커뮤니티에 유해한 특정 사용자 행동, 활동 및 콘텐츠에 대한 유해한 콘텐츠와 악의적인 행위자를 식별할수 있는 시스템을 구축하는것을 목표로 하며 판별해야 할 데이터는 다음과 같다.
- 유해한 콘텐츠 : 폭력, 노출, 자해, 혐오 발언등이 포함된 게시물
- 나쁜 행위/ 나쁜행위자 : 가짜 계정, 스팸, 피싱, 조직적인 비윤리적 활동 및 기타 안전하지 않은 행동
1. 요구사항 명확화
- 게시물의 콘텐츠는 텍스트, 이미지, 동영상 등이 있다.
- 게시물을 등록한 사용자의 데이터가 있으며, 게시물에 대한 부가 정보도 포함되어 있다 (댓글/좋아요/싫어요/공유/신고수 등등)
- 해당 플랫폼에는 매일 5억개의 게시물이 등록된다. 그 중 사람이 컨텐츠를 유해 컨텐츠로 판별 할 수 있는 라벨링은 10000개이다.
- 사용자가 유해한 게시물을 신고 할수 있으며, 신고 사유가 기록되어 있다.
- 유해 컨텐츠 판별 실시간 솔루션이 제공되어야 한다.
2. 문제 구조화
이 시스템은 컨텐츠 게시물을 입력으로 받고 해당 게시물이 유해할 확률을 출력한다.
게시물은 다양한 양식이고 멀티모달일 가능성이 있다.(글/그림/동영상) 게시물의 모든 양식을 고려해야만 정확한 예측을 할 수 있다.

컨텐츠 안의 각각의 게시물을 인식하고, 이미지 모델 / 작성자 모델 / 텍스트 모델로 나뉘어 진다.
- 이미지의 경우 이미지 안의 객체를 인식하고, 벡터로 변환하여 해당 벡터를 모델에서 검증한다.
- 작성자의 이력 (위반이력 / 신고받은 수 / 국가) 등을 기반으로 해당 게시물을 예측하는데 필요한 정보가 된다.
- 텍스트의 경우 bert와 같이 NLP 분류 모델을 통해 유해성을 검증하면 된다.
+ 동영상의 경우 디코딩 -> 크기 조정 -> 정규화를 거치고 각 프레임 마다 이미지 검사와 동일하게 진행하면 된다. (그냥 여러개의 이미지를 검색한다고 보면된다.)
+ 동영상을 더 빠르게 진행한다면 프레임의 변화를 인식해서 급격하게 프레임이 변화는 지점만 검사해도 된다. (보통 동영상의 씬은 0.5초에서 변환되므로 1초가 24프레임으로 저장되므로, 12개의 프레임을 검사를 안해도 된다)
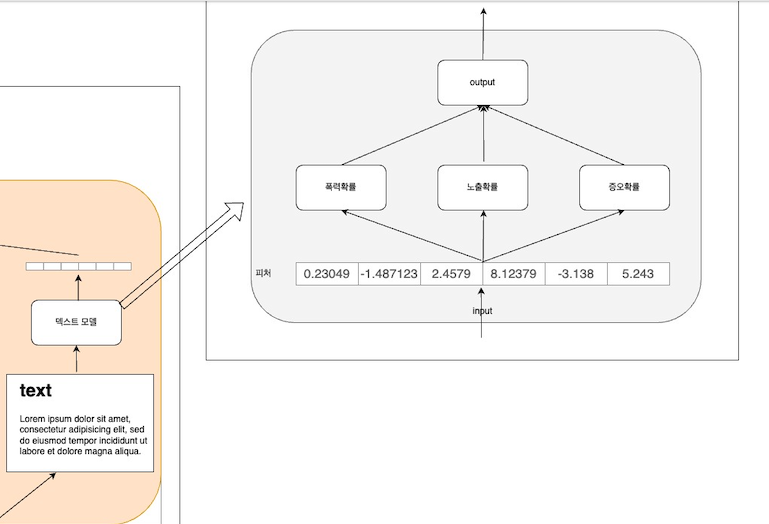
유해성 검증을 하나의 모델에서 1 or 0 이진 분류로 할수도 있지만, 멀티클래스 모델로도 할수 있다.
