가장 가까운 cell의 벡터들의 거리만 계산하는 것은 검색된 벡터가 쿼리 벡터와 가장 유사하다는 것을 보장할 수 없다. 쿼리 벡터가 두 cell의 경계 근처에 있는 경우에는 다른 cell에 있는 벡터가 오히려 가장 가까울 수도 있기 때문이다. 따라서 가장 가장 가까운 centroid만 조사하는 것이 아닌 m개의 centroid를 조사한다.
즉 Voronoi Diagram을 사용해 벡터의 인덱싱을 나타낼수 있으며, 그 후 주위 m개를 계산함으로써 정확한 유사도를 나타낼수 있다.
전체적인 순서는 다음과 같다.

- 주어진 벡터 DB에 대해 벡터들을 n개의 Voronoi 파티션으로 나눈다.
- 각 Voronoi partition의 벡터들에 centroid를 빼면 벡터들은 0 주변으로 모이게 된다. 원본 벡터는 centroid 벡터와 residual만 저장만 있으면 복구가 가능하다. 따라서 원본 벡터를 따로 저장할 필요 없다.
- 각 파티션의 모든 벡터들에 대해 product quantization을 수행한다.
끝
참조
(책)가장면접 사례로 배우는 머신러닝 시스템 설계
https://product.kyobobook.co.kr/detail/S000212266758
가상 면접 사례로 배우는 머신러닝 시스템 설계 기초 | 알리 아미니안 - 교보문고
가상 면접 사례로 배우는 머신러닝 시스템 설계 기초 | 유튜브 동영상 추천, 에어비앤비 상품 추천, 뉴스 피드 생성 같은 머신러닝 시스템은 어떻게 설계할까?이 책은 실제 서비스되고 있는 머신
product.kyobobook.co.kr
https://joyae.github.io/2020-09-02-nDCG/
https://hoon-bari.github.io/RS/Recommender_evaluation
https://discuss.pytorch.kr/t/what-is-vector-similarity-search/2475
https://www.pinecone.io/learn/series/faiss/faiss-tutorial/
https://towardsdatascience.com/understanding-faiss-619bb6db2d1a
https://pangyoalto.com/faiss-1-hnsw/
https://devocean.sk.com/blog/techBoardDetail.do?ID=165293&boardType=techBlog
'ML > MLops' 카테고리의 다른 글
| ml를 쉽게 쓰기 위한 프론트 작업 (0) | 2024.05.03 |
|---|---|
| [system design] 이벤트 추천 시스템 (1) | 2024.03.22 |
| [system design] 유해 콘텐츠 감지 (1) | 2024.03.16 |
| onnx model Quantization (0) | 2024.03.11 |
| ONNX (1) | 2024.01.08 |


