모델을 생성하고 단순히 배포만 하는게 아닌 서빙시에는 당연히 메모리가 적게 들어가면서 똑같은 성능을 발휘할수 있다면 최적의 결과를 얻을 수 있습니다. (성능은 똑같은데 비용은 준다고?!)
물론 모델을 어디에 배포하느냐, 어떤 모델을 사용했느냐에 따라서 상황이 달라지지만,
이번 포스팅에서는 onnx를 이용해서 배포시 모델을 양자화하는 방법입니다.
onnx에 대한 설명은 예전 포스팅에서 확인하실수 있습니다. : https://uiandwe.tistory.com/1401
1. 양자화란?
모델의 인퍼런스시 가장 중요한것은 서버의 메모리를 어떻게 줄이느냐입니다.
메모리 사용량을 줄이기 위해 벡터 양자화 및 프로덕트 양자화 같은 다양한 최적화 방법을 사용합니다.
양자화는 모델 매개변수를 구성하는 32비트 크기의 실수 자료형의 숫자를 8비트 크기의 정수 자료형의 숫자로 전환하는 기법입니다. 양자화 기법을 적용하면, 정확도는 거의 같게 유지하면서, 모델의 크기와 메모리 전체 사용량을 원본 모델의 4분의 1까지 감소시킬 수 있고, 추론은 2~4배 정도 빠르게 만들 수 있습니다. (https://tutorials.pytorch.kr/recipes/quantization.html)
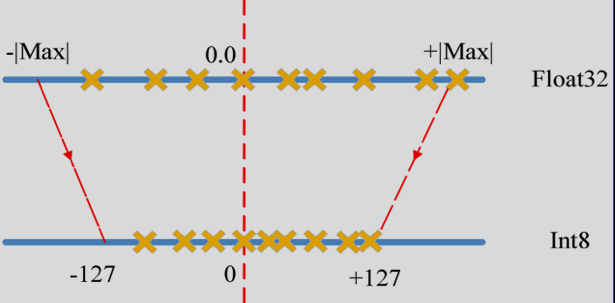
이번 포스팅에서는 optimum을 사용해서 양자화를 진행해보겠습니다.
Optimum은 exporters.onnx모듈을 통해 PyTorch/TensorFlow 모델을 ONNX로 export 작업을 위한 추상화 모델을 제공하며, cmd만으로 실행합니다.
2. 양자화 실습
필요한 패키지 설치
$ pip install optimum[exporters] sentence_transformers
optimum-cli를 통해 기존 모델을 onnx 모델로 변환합니다. (참조: https://huggingface.co/docs/transformers/main/ko/serialization )
$ optimum-cli export <onnx로 변환> --model <huggingface모델> <저장할 위치>
$ !optimum-cli export onnx --model intfloat/multilingual-e5-large onnx_model/ --task feature-extraction몇분이 지나면 onnx로 변환된 모델이 저장된 것을 볼 수 있습니다.

다음으로는 ONNX 모델의 가중치를 Uint8 형식으로 양자화 합니다.
양자화를 진행하면 모델 크기를 1/4로 줄일 수 있고 추론 속도도 빨라지지만 하지만 정확도에 대한 손실이 있을 수 있습니다
from onnxruntime.quantization import quantize_dynamic, QuantType
output = "onnx_model/model.onnx" # onnx 모델 위치
converter = "onnx_model/multilingual-e5-large-uint8.onnx" # 저장할 모델 위치
quantize_dynamic(output, converter, weight_type=QuantType.QUInt8)
기존 모델을 보면 2.24GB인것을 확인할수 있습니다.

양자화 모델 사이즈의 535M로 기존 2.22G보다 약 4배 가량 줄어든것을 볼 수 있습니다.
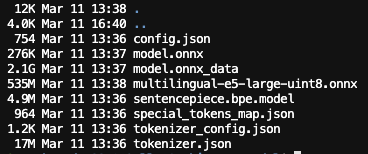
인퍼런스시의 메모리 또한 최소 50~60% 줄어든것을 확인했습니다.