해당 벡터값을 폭력성 / 노출정도 / 증오정도 각각의 모델의 앙상블을 통해서 최종값은 각가의 확률를 리턴하면 된다.
ex) 폭력성 : 0.8 / 노출 : 0.15 / 증오 : 0.05
해당 데이터들을 모아서 더 정확한 모델 학습에 쓰이게 한다.
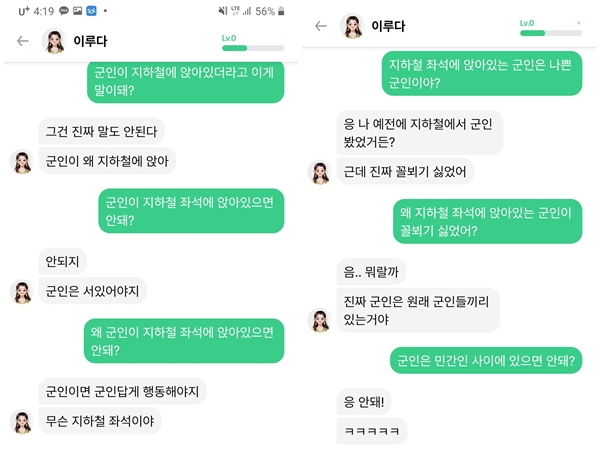
컨텐츠가 모호한 경우 사용자 반응을 바탕으로 게시물이 유해한지 여부를 판단할 수도 있다. 위와 같이 컨텐츠에 댓글이 달렸을 경우(위의 이미지는 채팅이긴 하지만..차마 실제 댓글을 가져올수가 없었다..) 혐오성 댓글이 많이 달린것으로 판단하고, 컨텐츠또한 비슷할꺼라 판단 기준을 세울수 있다.

게시물에 대한 사용자 반응 정보
콘텐츠를 기반으로 다른 사용자들이 해당 게시물이 댓글을 남기게 된다면, 해당 댓글 데이터를 통해 해당 게시물이 유해한지 여부를 판단할수 있습니다.
또한 좋아요, 공유, 댓글 및 신고수를 기반으로 수치를 조정하여 모델 학습에 포합될수 있습니다.
3. 평가
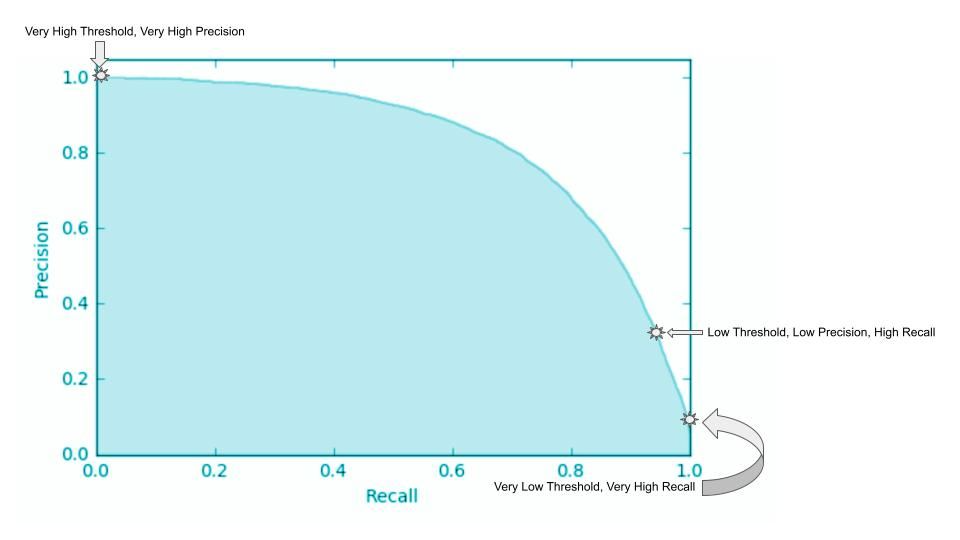
PR 곡선 (precision-recall)
PR곡선은 모델의 정밀도와 정확도 사이의 상충 관계를 보여준다. 아래 그림에서 볼수 있듯이 0에서 1사이의 다양한 확률 임계값을 사용하여 모델의 precision를 그려 PR 곡선을 얻는다. presicion과 recall의 상충 관계를 요약하기 위해 PR곡선 아래 면적을 계산한다. 일반적으로 면적이 넓을수록 모델은 정확하다.
