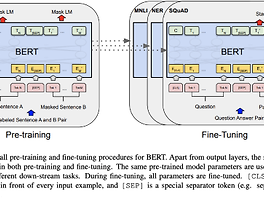
[system design] 유해 콘텐츠 감지
커뮤니티에 유해한 특정 사용자 행동, 활동 및 콘텐츠에 대한 유해한 콘텐츠와 악의적인 행위자를 식별할수 있는 시스템을 구축하는것을 목표로 하며 판별해야 할 데이터는 다음과 같다. - 유해한 콘텐츠 : 폭력, 노출, 자해, 혐오 발언등이 포함된 게시물 - 나쁜 행위/ 나쁜행위자 : 가짜 계정, 스팸, 피싱, 조직적인 비윤리적 활동 및 기타 안전하지 않은 행동 1. 요구사항 명확화 - 게시물의 콘텐츠는 텍스트, 이미지, 동영상 등이 있다. - 게시물을 등록한 사용자의 데이터가 있으며, 게시물에 대한 부가 정보도 포함되어 있다 (댓글/좋아요/싫어요/공유/신고수 등등) - 해당 플랫폼에는 매일 5억개의 게시물이 등록된다. 그 중 사람이 컨텐츠를 유해 컨텐츠로 판별 할 수 있는 라벨링은 10000개이다. - 사용..
[system design] 유해 콘텐츠 감지
커뮤니티에 유해한 특정 사용자 행동, 활동 및 콘텐츠에 대한 유해한 콘텐츠와 악의적인 행위자를 식별할수 있는 시스템을 구축하는것을 목표로 하며 판별해야 할 데이터는 다음과 같다. - 유해한 콘텐츠 : 폭력, 노출, 자해, 혐오 발언등이 포함된 게시물 - 나쁜 행위/ 나쁜행위자 : 가짜 계정, 스팸, 피싱, 조직적인 비윤리적 활동 및 기타 안전하지 않은 행동 1. 요구사항 명확화 - 게시물의 콘텐츠는 텍스트, 이미지, 동영상 등이 있다. - 게시물을 등록한 사용자의 데이터가 있으며, 게시물에 대한 부가 정보도 포함되어 있다 (댓글/좋아요/싫어요/공유/신고수 등등) - 해당 플랫폼에는 매일 5억개의 게시물이 등록된다. 그 중 사람이 컨텐츠를 유해 컨텐츠로 판별 할 수 있는 라벨링은 10000개이다. - 사용..