기존 모델과 onnx 양자화 모델을 테스트셋을 비교 해봤으며 저의 경우 기존 테스트셋과 동일한 값이 나오는거을 확인했습니다.
(인퍼런스의 결과가 소수점 마지막 자리 정도만 달라졌음을 확인했습니다)
ML 파이프라인에 모델 변환 단계를 통합하실때는 작은 데이터셋으로 Sanity check를 꼭 포함하시기 바랍니다. 변환하는 과정에서 성능이 저하될수 있으므로, 항상 전수검사는 필수 입니다!!
번외
인퍼런스 서빙시 최적화 프레임워크들에 대한 소개글입니다
- FasterTransformer: 더 빠른 추론 시간을 제공하는 것을 목표로 BERT 및 GPT를 포함한 트랜스포머 기반 모델에 특별히 최적화되어 있습니다. https://github.com/NVIDIA/FasterTransformer
- DeepSpeed: 분산 학습 및 추론을 간소화하여 대규모 모델 및 데이터 세트로 더 쉽고 효율적으로 작업할 수 있도록 하는 딥 러닝 최적화 라이브러리입니다. https://github.com/microsoft/DeepSpeed
- TensorRT: 고성능 딥 러닝 추론에는 추론 애플리케이션에 짧은 지연 시간과 높은 처리량을 제공하는 딥 러닝 추론 옵티마이저 및 런타임이 포함됩니다. TensorRT를 사용하여 NVIDIA GPU에서 ONNX 모델을 실행할 수 있는 ONNX 모델용 백엔드로, 이미 ONNX 모델로 작업하고 있는 사용자를 위한 원활한 통합을 제공합니다. https://github.com/NVIDIA/TensorRT
- VLLM: 대규모 언어 모델(LLM)을 위해 특별히 설계된 높은 처리량과 메모리 효율적인 추론 및 제공 엔진으로, 이러한 모델 규모를 배포하기 위한 강력한 솔루션을 제공합니다. https://github.com/vllm-project/vllm
- OpenVINO:™ AI 추론을 최적화하고 배포하기 위한 오픈 소스 툴킷으로, 다양한 Intel 프로세서 및 GPU에 대한 포괄적인 지원을 제공합니다. https://github.com/openvinotoolkit/openvino
- 플래시 어텐션(Flash-Attention): 빠르고 메모리 효율적인 정확한 어텐션 메커니즘을 제공하며, 이는 정확한 어텐션 계산이 필요한 모델에 특히 유용할 수 있습니다. https://github.com/Dao-AILab/flash-attention/tree/main
- TVM: CPU, GPU 및 특수 가속기를 포함한 다양한 하드웨어 플랫폼에서 딥 러닝 모델을 효율적으로 배포할 수 있는 오픈 소스 컴파일러 스택 Whisper.cpp: 음성 인식 모델을 효율적으로 배포할 수 있는 기능을 보여주는 C/C++의 OpenAI Whisper 모델 포트: https://github.com/apache/tvm
- ONNX 런타임: 광범위한 하드웨어 및 워크로드를 지원하는 플랫폼 간 고성능 추론 및 학습 가속기: https://github.com/microsoft/onnxruntime
아오..힘들다..
참고
https://tutorials.pytorch.kr/recipes/quantization.html
https://huggingface.co/docs/optimum/exporters/onnx/overview
https://huggingface.co/docs/transformers/main/ko/serialization
https://medium.com/@enerzai/onnx-%EB%84%88-%EB%88%84%EA%B5%AC%EC%95%BC-who-are-you-5c1435b997e2
https://huggingface.co/docs/transformers/main/ko/serialization
'ML > MLops' 카테고리의 다른 글
| [system design] 이미지 검색 서비스 (3) | 2024.03.19 |
|---|---|
| [system design] 유해 콘텐츠 감지 (1) | 2024.03.16 |
| ONNX (1) | 2024.01.08 |
| 파이프라인 구축 (with NES / notebook exceute system) (0) | 2024.01.01 |
| 3. 각 회사별 MLops (0) | 2023.12.25 |