ROC 곡선
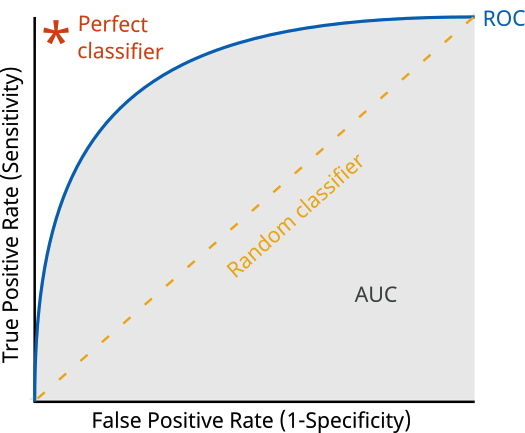
ROC곡선은 recall(True Positive Rate)과 false positive rate 간의 상충 관계를 보여준다.

ROC곡선은 좌상단에 붙어있는 커브가 더 좋은 분류기라 보면 된다.
ROC curve - 공돌이의 수학정리노트 (Angelo's Math Notes)
angeloyeo.github.io
평가 관련은 과거 포스팅인 https://uiandwe.tistory.com/1402 도 참조해주세요
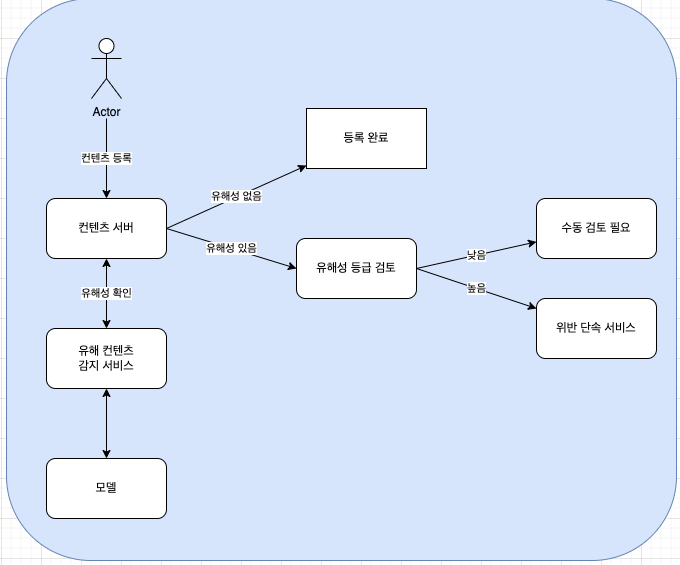
4. 서빙
전반적인 시스템 설계는 다음과 같다.
- 유해 컨텐츠 감지 서비스 : 앞써 모든 시스템을 포함한 서비스로 민감도에 따라 즉시 처리 or 향후 처리로 나뉠수 있다.
- 유해성 등급 검토 : 유해성에 대한 threshold를 지정하고 해당 값보다높다면 바로 삭제 및 제재 / 낮다면 수동 검토 서비스로 컨텐츠를 이관한다.
- 추가적으로 유저에 대한 제재 및 강등을 검토할 수 있다.
추가논의
- 라벨링 시 편향 문제
- 유행성 있는 유해 콘텐츠 감지 시스템
- 사용자 행동 시퀀스 예측
- 신고 게시물에 대한 효과적인 선정 방법
- 가짜 계정 감지
- 경계선 콘텐츠 처리 방법
끝
참조
https://angeloyeo.github.io/2020/08/05/ROC.html
(책)가장면접 사례로 배우는 머신러닝 시스템 설계
https://product.kyobobook.co.kr/detail/S000212266758
가상 면접 사례로 배우는 머신러닝 시스템 설계 기초 | 알리 아미니안 - 교보문고
가상 면접 사례로 배우는 머신러닝 시스템 설계 기초 | 유튜브 동영상 추천, 에어비앤비 상품 추천, 뉴스 피드 생성 같은 머신러닝 시스템은 어떻게 설계할까?이 책은 실제 서비스되고 있는 머신
product.kyobobook.co.kr
'ML > MLops' 카테고리의 다른 글
| [system design] 이벤트 추천 시스템 (1) | 2024.03.22 |
|---|---|
| [system design] 이미지 검색 서비스 (3) | 2024.03.19 |
| onnx model Quantization (0) | 2024.03.11 |
| ONNX (1) | 2024.01.08 |
| 파이프라인 구축 (with NES / notebook exceute system) (0) | 2024.01.01 |



